2020.01.09
モバイル上のセマンティックセグメンテーション – 減損現実(DR)の実現へ
はじめに
こにちは、次世代システム研究室のB.M.Kです。
この数年、深層学習の普及により深層学習を用いたセマンティックセグメンテーションの研究が盛んになってきました。セマンティックセグメンテーションは自動運転に幅広く使われているだけではなく、AR, VRそしてDR(Disminished Reality: 減損現実)にもよく利用されます。
今回は深層学習を用いたセマンティックセグメンテーションの紹介、そしてモバイル上(iOS)の実証実験の結果を共有したいと思います。
減損現実(Diminished Reality: DR)とは
実際に存在しないものを現実に重ねて見せる拡張現実(AR)とは逆に実際にあるはずものを無かったことにする(減損する)技術と言います。減損現実を用いて画像修復やビデオ又はカメラで取ったストリームの映像にて不要なオブジェクト等をリアルタイムに消したりすることがより簡単に実現できるようになりました。
減損現実は拡張現実と結合することもでき、その結合による多くの用途が生まれます。例として住宅リフォームやリノベーション事業にて部屋の一部又は全部のものを減損現実で消しながら拡張現実(AR)を利用してバチャールなものを差し替え、再配置等を実施し、プレビューすることができます。これによりリフォームを行う前にリフォーム後の状態の確認ができ、新家具の購入やリフォームの決断等を促進することへの貢献を期待できます。

図1: 減損現実及び拡張現実 出典
減損現実の実現に向けて主なステップ
減損現実を実現するために、主な三つのステップを経過します。まずはセマンティックセグメンテーションを行い、次にプクセルレベルの削除の実施、そして最後に画像修復(背景復元等)を行うことになります。三つのステップの中、セマンティックセグメンテーションが最も重要なステップだと言え、今回はマンティックセグメンテーションを中心に紹介したいと思います。
セマンティックセグメンテーションとは
領域分割という意味で、入力画像のプクセルレベルでカテゴリ分類する手法です。例として図1にて切り取った10×10ピクセルの範囲でどのピクセルがどのカテゴリ(皿、机)に配属するか明確にすることはセマンティックセグメンテーションのアウトプットです。
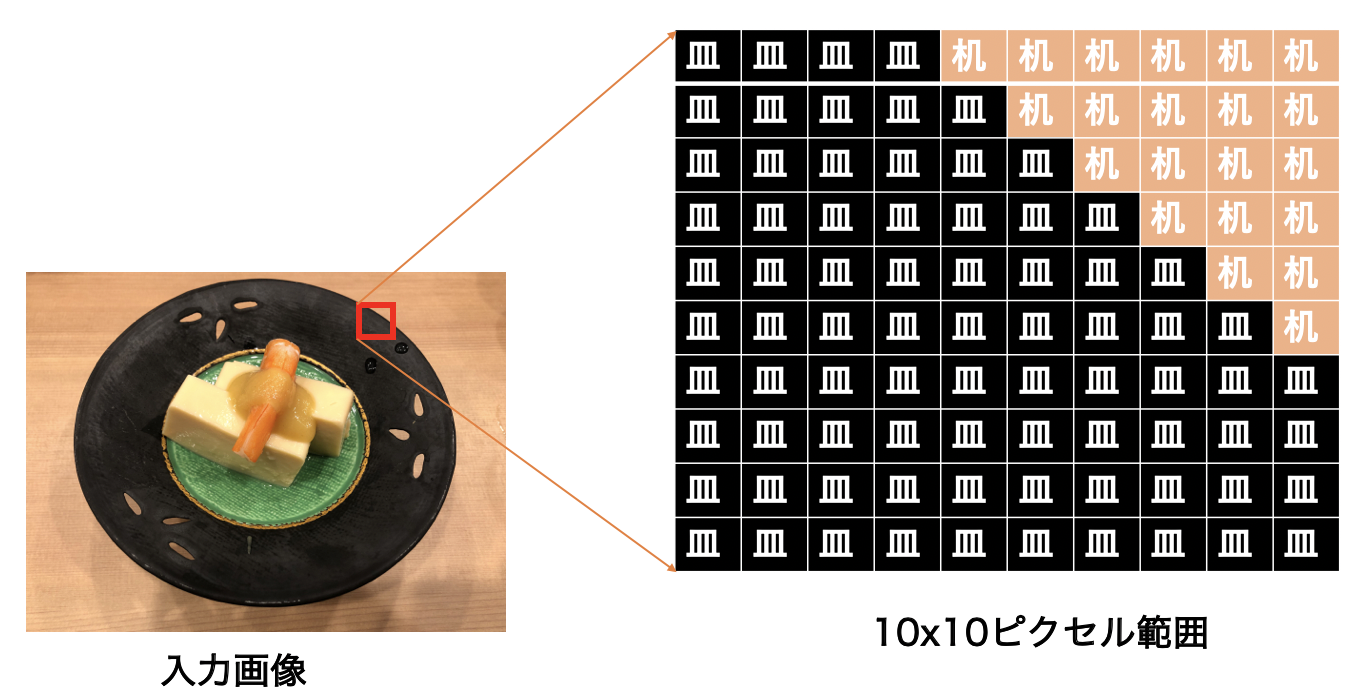
図2 : セマンティックセグメンテーション
セマンティックセグメンテーション技術のアプローチ方法
深層学習(ディープラーニング)がコンピュータビジョン分野に普及する前にセマンティックセグメンテーションを行う際にはテクストンフォレストのようなものを使用していました。そして、初期のディープラーニングの一般的なアプローチの1つに、パッチ分類があります。大きな変化を示すのは2014年バーグレーのLongらによる全増畳み込みニューラルネットワーク(FCN)の発表でした。全結合層を使わない畳み込みニューラルネットワーク(CNN)アーキテクチャの利用というFCNの特徴が普及しました。
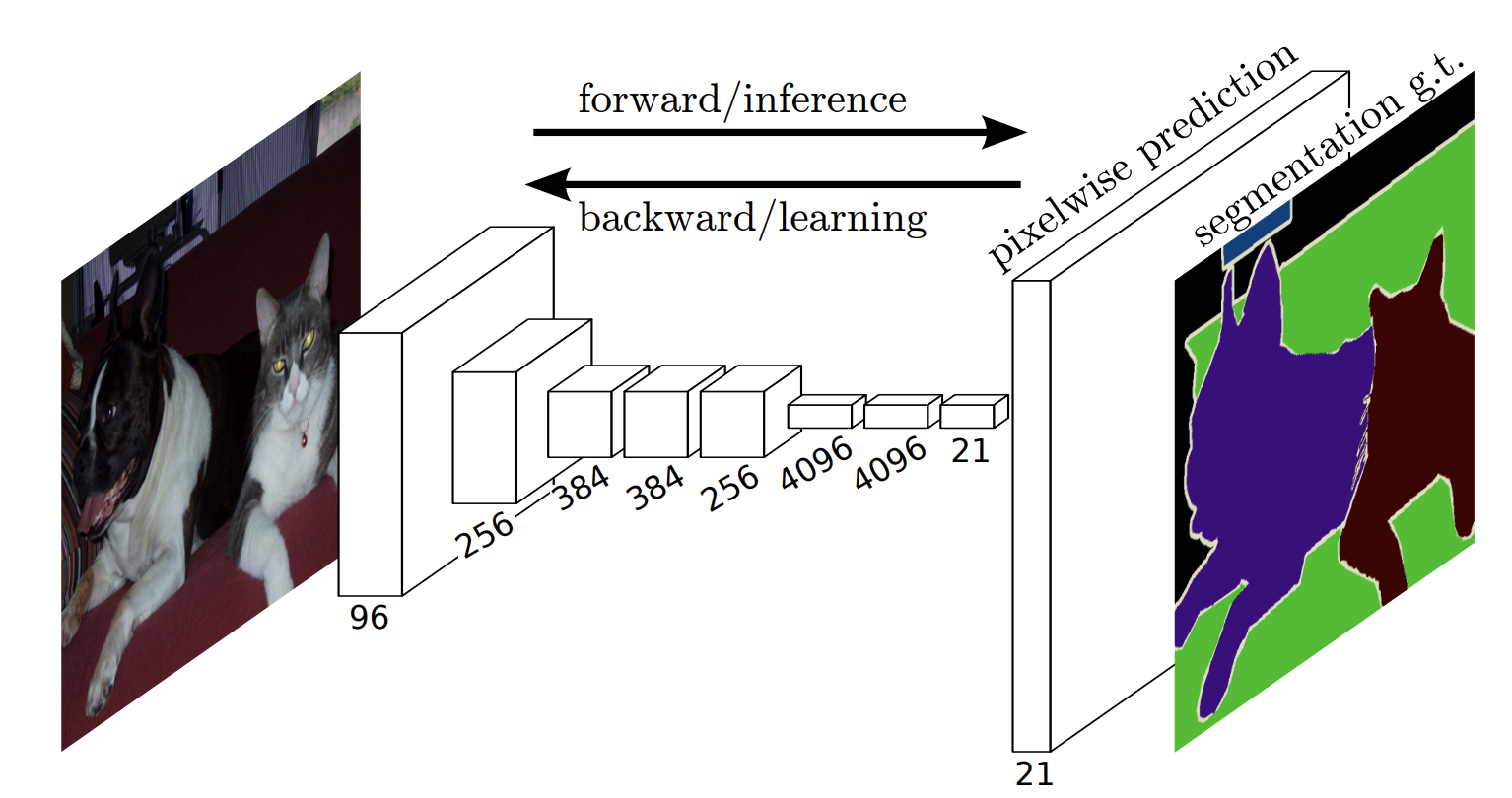
図3: 全層畳み込みネットワーク(FCN: Fully Convolutional Networks) 出典
セグメンテーションのためにCNNを利用する際の主要な問題の1つはプーリング層です。プーリング層によって特徴の強調、コンテキストの集約そして計算量の減少に役に立ちますが、”位置”情報が破棄されます。セマンティックセグメンテーションは正確なクラスマップの配置を必要とするため、”位置”情報の保存が必要になります。この問題に取り組むため、2つの異なるアーキテクチャのクラスが進化されました。
1つ目は、エンコーダ・デコーダアーキテクチャです。
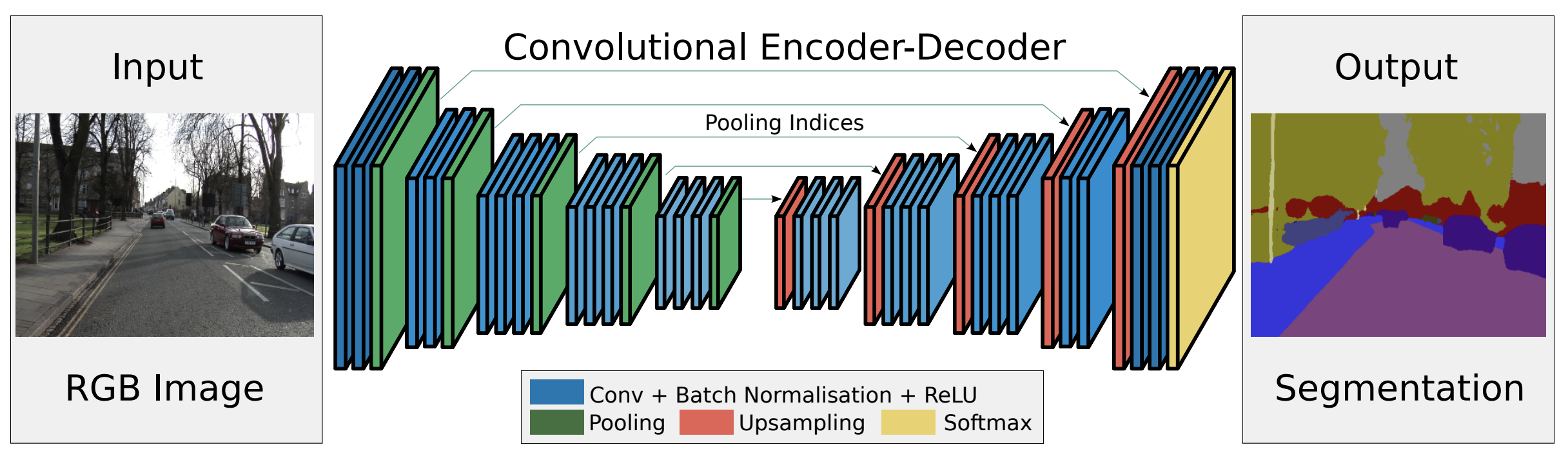
図4: エンコーダ・デコーダアーキテクチャ 出典
エンコーダは特徴抽出及び分類を行う役割を持ち、FCNの特徴抽出の部分と同構成で、全連結層を持ちません。抽出した特徴マップと元画像のピクセル位置の対応関係をマッピングすることがデコーダの役割です。デコーダはエンコーダと連結して対称構造のようなネットワーク構成になります。
FCNアーキテクチャでは、途中の各プーリング層の特徴マップをアップサンプリングの際に利用していましたが、そのために各特徴マップを一時的に保持する必要があり、メモリ効率が悪かったです。エンコーダ・デコーダアーキテクチャにてエンコーダでプーリングを行う際、プーリングした位置を最大プーリングインデクス(max-pooling index)として記憶しておき、デコーダで記憶したインデクスだけを利用してアップサンプリングするのでメモリ効率を高めています。
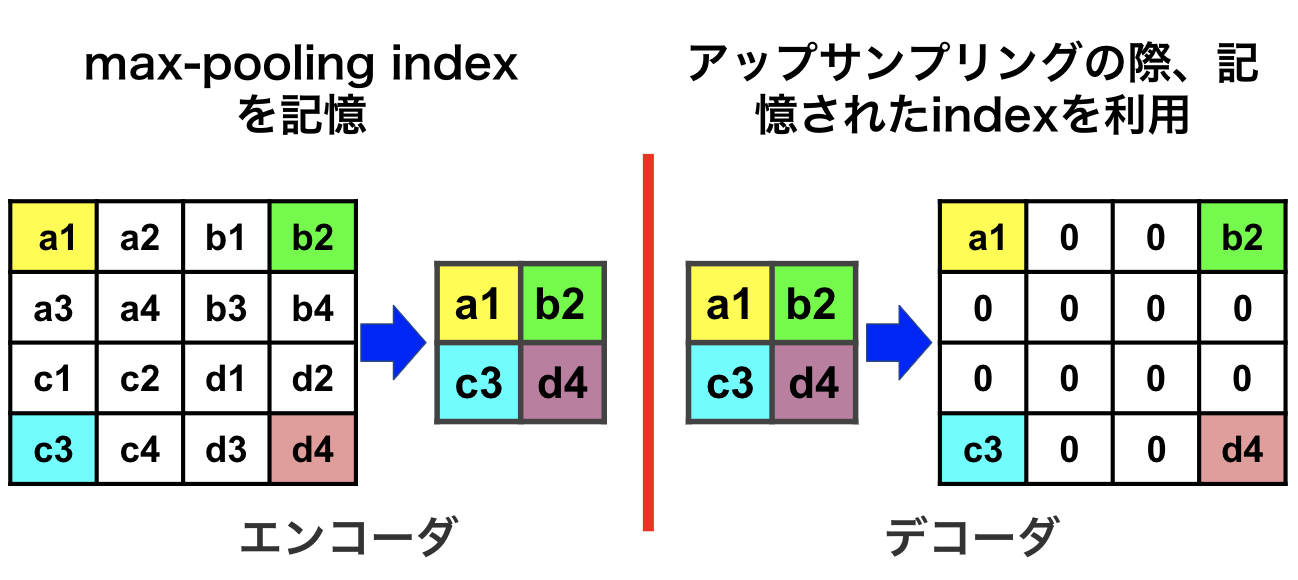
図5: max-pooling indexの記憶及び使用
2つ目はDilated/Atrous畳み込みと呼ばれるものでプーリング層を使いません。
Dilated/Atrous畳み込みは、畳み込みを行う際に、フィルター(カネール) の間隔(Dilation)を変えて処理を行います。通常は畳み込み層で畳み込みを行い、局所的な情報を特徴マップとして抽出し、プーリング層で集約して特徴マッ プが捉える空間領域を拡大します。しかしプーリング層を 用いる場合、画像サイズが小さくなり、情報の損失が生じます。これに対し、本アーキテクチャではプーリング層を使わず、Dilated 畳み込み層を用いることで画像を極端に小さくすることなく情報を集約でき、広範囲の特徴を捉えることができます。
フィルターの重みにレートというハイパーパラメーターで指定したゼロの数を入れてフィルターのサイズを拡張することができます。入れるゼロの数は以下の式で計算します。
入れるゼロの数 = レート – 1
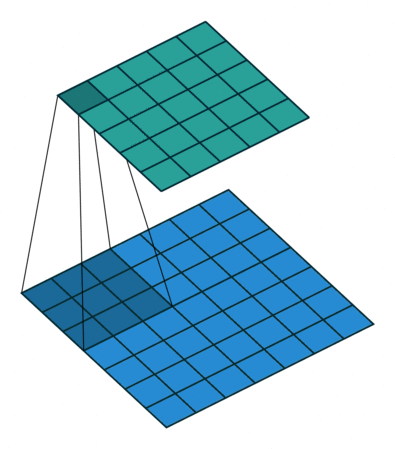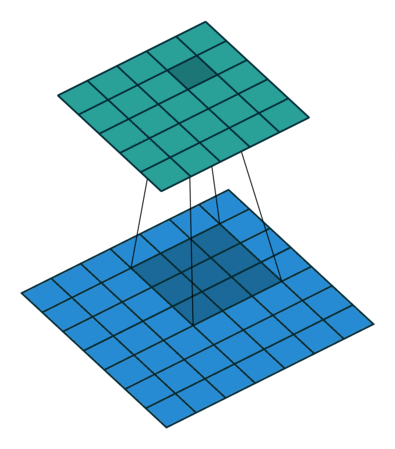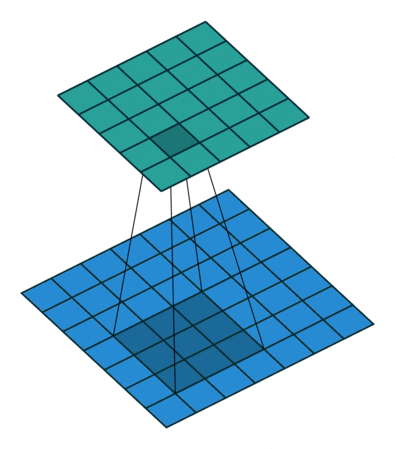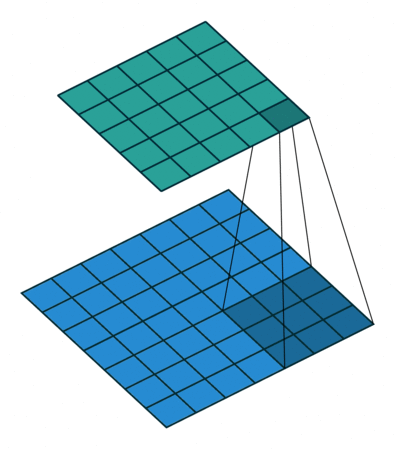
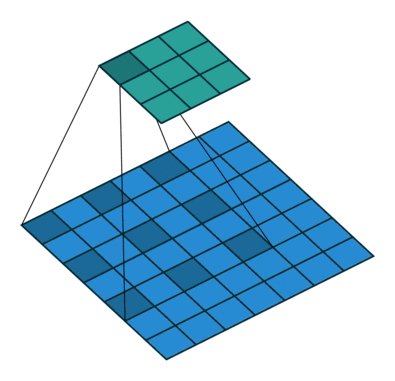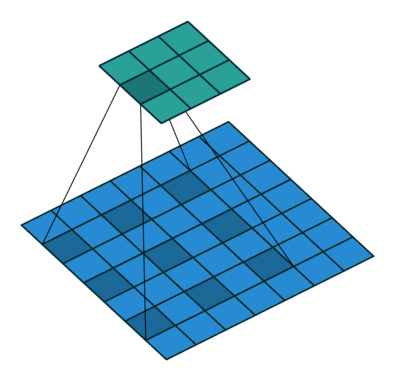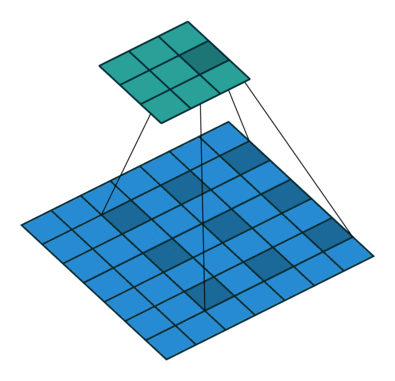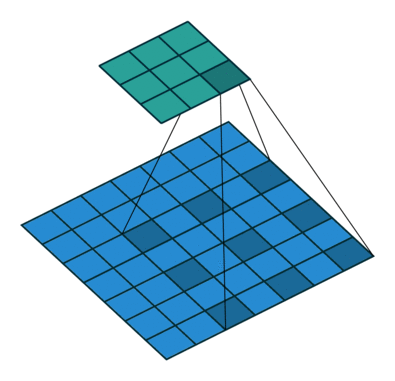
フィルターサイズ: 3×3, レート = 1 フィルターサイズ 3×3, レート = 2
図6: Dilated/Atrous畳み込み。出典
DeepLab(V3)
DeepLabはGoogleが作ったセマンティックセグメンテーション向け多層ニューラルネットワークアーキテクチャです。DeepLabは一般画像分類用のニューラルネットワークのアーキテクチャ(ResNet)のバックボーンの利用とDilated/Atrous畳み込みアーキテクチャを使用します。また、Dilated/Atrous空間ピラミッドプーリング(ASPP: Atrous Spatial Pyramid Pooling)というものを利用して複数のスケールでコンテキスト情報を同時に集約します。 任意な入力画像のサイズとオブジェクトのマルチスケールの問題を解決することができます。

図7 : Dilated/Atrous畳み込みがない/ある場合の特徴マップのサイズの変更 出典
学習データ
DeepLabはPASCAL VOC2012というデータセットを利用して学習します。
PASCAL VOC2012は「Pattern Analysis, Statistical Modeling and Computational Learning Visual Object Classes」の省略で画像認識用のデータセットです。元画像を写真の共有を目的としたコミュニティサイトであるFlickr(フリッカー)から利用し、人、車、犬、猫、椅子など20クラスのラベル付けがされています。
DeepLabのモデルを学習させる際、学習データは以下のように画像の種類とフォーマットを用意する必要となります。
1つのシーンについて2種類の画像を用意する必要です。
- 元画像
- ラベル画像 : 元画像の中の識別したい領域を既定の色で塗りつぶした画像
この2種類を1セットとして、複数セットの画像を用意してデータセットを構成します。
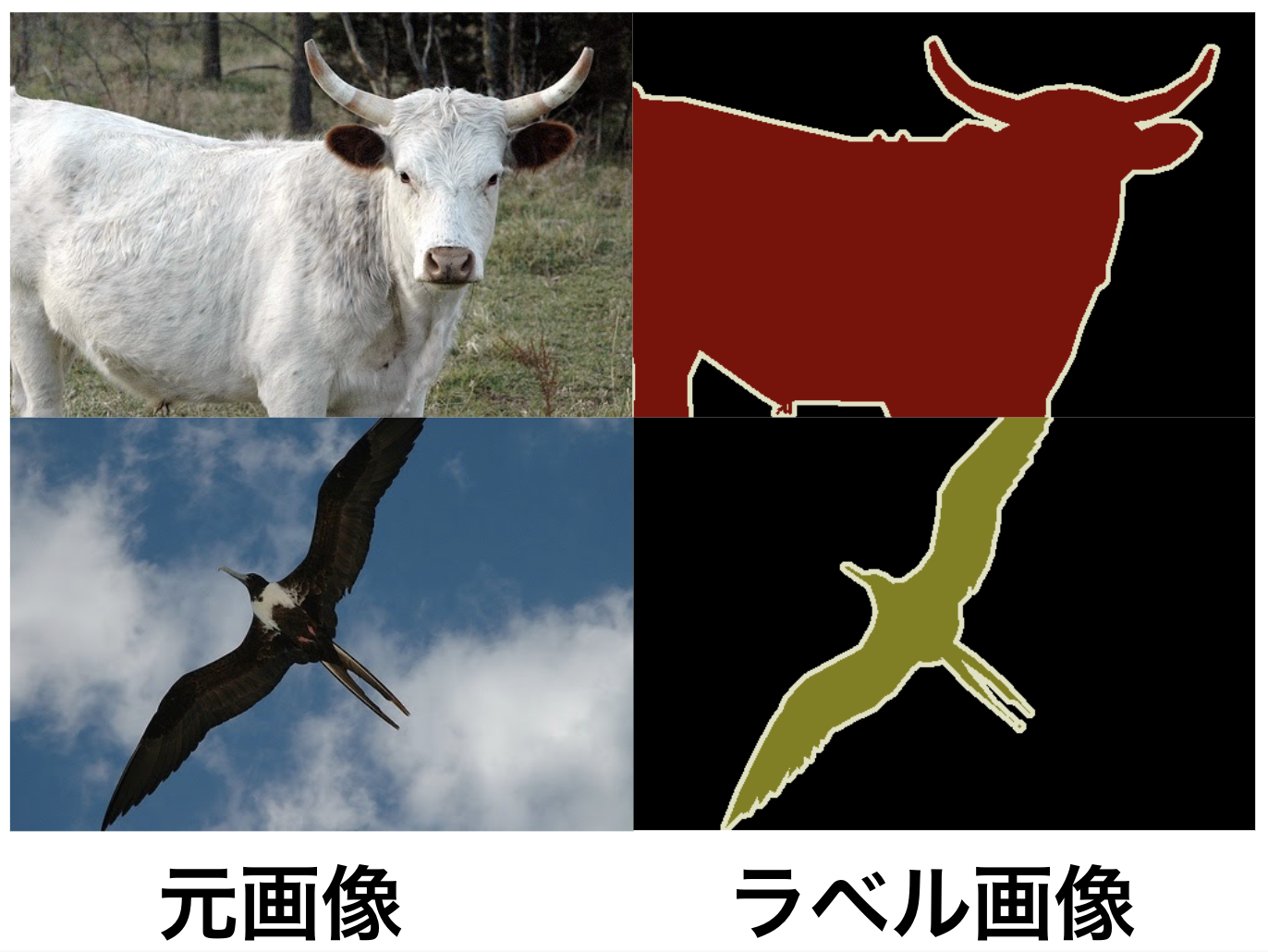
図8: DeepLabモデルを学習させる際の学習データ(元画像とラベル画像)
画像のサイズは任意で良いですが元画像とラベル画像は同じサイズでなければなりません。元画像のフォーマットはjpegまたはpngでラベル画像のフォーマットはpngでカラー画像で良いです。読み込み時にモノクロに変換されます。カラー画像を用意する場合、PASCAL VOC 2012既定の色で識別領域をマスクした画像を用意します。境界線の有無に関しましてPASCAL VOC2012 のラベル画像には無効色で物体の境界線が描かれていますが、必須ではないです。
モバイル上(iOS)の実証実験
DeepLabV3はTensorFlowで実装されたPC向けのモデルであるので、iOSに利用したい場合、iOSがサポートする深層学習フレームワーク(CoreML)の形式への変換は必要となります。
CoreMLとは、Appleが提供している機械学習のフレームワークです。
CoreMLはiOSのデバイス上で実行できる為、外部との通信をする必要はないかつデバイスのCPU、GPUを活用するので最大限のパフォーマンスが発揮できます。CoreMLで使える機械学習モデルは、Appleが配布しているモデルと他の各種機械学習フレームワークで学習され、Core MLフォーマットに変換されたモデルです。
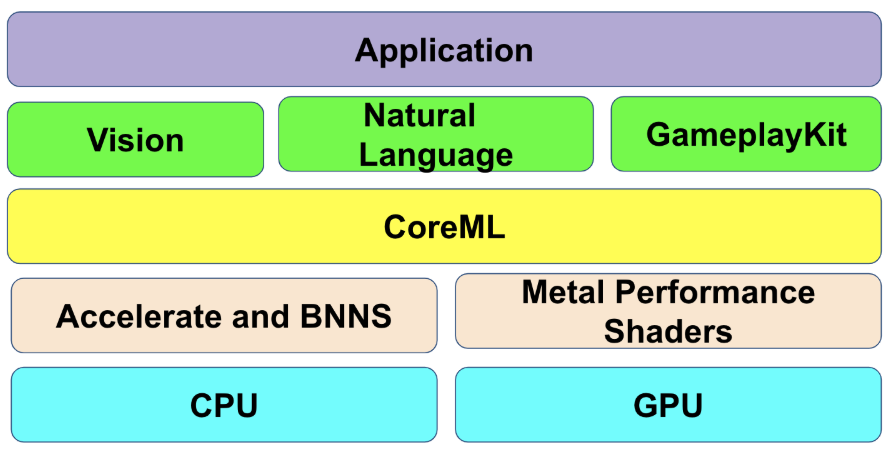
図9: Appleの開発スタックにてCoreMLの位置付け
CoreMLの形式に変換する際、Appleが独自開発したCoreML変換専用ツール(CoreML Tools)を利用するか、第三者の変換ツールの利用(MXNetコンバーターやTensorFlowコンバーターなど)若しくはONNX(Open Neural Network Exchange)フォーマットを経由して行う方法です。それぞれの方法はサポートする機械学習フレームワークが違うので以下の図を参照して下さい。
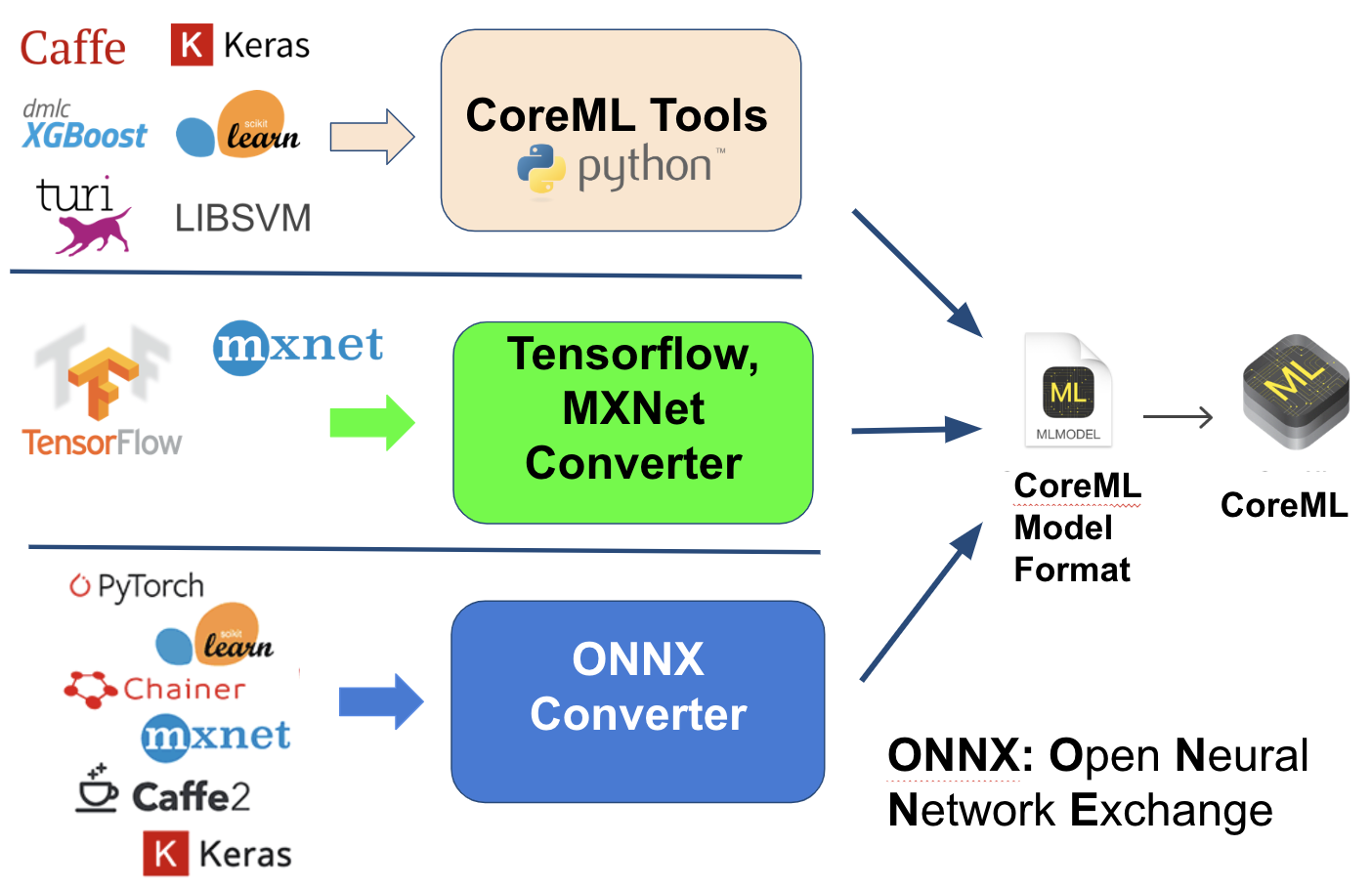
図10 : CoreMLへの変換手法
開発環境
今回実証実験用のデモを作成するのに以下の環境とコンポーネントを使用しました。
- 学習済みDeepLabV3モデル
- TensorFlowコンバーター
- iOS12.4.1
- Swift
- PhoneXS
考察1- 静止画像のセマンティックセグメンテーション
まず、静止画像のセマンティックセグメンテーションの結果を見てみましょう。

図11: 静止画像のセマンティックセグメンテーション1
図11は非常に単純な入力画像とDeepLabV3でセグメンテーションを行った後の結果画像です。モデルのベンチマークテスト結果と同様に、画像内の人物と背景は綺麗に分離されています。

図12: 静止画像のセマンティックセグメンテーション2
次に図12の入力画像は、さまざまなオブジェクト(人物、テーブルなど)を含むより複雑な画像ですが、アルゴリズムは画像内のオブジェクトを正確に各カテゴリに分類しました。DeepLabV3は人、車、犬、猫、椅子など20クラス程度で学習されたモデルなので, 料理などの学習されていないものを分類しません。
考察2 – リアルタイムにスマホカメラの画像の処理
次にスマホのカメラで撮ったストリーミング映像に対してセマンティックセグメンテーション を実施した結果です。結果によると動的映像に対しても人物と背景等を綺麗に分類できました。ただ、セグメンテーションの結果をリアルタイムにレンダリングする際、スマホの処理性能により遅延が発生してしまいました。スマホの現状の性能でスマホ上リアルタイムにセマンティックセグメンテーションを行いながらARKitセクションを開始するのが困難であることを実験で分かりました。ARKitと結合できるようにいくつかの違うアプローチを検討しており、別の機会に共有します。
まとめ
今回、減損現実の実現に向けて深層学習を用いたセマンティックセグメンテーションの手法の調査と纏めをしました。その中、セマンティックセグメンテーション用の代表的な多層ニューラルネットワークアーキテクチャ(FCN、エンコーダデコーダ、Dilated畳み込み)を紹介しました。そして、セマンティックセグメンテーションに最強と言えるモデル(DeepLabV3)をモバイル上(iOS) に実証実験を行い、結果を考察しました。セマンティックセグメンテーションは多くの用途があり、今後のアルゴリズムの改善及びモバイル端末の計算処理能力の発展とともに実用の高いアプリが誕生することを期待できます。
最後に
次世代システム研究室では、アプリケーション開発や設計を行うアーキテクトを募集しています。アプリケーション開発者の方、次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD

