2021.04.05
エッジAI(Jetson Nano 2GB)でTensorRTを用いて推論高速化をしてみました
こんにちは。次世代システム研究室のK.S.(女性、外国人)です。
今回はエッジAI(Jetson Nano 2GB)で遊んでみた話を続けます。前回のブログではお試しにJetson Nano 2GBでNVIDIAのHello AI Worldを使って物体をリアルタイム認識してみました。本四半期(2021Q1)はもう少し詳しく手を動かして実装します。主に、Jetsonの計算を高速化するためのNVIDIA TensorRTという高性能の深層学習推論について勉強してきたことを共有させて頂きたいと思います。また、今回はエッジAIをご理解頂いている前提で書いていますので、エッジAIについては前回のブログを参考にしてください。加えて、推論実験のスピードテストのための写真にも沢山の桜を使用し、最後のところでは生田緑地の見晴らしの良い丘でのリアルタイム認識スピード実験も共有します。
TL;DR(要約)
- NVIDIA TensorRTは学習モデルを最適化し、処理を高速化するための推論のソフトウェア開発キットです。
- TensorflowやPyTorchベースの画像認識の学習済みモデルからをTF-TRTやtorch2trtといった様々な方法で推論モデルに変換し、桜などの写真の推論スピードを比較してみました。結果はtorch2trt経由のTensorRTモデルが一番優秀でした。(早速の結果はこちら)
- 実用的に、OpenCVとPyTorchの組み合わせで、生田緑地の見晴らしのいいところでリアルタイム認識をテストし、TensorRTを使った時の方が推論のスピードが30倍くらい早くなったことを確認できました。
1. 機械学習モデルの高速推論
まず、そもそも機械学習パイプライン(プロセス)とは具体的にどのようなものなのかを少し復習します。その後、学習モデルの高速推論について、どのようなものがあるのかを軽くまとめます。
機械学習パイプライン
一般的な機械学習のパイプライン(下記の図)はデータ取得から、データの前処理、特徴抽出、モデル学習(学習、適合、検証)、デプロイ(使える状態にする)、推論とマイクロサービス化(アプリケーションに小さなサービスを組み合わせる)までを行ってから、ようやくサービスとして顧客に提供できるようになります。
モデル学習までにはビックデータの扱いやモデル精度の向上のために高性能なコンピューティング環境が必要で、クラウドや高性能サーバーがよく使われています。顧客に提供するときに、システムの負荷や通信遅延を解除するためには、ユーザーの端末の近くにあるサーバーで処理するようなエッジコンピューティングが望ましいです。また、より安定的なサービス提供のため、デプロイされたモデルの推論処理は高速化が必要となります。モデル推論が遅くなれば、ユーザの待ち時間が長くなり、ユーザー体験を損ねてしまいます。例えば、オンラインショッピングの顧客の62%はウェブページの更新のために待てる時間は5秒以内だけだそうです。買い物を推奨する機械学習モデルの処理時間が長すぎると、顧客がイライラしてしまう可能性があります。
では、推論稼働時間のパフォーマンスはどうやって向上できるのか
学習モデルの高速推論
学習モデルの高速推論の推論稼働時間(inference run times)はhardwardとsoftwareの視点に分けて考えられます。hardwareはCPUs, GPUs, FPGA, ASICsなどで性能が異なります。それに合わせて、いくつかのsoftwareも提供されています。よく知られているのは
Apple CoreML、Intel OpenVINO、NVIDIA TensorRT、Qualcomm SNPE、TF-Lite、ONNX Runtimeです。
今回はNVIDIA社のJetson Nano 2GBを利用していますので、TensorRTを試すことになります。それでは、具体的に、TensorRTは何ができるのかを説明します
2. NVIDIA TensorRTとは
TensorRTはディープラーニングモデルの推論を高速化するためのソフトウェア開発キット(Software Development Kit; SDK)です。NVIDIA社が提供しているTensorRTはディープラーニング推論の最適化と稼働(optimiser and runtime)に短時間と高能力で処理(low latency and high throughput)できるようにするものです。上記に説明したように、学習済モデルは沢山のデータを利用し、柔軟性や精度を高めるための学習を完了したものです。結果、モデルは非常に複雑なネットワークになり、処理時間もかかってしまいます。TensorRTで、そのモデルを最適化し処理を高速化することができます。NVIDIA社のサイトによる、TensorRTのアプリは通常のCPUプラットフォームより40倍早く推論処理できるようです。
TensorRTのワークフローは主な2つのステップに分けられます。ステップ①は学習済みモデルを最適化します。ステップ②は最適化されたモデルをデプロイします。具体的に、この二つのステップは何をするのかNVIDIAの資料を参考にしながら説明します。
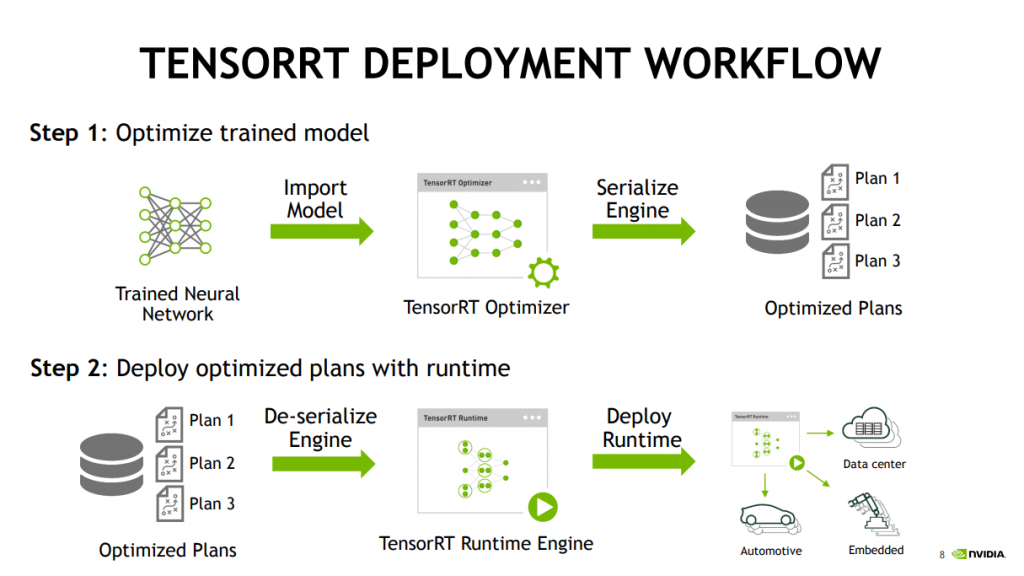
ステップ①学習済みモデルの最適化について、学習済みモデルはTensortflowやPyTorchといった様々なフォーマットがあります。それらのモデルはTensorRT Optimizerの処理を通して、Optimized Plans(Optimized Inference Engine)を作ります。TensorRTのモデルはplanファイルになっています。ステップ②最適化されたモデルのデプロイについて、CUDA(PyCUDA)を使います。CUDAはNVIDIA社が提供しているGPU向けの並立コンピューティングプラットフォームです。
具体的に、TensorRT Optimizerは下記の処理を最適化し推論を高速化します。
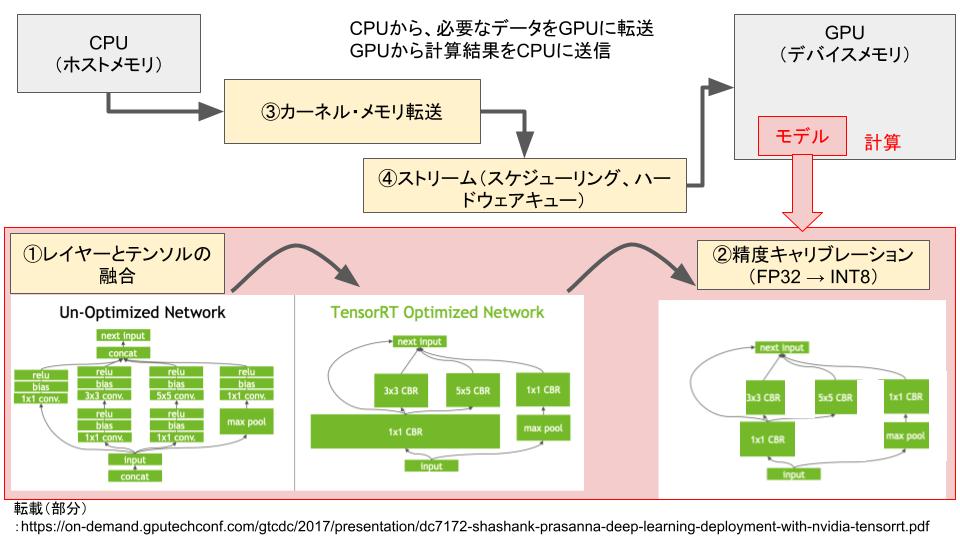
- レイヤー(Layer)とテンソル(Tensor)の融合
- 重み(Weight)&アクティベーション(Activation)の精度キャリブレーション
- カーネルの自動調整(Kernel Auto-Tuning)
- マルチストリーム実行(Multi-Stream Execution)
- 動的テンソルメモリ(Dynamic Tensor Memory)
- タイムフュージョン(Time Fusion)
カーネル内のノードを融合することにより、GPUメモリと帯域幅の使用を最適化します。例えば、複数のレイヤ「relu+bias+1×1 conv.」を一つのレイヤー「3×3 CBR」に結合し、Layer数を減らすことが可能になります。
精度を維持しながらモデルをINT8に量子化することにより、FP32に比べてモデルサイズやメモリ使用量の削減でき、処理を効率化することが可能になります。例えば、FP32、FP16、INT8のdynamic rangeは「-3.4x10e38 〜 +3.4x10e38」、「-65504 〜 +65504」、「-128 〜 +127」になり、情報量を減らすことで、スピードアップも可能になります。しかし、INT8のように大幅に減らすと精度に影響を与える可能性があるので、少しチューニングが必要です。TensorRTはそのチューニングを自動的にやってくれます。
カーネルはOSの中核にあるもので、ハードウェア(CPU、GPU、メモリなど)とのやりとりを請け合って、いくつかのソフトウェアの仕事を調整します。TensorRTはターゲットGPUプラットフォームに基づいて最適なデータレイヤーとアルゴリズムを選択します。それに合わせて、チューニングされたカーネルを利用することで、処理が早くなります。
複数の入力ストリーム(cudastreams)を並行して処理するための実行を最適化します。
メモリフットプリントを最小限に抑え、テンソルのメモリを効率的に再利用します
動的に生成されたカーネルを使用して、タイムステップにわたってリカレントニューラルネットワークを最適化します
それでは、様々な環境で実際にどうやってTensorRTが適用できるのかを試してみます
3. 実装
いよいよ、実装です。
やりたいことは画像分類Resnet50学習済みモデル(TensorflowとPyTorchのもの)を利用し、TensorRTの形に変換します。変換前後のモデルを使った時のスピードを比較します。かつ、実用的な雰囲気を捕まえるため、生田緑地でリアルタイム認識のスピードも実験します。詳細のコードはgithubを参考にしてください。
準備
実装機械
Benchmarkのため、Google Colaboratoryを利用しましたが、本番のデバイス(端末)はJetson Nano 2GBです。前回のブログの追加で、モニターとSDメモリーを購入しました。技術検証という理由で、GMOのスキルアップ補助制度「学ぼうぜ!」の支援で購入費用の50%をサポートして頂きました。ありがとうございました。それでは、実験セットは下記になります。セットアップについては前回のブログを参考にしてください。ちなみに、前回は32GB SD cardを使いましたが、今回は64GB SD cardを使いました。Jetson nanoのメモリーは2GBしかないですが、swap memory設定のおかげで、CPU利用時ははメモリーが余裕になりますが、GPUには適用できないです。

また、開発の環境の好みですが、jetson nanoにsshして開発したい場合、ファイアウォールの設定は下記になります。
# set up ssh to jetson nano sudo apt-get install ufw openssh-server sudo ufw allow openssh sudo ufw disable sudo ufw enable sudo ufw status
開発環境
JetsonシーリズはARM系の省電力統合型プロセッサを利用しています。それらのJetsonボードを使用するため、Linux for Tegra(Linux4Tegra, L4T)といったGNU/Linuxベースのシステムソフトウェアが必要となります。それに合わせて、今回のJetson Nanoでの実装環境はNVIDIA L4T 用のdocker container「NVIDIA L4T TensorFlowとNVIDIA L4T ML」を使用しました。また、インストールの際、バーションは「cat /etc/nv_tegra_release又はsudo apt-cache show nvidia-jetpack」でチェックでき、今回は「R32 (release), REVISION: 4.4」ですので、最新版のcontainersではなく、tegraバーションに合わせて「JetPack 4.4.1 (L4T R32.4.4)」を利用しました。
また、benchmarkのためのGoogle Colaboratoryの環境も確認しておきました(20210327時点)。
Ubuntu 18.04.5 LTS \n \l CUDA Version 11.0.228 Linux d7d94d2f0dd2 4.19.112+ #1 SMP Thu Jul 23 08:00:38 PDT 2020 x86_64 x86_64 x86_64 GNU/Linux Tensorflow version: 2.4.1 Torch version: 1.8.1+cu101
NVIDIA L4T ML containerのセットアップ
このcontainerはPyTorchの実装のためのものです。実はPyTorch用のcontainerもありますが、ML用のcontainerの方が様々なlibraryが入っていますので、これを使います。また、リアルタイム認識のためのopencv libraryとtorch2trtも使いたいので、それらのlibraryをinstallし、docker containerのimageを更新しました。環境構築はここです。
NVIDIA L4T TensorFlow containerのセットアップ
Tensorflowのモデルをテストするため、Tensorflow環境を設定しました。実はNVIDIA L4T MLのcontainerにもTensorflowが入っていますが、Tensorflow1系になっています。今回は2系を使いたいので、このcontainerを使用しました。Jupyter notebookをインストールすることも可能性ですが、Jetson Nanoのメモリは2GBですので、使う際に少し反応が遅くなり、個人的には扱いにくいです。環境構築はここです
学習済みモデルとラベル
モデルは学習済みResnet50を使いました。ラベルはimagenet 1000 classになります。
データ準備
データはインターネットから、好きな画像をダウンロードしました「download_images.pyを参照」。今回の実験には関係ないですが、モデルは本物と偽物をどう認識しているかに少し興味があるので、本物の画像とポケモンの画像を利用しました。また、折角なので、季節に合わせて二ヶ領用水の近くで撮影してきた本物の桜とサクラポケモン(チェリム)も試してみました。ということで、今回スピード比較のために、使った写真は下記の20枚になります。

これらの画像を使って、Google Colaboratory経由で画像処理を実行し、モデル精度も軽く確認してみました。画像処理について、処理のやり方が少し異なるため、モデルに入力するための画像は少し違います。Tensorflowからの学習済みやPyTorchからの学習済みモデル(Resnet50)を使って、推論の結果が合っているかを目視しました。なんと、TensorflowでもPyTorchでも、本物の画像(猫やクラゲなど)はちゃんと特定できましたが、ポケモンちゃんたちの画像は変な推論になってしまいました。また、自分が撮影してきた本物の桜もサクラポケモンもうまく特定できませんでした。ということで、今回の前提は精度抜きで、スピード中心の実験を行うことにしました。


ところで、本題に関係ないですが、個人的にはチェリムの推論結果はちょっと面白かったです。Tensorflowの場合は全体の画像をresizeし、そのまま使いましたが、PyTorchの場合は、resizeして、さらに中心を切り取りました。結果、Tensorflowはチェリムの後ろにあるセイヨウアブラナを特定しました。PyTorchはチェリムを特定しましたが、チェリムが風車と似ていたため、風車として特定しました。自分はチェリムとセイヨウアブラナを一緒に撮りたかったので、どちらが正しいかというと、チェリムとセイヨウアブラナという結果が欲しかったです。これはmulti-label classification案件になりますね。
ここまでで準備完了です
3.1. TensorRTへの変換モデルのスピード比較
やりたいことはTensorflowやPyTorchからの学習済みモデルをスピードアップしてみることです。今回の主な実装は2つの有名な機械学習フレームワーク(TensorflowとPyTorch)で試します。
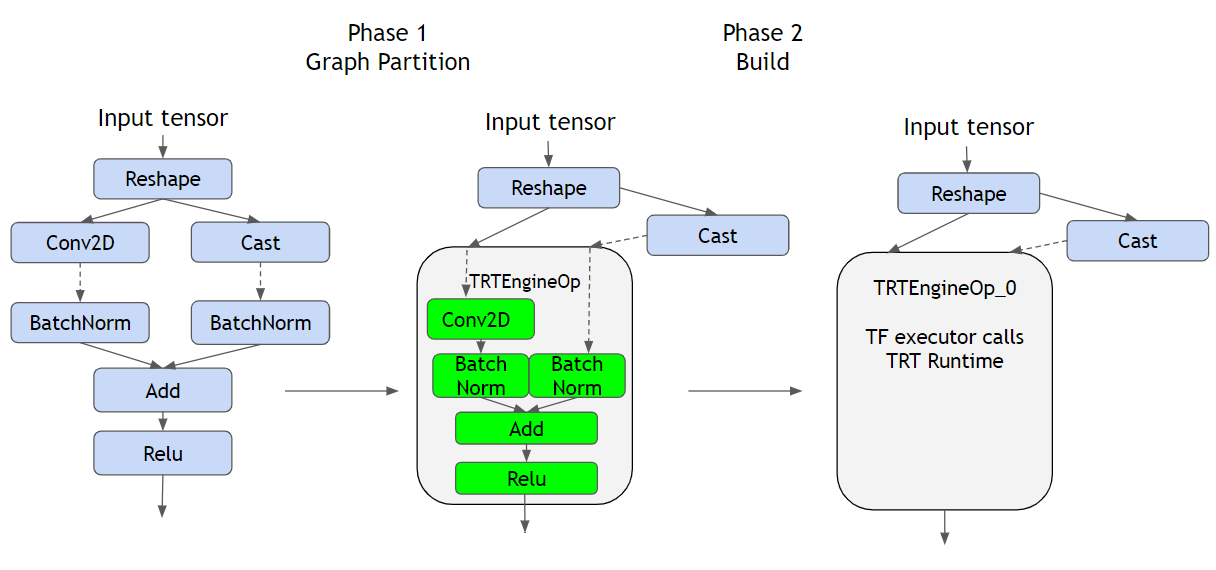
Tensorflowの場合はTensorFlowとTensorRTが統合したTensorFlow-TensorRT (TF-TRT)を試しました。TF-TRTはTensorflowのフレームワークでNVIDIA GPUsの推論最適化を高速化するためのものです。やり方としては主な二つのステップ(下記の図)があります。まず、TensorRTがサポートしているグラフをTRTEngineOpに包み込みます。続けて、TRTEngineOpごとにTensorRT engineが構築され、実行できる状態になります。
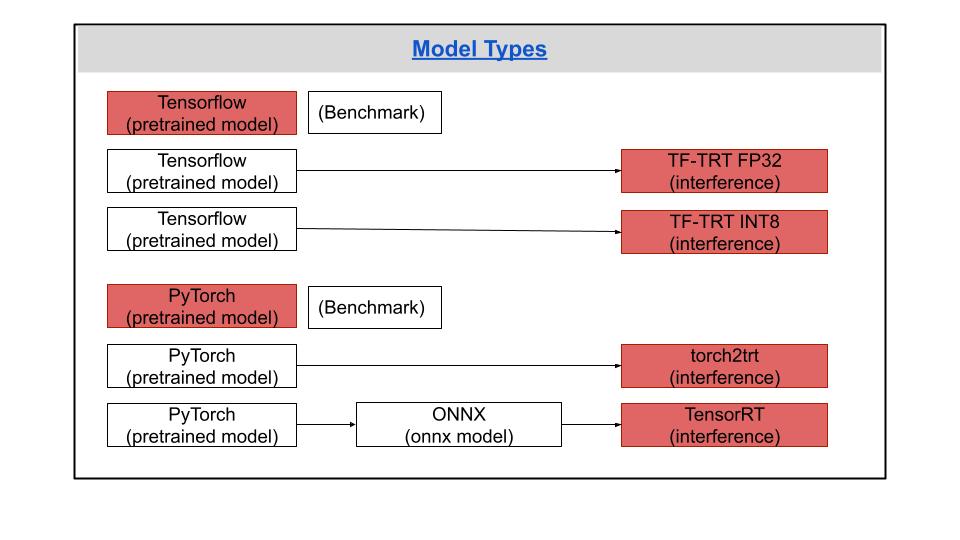
PyTorchの場合は二つの方法を試します。最初に、torch2trtを使ってPyTorchベースの学習済みモデルをTensorRTに変換します。やり方はかなり簡単で一つの関数でPyTorchをTensorRTに変換してくれます。次に、ONNX経由で直接にPyTorchベースの学習済みモデルをTensorRTモデルを変換します。下記のような実装が必要となります。
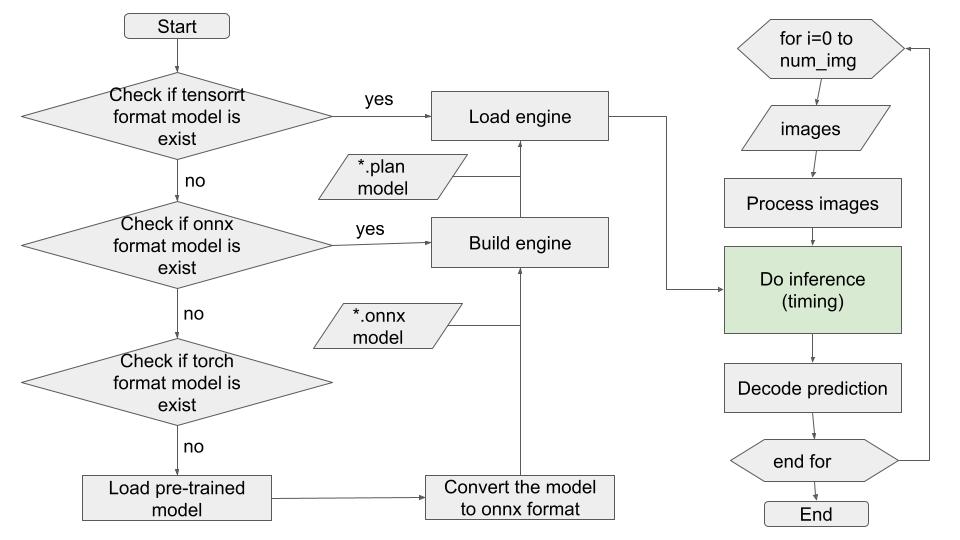
実装
実装コードは長いので、githubを参考にしてください。主な3つの実行ファイルになり、pytorchとtorch2trt用(compare_tensorrt_pytorch.py)、tensorflowとTF-TRT用(compare_tensorrt_tensorflow.py)、TensorRT用(compare_tensorrt_native.py)です。また、TensorFlow with TensorRT (tf-trt)とtorch2trtのTutorialも結構充実していますので、ご参考になるかと思います。
結果
評価指標のため、一枚ごとの推論スピードを測りました。下記のような感じで、画像ごとの推論スピードはバラつきが見られたため、今回のSpeed(ms)評価は20画像の推論時間の中央値を使うことにしました。
結果は下記の表になります。まず、benchmarkとして、Google ColaboratoryでTensorflowとPyTorchの学習済みモデルの推論スピードを測ってみました(case A and E)。結果、まだTensorRTを使わなくても、PyTorchの学習済みモデルの方が推論スピード6倍くらい早かったです。次に、TensorflowモデルをTF -TRTに変換してみました。上記の精度キャリブレーションの説明のように、precisionの最適化することで、スピードアップすることができるようで、float and integer(FP32, FP16, INT8)に試しました。確かに、4-5倍くらい早くなりました。しかし、まだPyTorchに勝っていなかったので、Jetson Nano 2GBにではPyTorchベースのみで実験しました。
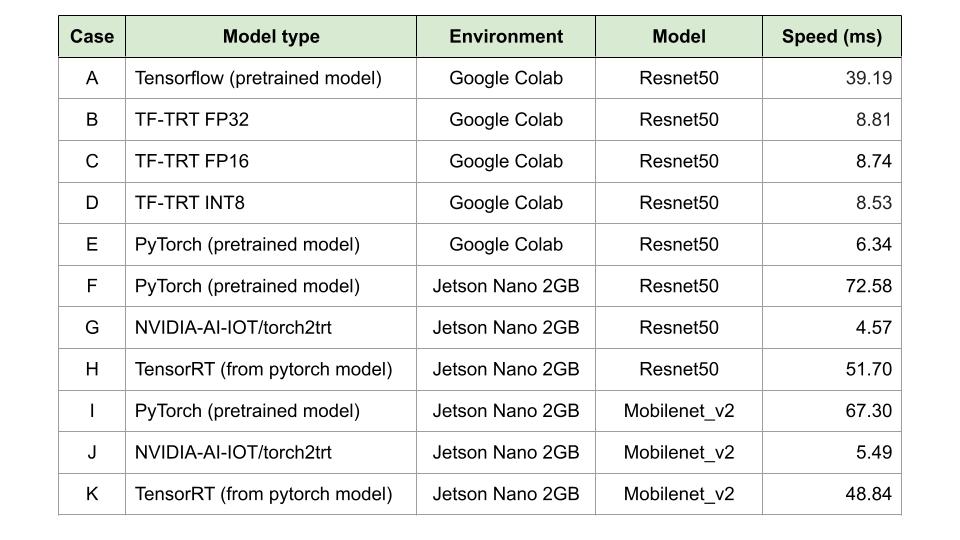
Jetson Nanoでのテスト結果によると、torch2trtを使うことで、推論スピードが15倍くらい、ONNX経由は1.4倍くらい早くなりました。実は、同じくらい早くなるはずでしたが、自分が実装したTensorRTのパラメーターはまだチューニングしていなく、その辺の改善余地があるのではないかと思います。
最後に、Resnet50モデルではなく、Mobilenet_v2も試してみましたが、似たような結果を再現できることが確認できました。
3-2. 生田緑地での画像リアルタイム認識のスピードアップ実験
ようやく、個人的な楽しみです(半遊びの自己満足)。生田緑地でのリアルタイム認識のスピードアップ実験を開始します。今回も名乗るほどの者ではない方の運搬と撮影のご協力を頂き感謝します。それでは、出発で〜す。Jetson Nano 2GBを生田緑地までに運びます(運べ、運べ、を歌えながら、移動しま〜す)。実は梅を撮影する予定でしたが、梅園の梅はもう散ってしまったので、場所を変更しました。母の塔の近くの見晴らしのいい丘にJetson Nano実験をセットアップしました。(余談ですが、セットアップが終わった途端、後ろに子供さんたちが遊んでいたボールがJetsonちゃんの近くまで飛んできて、Jetsonちゃんが壊れるところでした、笑)。それでは、準備万端で、機械を起動します。監察官も三匹いますので、慎重に撮影します。

実験
実験は上記に検証したPyTorchの学習済みモデルとtorch2trtでTensorRTに変換したモデルを使用し、リアルタイムで物体認識します。主なコードは下記になりますが、詳細は「run_realtime_videocapture.py」を参考してください。
実験手順としては、モニターをシェアし、docker containerを立ち上げて、実行するだけです。
# give an access to server from all host (for sharing display) xhost + # start l4t-ml + cv2 + torch2trt container docker run -it --rm --gpus all --runtime nvidia --network host -v /home/ks/Documents:/mnt/ml --device /dev/video0 l4t-ml-cv-trt:latest # run real-time video capture # For PyTorch model python3 run_realtime_videocapture.py -case "torch" # For torch2trt model python3 run_realtime_videocapture.py -case "torch2trt"
実行後、カメラをあっちこっちに動かしながら、観察していました。
結果
当たり前の結果になりますが、上記の結果と同じくtorch2trtでTensorRT変換したモデルの方がPyTorchの学習済みモデルより、推論が早かったです。そのおかげで、動きがガタガタせず、リアルタイム認識が早くなるように見えます。正確ではないですが、撮影したビデオによると、一つのframeの認識で、torch2trtのTensorRTモデルは10ms前後で、PyTorchの学習済みは300ms前後でした。30倍くらい早くなりました。
torch2trtでTensorRT変換したモデルのリアルタイム認識
PyTorchの学習済みモデルのリアルタイム認識
4. まとめと考察
今回はTensorRTを紹介しました。予想通りに、学習済みモデルを使って、TensorRTに変換したモデルは推論をスピードアップすることが確認できました。実用的にも生田緑地でのリアルタイム認識のスピードアップの可能性を感じました。
最後に
次世代システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧からご応募をお願いします。
一緒に勉強しながら楽しく働きたい方のご応募をお待ちしております。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD