2017.07.10
狙え一攫千金!-コンピューターにニュースを読ませFXの予測をさせた-
お金が欲しいですか?
私は欲しいです。
お金があれば、都市からちょっと離れたところに家と畑を耕す土地を買い、朝から夕方まで家庭菜園、料理、その他の趣味に勤しむ。毎日野菜の育ち具合や、料理の出来、不出来に一喜一憂はするが、締め切りもノルマもない。出来たものが美味しければご近所に振る舞う。喜んでもらえればそれが何よりのご褒美。
家に水漏れや電気の問題があれば、水道管ゲームや電子工作の延長と考え、楽しみながら自分でなおす。近所が物騒だと思えば、玄関にウェブカメを設置し、ディープラーニングで顔、指紋、声認証セキュリティシステムを自分で実装してしまう。それでも暇ならば、適当な中古車にパワフルなモーターを搭載し、自家製電気自動車を作っちゃう。
それでも時間が余れば丸太を仕入れてきてログハウスを建てる!
質素(?)だけどストレスフリーなそんな生活が、10億円ぐらいあれば何も心配なくずーーーっと続ける事ができる。
そんな生活したくありませんか?
え、私だけ?
それはともかく、日本のしがないサラリーマンの平均程度の収入では、そういう資産は、
いつまで経っても、
未来永劫、
永遠に、
貯まりやしないっ!!!
人生は短い。私は悲しい。
しかし、世の中には投資というものがあります。投資家の中には異常とも思える勝ち方をする方がいて、億とか平気で稼いだりしてます。どの世界もトッププレーヤーは圧倒的な強さを持っているもので、つまり投資の世界で圧倒的一番にさえなれば夢のDIY隠居生活に必要な資産がすぐに貯まるのです。
圧倒的 “一番” になる。
誓ったじゃないか、スピリットベンチャー宣言。
ならば私は、最新技術を駆使して投資で勝つ。そんな訳で、今回はGK(次世代システム研究室)が自然言語処理を利用したFX相場の予測に挑戦します。
1. FX相場とニュースの関係について
FXは外貨の売買をインターネット上で手軽に行う事ができるサービスです。例えば日本円で米ドル、ユーロ、ポンドや他にも色々な外貨を買う事ができます。FXで稼ぐには、為替相場の変動を見極め、安くて買って高く売るなどして利益を出します。相場が大きく上がる直前に買い注文を沢山入れた人は、高く売る事ができるためウハウハです。想像してみてください、FXの相場を当てて短時間で大金を手に入れました。そのお金をあなたは何に使いますか?海外旅行に出かけますか?それとも車を買いますか?家のローンの返済もいいかもしれません。あるいは夜の街に出かけて散財してしまうのもあり。仕事やめてアイドルの追っかけ専業になってもよし。なんなら全部貯金しても問題無し。夢が広がりますね。ただし注意してください、皆さま。大儲けの可能性があると言うことは当然大損の可能性もあるんです。値上がり直前に売り注文を入れてしまった人はトホホ状態になってしまいます。
だから!
DA!KA!!RA!!!
そういう大変な目にあってしまわないように、是非この記事を読んで、賢いFX投資について勉強していただきたいのです。ではどのようにして私たちは投資行動を決めるべきでしょうか?FXでは外貨を売買する訳ですから当然海外の時事情報が重要であり、情報源としてはニュースが適していそうです。為替相場とニュースの相関性について考えると、最近の事例だとトランプ相場やブレグジットショックなどが挙げられます。トランプ相場では、昨年11月9日に米大統領選挙の結果が報道されるやいなや米ドル価格が急降下したものの、その後トランプ大統領の演説が始まると、それから1ヶ月も続く力強い上昇を始めました。またブレグジットショックでは、昨年6月の国民投票により、英国のEU離脱派が勝利したという報道の直後にはポンド価格が大幅に下がり、その後現在までポンド安が続いています。このように、政治経済の重要出来事は外貨の相場に対する影響が大変大きいため、もしニュースの内容とその為替相場への影響を機械学習モデル化できれば、これを用いた相場予測による投資が可能となるのです。
2. 実験ステップ1 -ニュースタイトルのベクトル化-
そこで、今回はDoc2vec というアルゴリズムを使ってニュースのテキストデータをベクトル化する事で、機械学習モデルで処理を可能にしました。Doc2vecは自然言語のドキュメントをベクトルにするためのアルゴリズムですから、当然ニュースのテキストもベクトルに出来ます。しかし、そもそも文書や言葉は基本的にはあまり数字とは関係ないにも関わらず、それを数字の塊であるベクトルに変換してしまうのはなんとも不思議です。そんな事を一体どうやってやるんだろう?と皆様も思うかもしれません。Doc2vecを理解するためにはまずその前に作られたWord2vecについて理解する必要があります。
2.1 Word2vec
Word2vecは、ある文章の集まりの中に含まれる単語一つ一つをベクトルで表現します。Word2vecには異なるアルゴリズムがいくつかありますが、その中の一つであるCBOWについて、まずは説明したいと思います。CBOWというアルゴリズムは、まず文書の集まりからその一部分を切り取って、その「文書の破片」の中で注目する一つの語を特定する事が出発点となります。この注目する一語を “word” と呼び、元の文書の集まりをコーパスと言います。よくコーパスとして用いられる文書にはWikipediaやオンラインの映画レビューなどがありすが、それは最初からデジタルなテキストとしてインターネットにあるから便利なためで、ようはどんな文書でも良いのです。「文書の破片」の切り出し方によってコーパス中のあらゆる語が word となりますが、Word2vecの目的はコーパスに含まれる全てのword、つまり含まれる全ての語彙を適切なワードベクトルで表す事と言えます。例えばある二つの word があったとして、これらが同じような意味を持ち、したがって同じような文脈で現れ、かつコーパス中の出現頻度が近ければ、それらの word のワードベクトルは同じような向きと大きさを持ったワードベクトルとなる事が、よくトレーニングされたモデルにおいては期待できます。反対に、二つの word の意味に関連性が無かったり、word が現れる文脈が異なれば、ワードベクトルの向きは異なる事が期待できます。
ところでモデルのトレーニングだなんて、なんだか聞きなれない感じがしますが、一体どういう意味でしょう?人工知能を搭載したロボットに腕立て伏せでもさせるんでしょうか?筋トレしても人間と違い筋繊維が太くなるわけではないですし、謎ですね。実はそんなに難しく考える必要はありません。皆さんもエクセルは使ったことがあると思いますが、エクセルで線形回帰などの回帰分析ができますね。あれは便利なもので、散布図で表したデータのモデルとして直線を引くのに、人間がえいやっと線を引くのは信頼性に欠けるので、コンピューターに数学を駆使して最適な直線をササっと引かせているのです。このモデルの直線の最適化のプロセスが、実は機械学習の用語でいうトレーニングにあたります。乱暴に言ってしまえば、線形回帰もWord2vec のトレーニングも本質的には同じなのです。
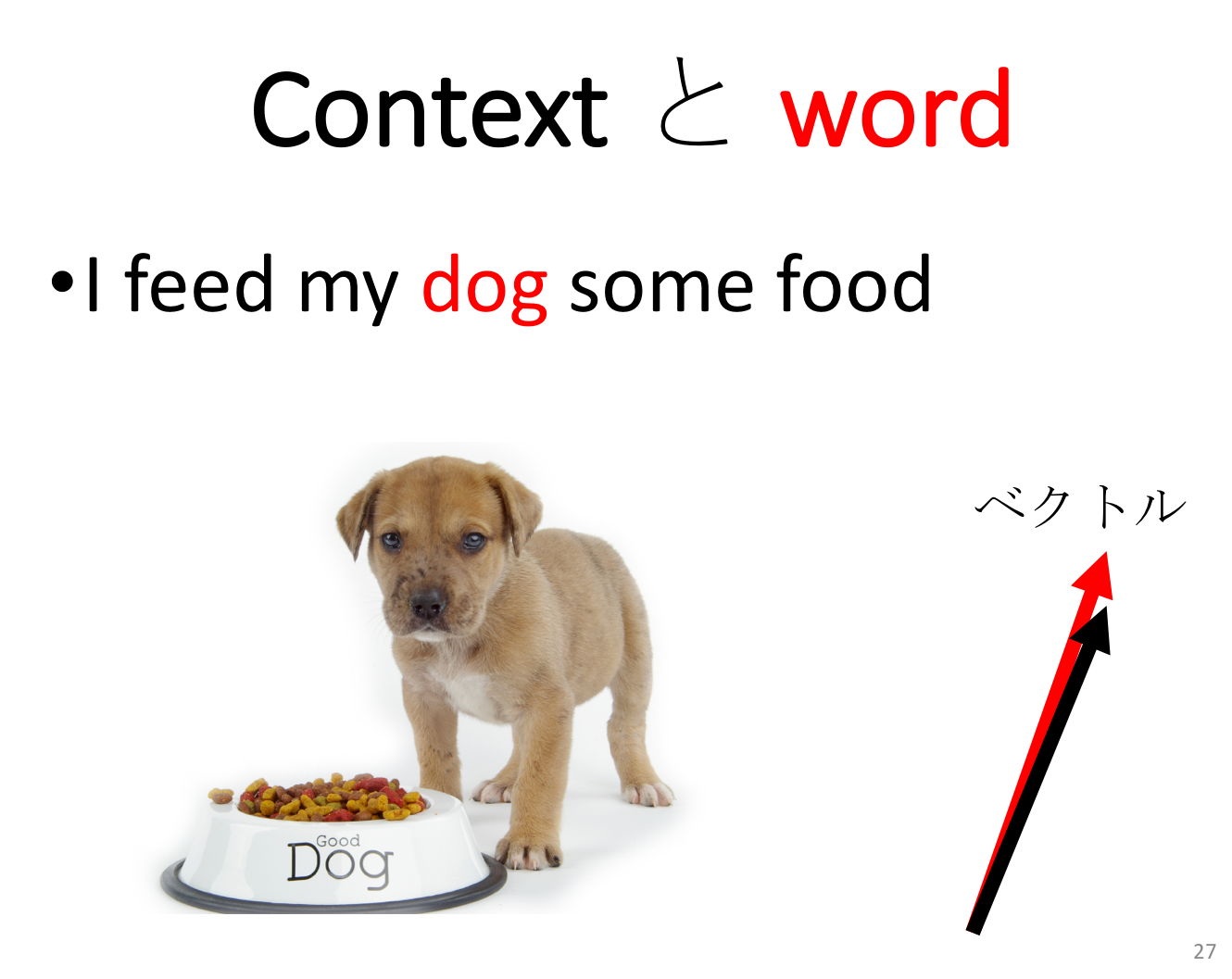
話を戻しますが、具体例として仮にコーパスのなかに “I feed my dog some food”という「文章の破片」があり、”dog” が注目する語である word だとします。この ”dog” というwordの性質はどのようにして求められのでしょうか?実はCBOWでは、”dog” そのものには注目せず、むしろ “dog” のまわりに現れる語に注目し、”dog” の性質を導きだします。word の周りにある語の集まりは “context” と呼ばれ、word がベクトルで表されるのと同様に context もベクトルで表されます。もしコーパスの中に” I feed my dog some food “に似た文章がいくつもあれば、word である ”dog” のワードベクトルと context である ” I feed my _ some food “ のコンテキストベクトルは、モデルのトレーニングの結果、その向きが近くなる事が期待できます。
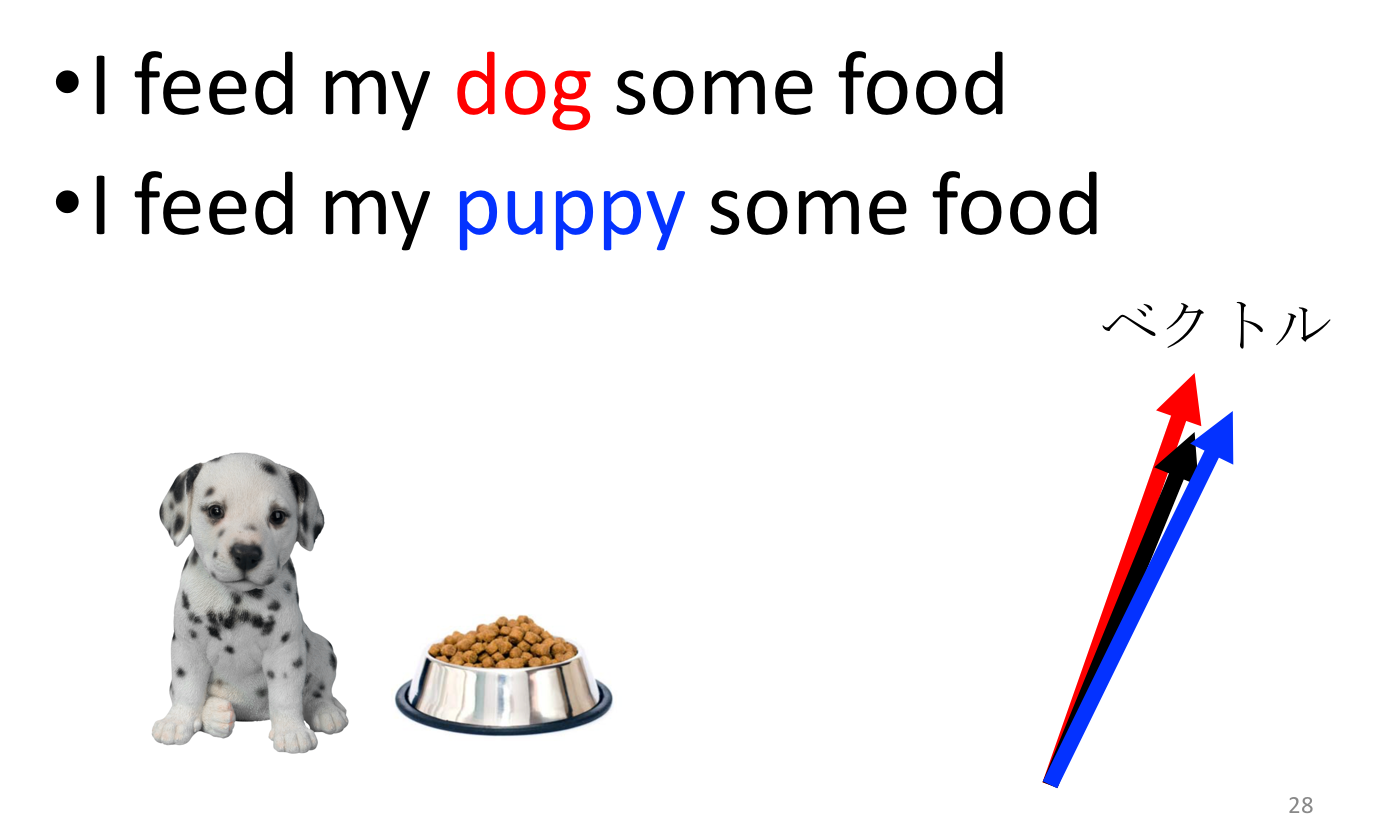
さらに、dog に似た語には puppy (子犬)が考えられますが、“puppy” というword と ” I feed my _ some food “ という context もやはりベクトルの向きが近くなると考えられます(がそれはコーパスに依ります)。その結果、”dog” と “puppy” のワードベクトルは、その大きさや向きが近いと期待できるというわけです。”I feed my puppy some food” は文章として意味が通じますし、dog について沢山描いてあるコーパスであれば きっとpuppy についても沢山書いているだろうと期待できるわけですから、”dog” も ”puppy” も ” I feed my _ some food “ に対して同様な対応関係になっているというのは、直感的にも理解しやすいですね。
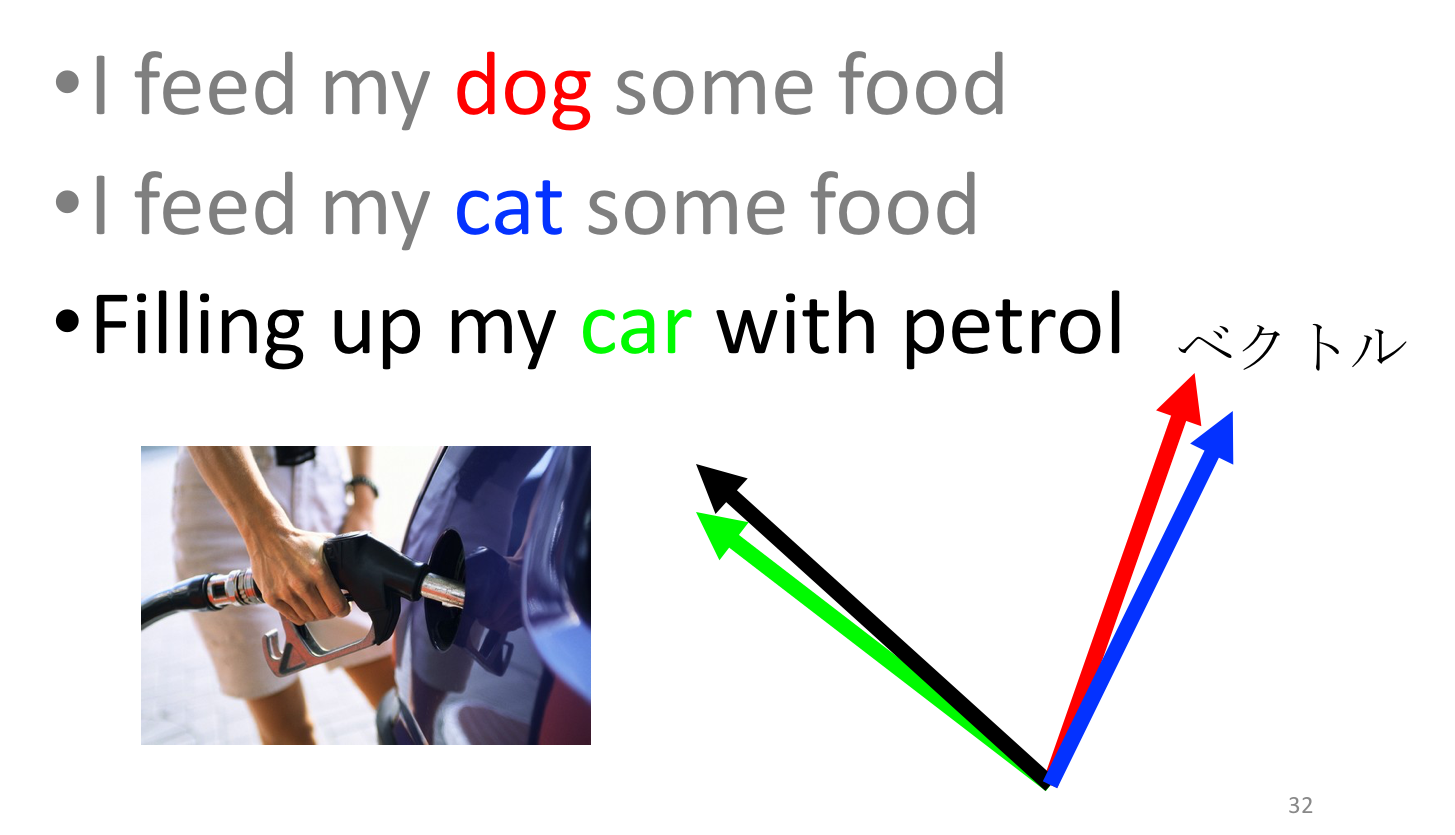
反対に、”car” という word を考える場合、車は食べ物でなく燃料を補給するわけですから” I feed my _ some food “ のコンテキストベクトルと揃っているとは考えにくく、結果として”dog” や “puppy” とは違う向きを持ったワードベクトルになっている事が期待できます。
このように、Wors2vec を用いれば言葉の類似性をベクトルを用いて表す事が出来ます。かなり単純化した説明ですが、大体こんな感じだと考えておけば Word2vec の概観はつかめたと言えるのではないでしょうか。より詳しく知りたい方は、こんな論文やこんな論文を読むと良いと思います。
2.2 Doc2vec
それでは以上を踏まえてDoc2vecではニュースなどのドキュメントをどのようにしてベクトルで表現するかについて考えてみます。Doc2vecにもやはりいくつかアルゴリズムがありますが、今回は PV-DM というアルゴリズムについて説明します 。word をベクトルで表現する方法は上の説明でいくらかわかって頂けたと思いますが、word は単なる一つの語でしかないためベクトル化はそこまで難しくなさそうな印象を受けるかもしれません。反面、沢山の語や文を含む Document をベクトルをにするのはそれよりももっと大変そうにおもえますね。ところがそうでもなく、実はWord2vec の場合と考え方やトレーニングのプロセスに大差はないのです。Doc2vec では始めにコーパスに含まれているドキュメントごとに固有のIDを振りわけます。例えばコーパスに “dog book”、”puppy book” と ”car book” というドキュメントが含まれていたとして、それぞれ “dog book ID” = 1234, “puppy book ID” = 9876, “car book ID” = 7777 というようにする訳です。そしてそのIDのベクトル、つまりドキュメントベクトルをトレーニングするのです。Word2vecの例で word と context について説明しましたが、PV-DMではドキュメントIDをあたかも一つの語であるかのように扱い、図のようにcontext の一部として無理やりくっつけてしまうのです。word と context を分けて考えるのは Word2vec の考え方と同じで、異なるのは context に新たな要素としてドキュメントIDが加わった事だけです。そうしてDoc2vec のモデルをトレーニングすれば、ドキュメントベクトルは最適化され、例えば ”dog book” と “puppy book” のドキュメントベクトルは大体同じ方向を向き、 “car book“ のものは異なる方向を向く、という風にドキュメントがベクトルで表現されるのです。
分かりにくいですか?
確かにイマイチ直感的に伝わらないかもしれませんが、次のように考えてみてはどうでしょうか。Word2vec ではコーパスに含まれる各々の word の ワードベクトルを最適化し、他の word に対して相対化します。このときに実はトレーニングの仕組みの都合上、副作用として同時にコンテキストベクトルも最適化が行われます。ワードベクトルの最適化が光であれば、コンテキストベクトルの最適化は影です。その一方、Doc2vec においては今度はコンテキストベクトルの最適化が主目的になり、ドキュメント固有のコンテキスト(文脈)を表現するために、全ての context において document ID がアタッチメントとして加わるのです。そしてトレーニングの結果、コンテキストベクトルの成分の一部である document ID のベクトルを取り出せば、なんとそれはそのドキュメント固有の文脈を表している事になるのです。もっと詳しく知りたければこの論文を読んで下さい。
2.3 ニュースのベクトル化
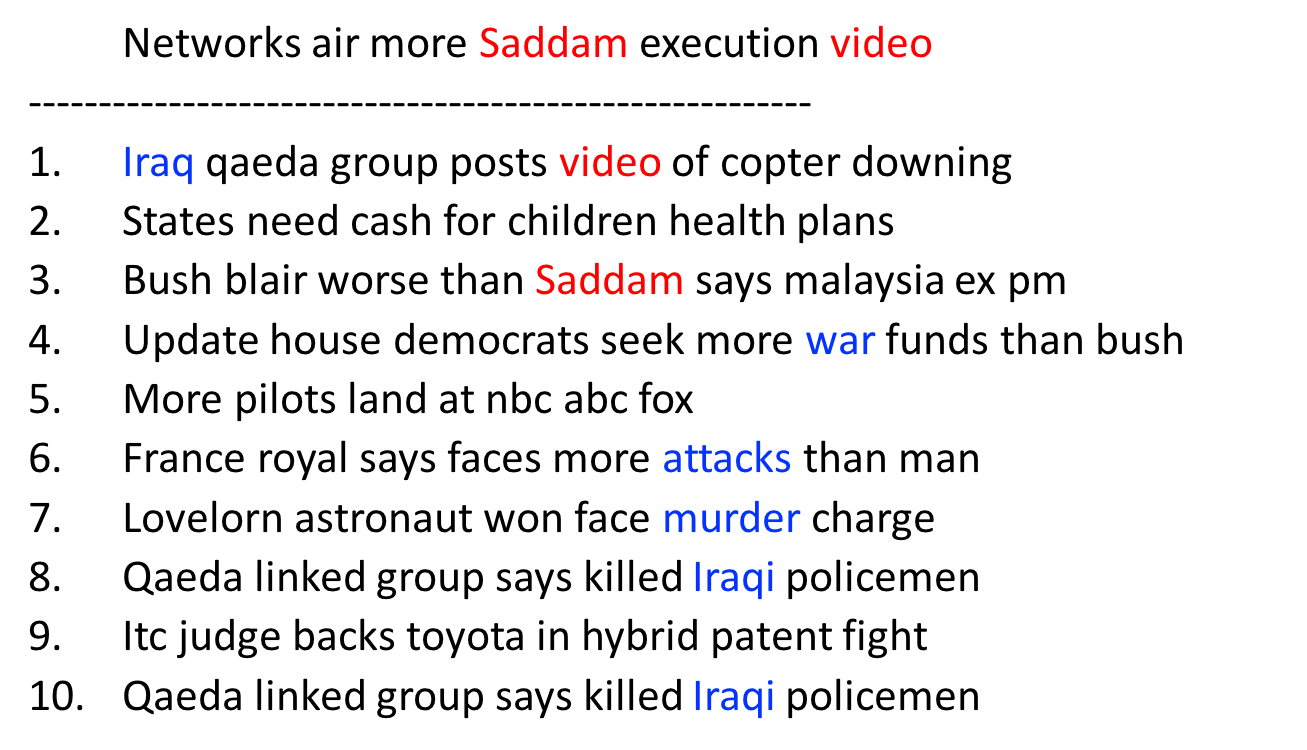
さて、今回はこのDoc2vecを用いてニュースのテキストをベクトル化してみました。用いたニュースデータはGitHubに公開されているロイター社のニュースタイトルデータセット、2007年から2016年までの約850万件分です。使用した Doc2vec のライブラリはDL4Jとgensim、どちらもオープンソースなので無料で使用できます。どちらも試した結果、DL4Jの方がトレーニングのスピードを上げるのが簡単だったので、こちらを使用しました。 ドキュメントベクトルの類似性調べるために、指標としてコサイン類似度(ベクトルの向いている方向の類似性を示す)を使い、選んだニュースに内容の近いニュースを1−10番目まで抽出します。下の図がその結果です。

ご覧のように、”what news title” というニュースタイトルの類似のものとして抽出されたものは株の相場に関する物ばかりです。そのほとんどはアメリカの株の相場についてですが、ランキングの下の方に Nikkei という語が含まれている事からもわかるように、日本の株の情報に関するニュースもランクインしています。国は違っても同じような話題であるという事をモデルが理解しているということがわかります。次の例では ”sadam news” と類似するニュースが抽出されていますが、元のニュースには出ていないものの関連性の高い語が含まれているニュースタイトルがいくつか含まれており、トピックの類似性がうまく。このように、Doc2vecによるニュースタイトルのベクトル化により、ニュースの類似性が数値的によく表現できたニュースベクトルの集まりを作る事ができました。
3. 実験ステップ2 -FX相場のモデル化-
それではDoc2vecにより得られたベクトルをつかって、FX相場のモデル化に挑戦してみましょう。FXデータは http://www.histdata.com からダウンロードしました。このウェブサイトからは66もの通貨ペアのデータが全て無料でダウンロードができるため大変重宝します。FX相場のモデル化にあたり、ダウンロードしたデータを次のステップで処理しました。
1.一日あたりのボラティリティの計算
2.使用する通貨ペアと期間の選定
3.ボラティリティの2値化
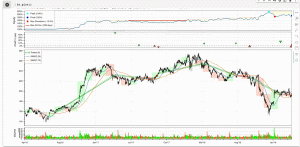
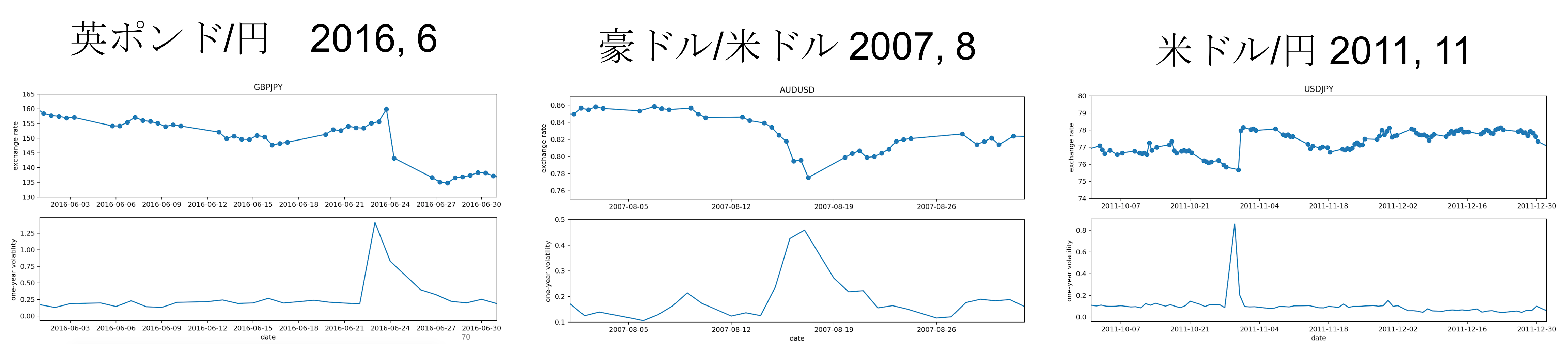
キーワードはボラティリティです。ボラティリティとは簡単に言えば取引の激しさ、値動きの激しさを数値化したもので、相場がガクーンと動いた時にはボラティリティの値もビョーンと大きく跳ね上がりピークをつくります。もし将来のボラティリティが完全に予測可能であれば、あらゆる相場取引において必勝の戦略が可能となると言っても過言ではない、とても重要な指標です。そのようなボラティリティの値を示したチャートを眺めながら、ボラティリティの大小がはっきりとした3つ通貨ペアと期間、
1.GBP/JPY (2016年6月)
2.AUD/USD (2007年8月)
3.USD/JPY (2011年11月)
を選定しました。
さらに機械学習モデル化の前処理として、計算したボラティリティを2値化します。2値化とはもともと連続的な値を持つ量を、0か1の二つの値に分けることです。男か女か、勝ち負けか、晴れか雨か、のような期待する答えが二通りしかない分類問題は、2値分類問題と言われますが、今回のFX相場のモデル化においてもエイヤっと単純化し、期間中の最高値と最低値の平均を境目とし、高ボラティリティか低ボラティリティか、と分けてしまおうということです。そしてこの2値化したその日のボラティリティを、どんぶり勘定的にその日のニュース全てに紐付けてしまいます。そうして出来た特徴量(ニュースタイトルのベクトル)とラベル(2値化したボラティリティ)のセットをまたまた単純化のためにランダムサンプリングによりトレーニングセットとテストセットに分けます。もしトレーニングセットとテストセットについて聞いたことがなければ、トレーニングセットは学校の宿題で、テストセットは中間テストだと思ってください。中学生は家で一生懸命宿題を解き、テストで学力を試されます。機械学習のモデルも同じように、トレーニングセットを一生懸命学習しテストセットでその性能を試されます。
ここまででようやく前処理の完了で、ここからようやく機械学習によるモデル化に入ります。機械学習には沢山のモデルがありますが、それを全部一度に試す便利なスクリプトがScikit-learn にはあり、これを用いてモデルの比較を行いました。
3. 結果

上の図が結果です。
分類問題を解くモデルの性能を示す指標として、アキュラシー(≒正解率)というものがよく使用されますが、図に示したようにテストセットに対するアキュラシーは、なんとどのモデルもどんぐりの背比べ的に0.8~0.9の値を出しています。アキュラシーの値は1に近いほど良い成績である事を意味し、今回の値は正解率8割~9割に相当します。いくつもの個性の異なるモデルを使っても成績が同じだなんて、これはなんだかおかしいですね。元のデータセットの高ボラティリティーと低ボラティリティーのバランスを確認してみると、アキュラシーが全体的に高く出ているデータセットはそもそも高ボラティリティーのニュースが少ない事がわかります。さらに詳しく見てみると全ての予測値を低ボラティリティと予測しても8~9割の正解率は出てしまう事がわかります。つまりこのデータセットを使う限りはデタラメなモデルでもアキュラシーだけを見ればそれなりの性能があるように見えてしまうのです。そしてその原因は高ボラティリティと低ボラティリティのニュース数のバランスの悪さであると導かれます。そこで、今回はF1スコアというものも合わせて使いました。詳しくは書きませんが、このF1スコアを使うとデータのバランスの悪さに影響されずにモデルの性能の評価が可能になります。興味のある方はここを読んで下さい。
だいぶ長くなってきましたね、あともう一息で結論です。
さて、F1スコアの方の結果を見ると、kNNというモデルの性能が全体的にみて一番良い事がわかります。kNNは日本語でk近傍法と呼ばれていますが、名前から類推できるようにラベル値が不明のデータポイントの近傍 k 個のラベル既知のデータポイントを調べ、多数決で未知のデータポイントの値を決めるものです。k を具体的にいくつとするかは自由に決められるので、この k の値をスキャンしてやれば、お隣さん何軒先まで調べると最も良い成績が出るかがわかります。そして実際にスキャンして見たところ、k=1 の時にもっともスコアが高い事がわかります。もし高ボラティリティのニュースのベクトルが他の高ボラティリティのニュースのベクトルの近傍にぎっしりと集まっているのであるのであれば、このような結果にはならなそうに思えますよね。本音を言うと、高ボラティリティのニュースのベクトル同士が固まっていて欲しかったところです。なぜならば、そうであれば例えば「なにがしの国の国民投票の結果、型破りな方針が選ばれた」というニュースを学んだモデルが、そのニュースベクトルのそばに現れるであろう 「どこそこの国の選挙の結果、型破りな大統領が選ばれた」 のニュースベクトル を検知してFX相場への影響を予測できると期待できるからです。ところが今回の結果を見る限りはそうは行かないようです。
4.考察 -偽陽性の混入-
このような結果になった理由の一つとして考えられるのは、偽陽性の混入です。偽陽性とはテストの結果陽性と判定とされたものの、真の値は陰性である事です。例えばインフルエンザ感染を検査するため体温を測ったら40度と出たものの、高熱の理由はサウナの中で体温を測ったから、という例は偽陽性です。今回のニュースの例でいうと、ブレグジットの日にたまたま電車の遅延のニュースが報道された場合、このニュースは経済への影響がほぼないであろうにもかかわらず、どんぶり勘定なラベル付けの手法の都合上、高ボラティリティと値づけられてしまったという事です。つまり、本来であれば作成したデータセットにはFX相場への影響があるニュースのみが高ボラティリティとして含まれているべきなところ、実際には偽陽性のニュースによって汚染されているために、高ボラティリティと低ボラティリティのニュースがまだら状に入り混じっている、非常に散らかった状態であると考える事が可能です。このために、偽陽性に惑わされたモデルはその性能が伸びず、高ボラティリティのニュースを的確に判定できていないという考え方が、説明の一つとして成り立ちます。
5.課題と結論
今回の実験の結果、ニュースのドキュメントベクトル化には成功したものの、そこからFX相場を予測し大金ザクザクになるまでの道のりはまだ長い事がわかりました。しかし、今回の実験を通して学んだ事を活かせばさらなるモデルの改善が可能です。まず、偽陽性のニュースの問題はどんぶり勘定的なラベル付けの方法を改め、1日単位でなく時間をもっと細かく区切るなどしてラベル付の方法を工夫する事で改善できる見込みがあります。さらに、そもそも高ボラティリティのニュースの数が少ない事は、モデルのトレーニングが正解例の非常に少ない問題集を解かされているような難しさを伴っている可能性があり、これについてはニュースのソースを増やせばモデルの性能にプラスのインパクトがある可能性があります。
そういう訳で今回の結論といたしますが、いかがでしたでしょうか?もし皆さんの応援があれば、この続きの研究開発がひょっとしたら可能になるかも知れませんので、続きが読みたい方はぜひポジティブなフィードバックをお願いいたします。また、誤字、脱字などの指摘はこちらへどうぞ。
次世代システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。ご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。
皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD