2021.01.05
DeepCTR + FiBiNETというお手軽(?)なディープラーニングCTR予測モデル
ECサイトやインターネット広告事業を扱っているエンジニアの皆様であればClick Through Rate(以後CTR)の予測方法について色々悩まれることが多い方もいらっしゃるかと思います。
近年その選択肢の一つに挙げられるものの最右翼としてDeepLearningを用いた予測手法があります。DeepFMやWide&Deepなど多くの理論が展開されていますが、これらを一つ一つ論文を読み込み実装に落とし込むのは時間と手間がかかる作業であり、できれば避けたいところ。
そこで今回はDeepCTRというライブラリを使った実行方法を、FiBiNETという理論の紹介とともにご覧いただければと思います。
DeepCTRとは?
DeepCTRとは、Weichen Shenさんが開発したディープラーニングベースの各種CTRモデルを簡単にかつ使いやすく提供したPythonライブラリです。対象ライブラリはtf 1.x/tf 2.xとなっていますが、サブプロジェクトとしてPyTorch版(DeepCTR-Torch)も存在するため多くのMLエンジニアが利用可能なものとなっていますね
DeepCTRのページには下記モデルが実装されているとのことです(2021/1/4現在).
おなじみのDeep&WideやDeepFMだけではなく、FGCNNなどの新しい理論も実装されていますね。
今回はこの中から最も新しい理論の一つであるFiBiNETを解説し、これを使うためのコードを紹介いたします
- Convolutional Click Prediction Model
- Factorization-supported Neural Network
- Product-based Neural Network
- Wide & Deep
- DeepFM
- Piece-wise Linear Model
- Deep & Cross Network
- Attentional Factorization Machine
- Neural Factorization Machine
- xDeepFM
- AutoInt
- Deep Interest Network
- Deep Interest Evolution Network
- FwFM
- ONN
- FGCNN
- Deep Session Interest Network
- FiBiNET
- FLEN
- SENET Layer
- Bilinear-Interaction Layer
- Combination Layer
- Multiple Hidde Layers
FiBiNET
FiBiNETは、Weiboの研究者が発表したCTR予測モデルになります。FiBiNETは解きたいタスクによって重要になる特徴量を動的に判別し、重みをつけることを大きな目的としています。例えば人の収入を予測する際には、その人の趣味より職業や学歴、年齢の方が重要であることが想像できます。FiBiNETではSENETというメカニズムを導入することにより、動的に重要な特徴の重さを判別することが出来るようになったと考えられています
モデル概要
FiBiNETのモデル概要は以下の通りとなります。ここでは以下の4つ計算レイヤがあることを示しています
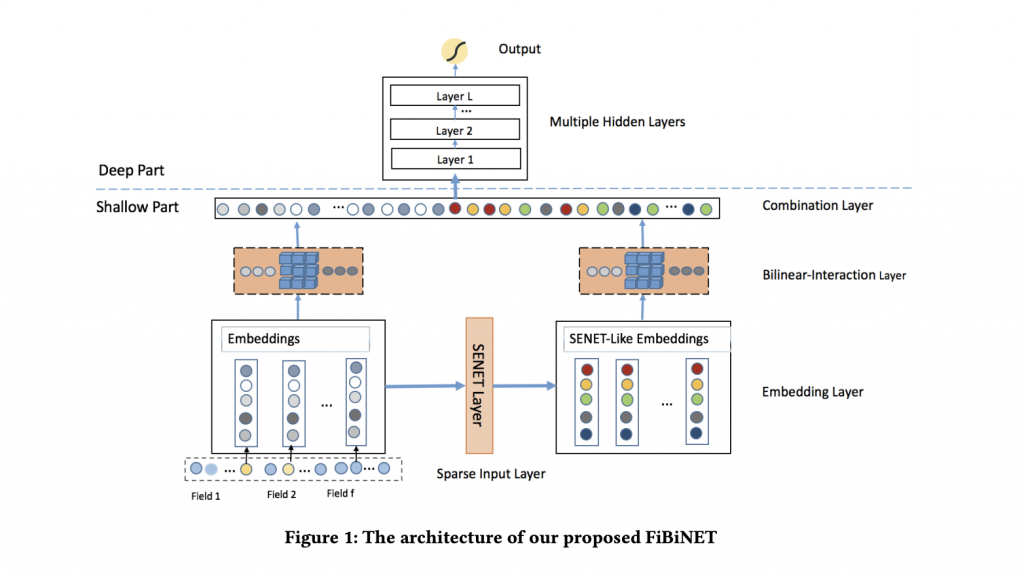
SENET Layer
SENET Layerは、動的に重要な特徴の重みをつけるための重要なLayerとなります.SENETには2つの全結合層(上と下の矢印)が存在しており、これが重要なものとそうでないものを振り分ける役目をしています
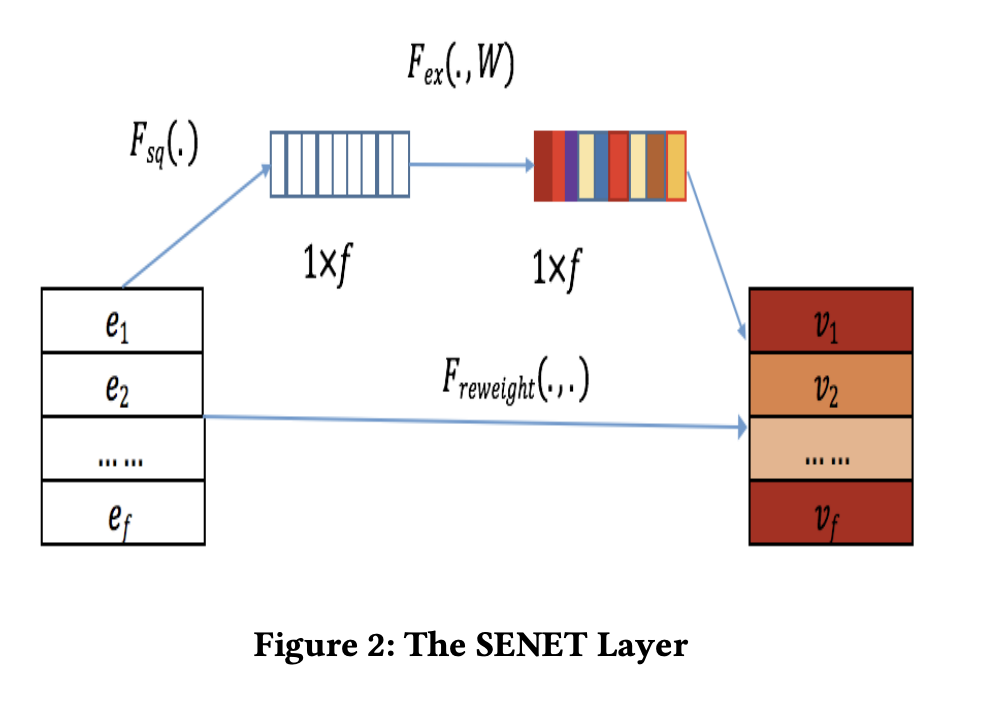
上の矢印ではまず全体的な特徴を掴むためGlobalAveragePoolingによるmean poolingを実施します。その後Weightをかけるのですが、reduction ratioというハイパパラメータ分だけ次元を小さく -> 大きくするという処理を実施します。縮小から伸張するといったイメージでしょうか。これにより重要な特徴量は大きな値を、あまり重要でない特徴量は小さいな値を持つようなVectorが作られるとのことです
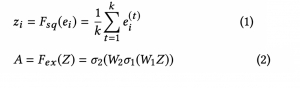
そして下の矢印ではこの重要度を持ったベクトルと、元のVectorを掛け合わせることにより元のVectorを補正しています。これによって重要度の高い特徴量のみが予測に使われるようになるというわけです
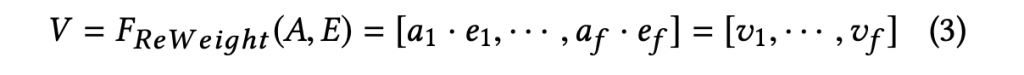
Bilinear-Interaction Layer
AFMやNFMでは内積やアダマール積をつかってfeature interactionを算出していますが、当手法ではBiliner-Interactionという形で算出しています。下記数式でわかるように通常のアダマール積にWeightをかけたものになっています。Weightの持ち方によって「Field-All Type」「Field-Each Type」「Field-Interaction Type」の3つが提案されており、タスクによって使い分けるようチューニングするようです。
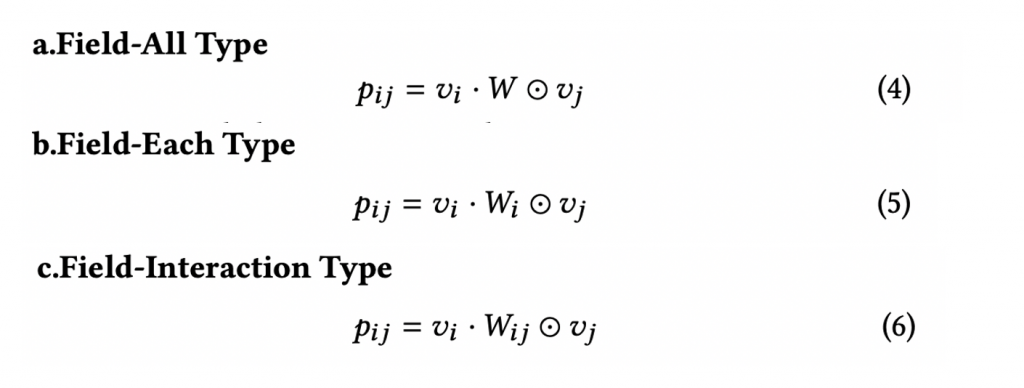
Combination Layer/Multiple Hidde Layers
ここまでくればあとは通常のDNNとほぼ同一です。Bilinear−Interaction Layerから出力されたVectorを連結し、Deep Neural Networkに投入して答えを得るといったことになります。前2つのLayerによって重要な特徴量が判別されており、これによってより効果の高いCTR予測が提供できるというわけです
DeepCTRによるソースコード例
さてここまでの解説や論文を読んでFiBiNETを使いたい!と思ったとしてもどう実装しましょうか?スクラッチでゼロからは骨が折れすぎますし、実装コードを探してきてもライセンスの問題やソースコードの複雑さなどでなかなかうまく行かないこともしばしば(多々)あります。そこで実用的な選択肢として上がってくるのがDeepCTRとなります。前述したとおりDeepCTRはこのようなモデルを非常に簡単に使えるようになっています。
ここではCriteoデータセットを利用したExampleを少し改修して、FiBiNETを使えるようにしたコードを御覧いただきましょう。Interfaceが統一化されているためモデルを入れ替えるだけで実行可能になっています。
sparse_features = ['C' + str(i) for i in range(1, 27)]
dense_features = ['I' + str(i) for i in range(1, 14)]
data[sparse_features] = data[sparse_features].fillna('-1', )
data[dense_features] = data[dense_features].fillna(0, )
target = ['label']
for feat in sparse_features:
lbe = LabelEncoder()
data[feat] = lbe.fit_transform(data[feat])
mms = MinMaxScaler(feature_range=(0, 1))
data[dense_features] = mms.fit_transform(data[dense_features])
fixlen_feature_columns = [SparseFeat(feat, vocabulary_size=data[feat].nunique(),embedding_dim=4)
for i,feat in enumerate(sparse_features)] + [DenseFeat(feat, 1,)
for feat in dense_features]
dnn_feature_columns = fixlen_feature_columns
linear_feature_columns = fixlen_feature_columns
feature_names = get_feature_names(linear_feature_columns + dnn_feature_columns)
train, test = train_test_split(data, test_size=0.2, random_state=2020)
train_model_input = {name:train[name] for name in feature_names}
test_model_input = {name:test[name] for name in feature_names}
# ModelをDeepFMからFiBiNETに変更するだけで実行可能
#model = DeepFM(linear_feature_columns, dnn_feature_columns, task='binary')
model = FiBiNET(linear_feature_columns, dnn_feature_columns, task='binary')
model.compile("adam", "binary_crossentropy", metrics=['binary_crossentropy'], )
history = model.fit(train_model_input, train[target].values, batch_size=256, epochs=10, verbose=2, validation_split=0.2, )
pred_ans = model.predict(test_model_input, batch_size=256)
print("test LogLoss", round(log_loss(test[target].values, pred_ans), 4))
print("test AUC", round(roc_auc_score(test[target].values, pred_ans), 4))
※https://deepctr-doc.readthedocs.io/en/latest/Examples.htmlを利用し、一部改修
最後に
ほぼほぼFiBiNETの紹介にはなってしまいましたが、これだけ複雑なモデルを統一的なInteraceを用いて利用できるということがDeepCTRの利点の一つかと思います。
前処理やFeature Storeの構築にも工数がかかる中モデルをいち早く簡単に使ってみたいというニーズにはあうかと思いますので、是非触ってみていただけると良いのかなと思います
次世システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧からご応募をお願いします。
一緒に勉強しながら楽しく働きたい方のご応募をお待ちしております。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD