2024.07.08
Redisのベクトル検索が超速い
釣り気味のタイトルですが,なかなか速いと思います。
少なくともLocal環境でちょっとしたアプリケーションで使うのには十分です。また,ベクトルと一緒に諸々のデータも格納できるので,ユースケースによっては「ドキュメントIDに紐づけて別のDBでデータの実体を管理する」ということをやらなくて良い,というのもメリットです。
1.Redisのベクトル類似度検索
高速なKVSとしてお馴染みのRedisですが,実はベクトル類似度検索も扱うことができます。といっても,Redisの本体でベクトル検索を行うわけではなく,拡張モジュールを使用します。
ベクトル検索をはじめとする拡張モジュールは,RedisStackに含まれていますので,これを使うと手軽に試すことが可能です。
昨今,ベクトルの類似度検索の需要がかなり高まっていると感じます。手元で実験的なアプリケーションを作るのにも,内々で使うちょっとしたツールを作るのにも,ベクトルの出し入れを行う器を何にするか,というのは悩ましいところです。
RDBであれば,SQLiteを使ってサクッとプロトタイプを準備することができます。ベクトルの類似度検索においては,Redisをそのような立ち位置で使うことができるのではないでしょうか。
2.さっそく使ってみる
では,さっそくRedisStackを立ち上げてベクトルの検索をしてみましょう。基本的な手順はQuickStartGuideに書かれていますが,サンプルデータの準備など冗長な部分も多いので,エッセンスを抜き出して記載しておきます。
まずはRedisStackの起動です。今回は無駄にcomposeで起動。
version: "3"
services:
redis:
image: redis/redis-stack:latest
ports:
- 6379:6379
- 8001:8001
これをupすれば,6379でRedis,8001でRedis InsightのGUI(ブラウザから開く)が起動します。
次にデータの投入です。ベクトルデータはバイナリとJSON(配列)で扱うことができます。JSONはベクトルデータをテキストで表現でき,他の情報も一緒に格納できるので,まずはこちらを試すと良いでしょう。これをredis-cliから投入するのは骨が折れるので,今回は以下のようなPythonスクリプトを準備しました。2048次元のベクトル(中身は乱数)を10万個格納します。
import redis
import random
import json
client = redis.Redis(host="127.0.0.1", port=6379, decode_responses=True)
time_sum = 0
vec = [0] * 2048
for i in range(100000):
key = f"test:{i:03}"
print(key)
for j in range(2048):
vec[j] = random.random()
client.json().set(key, '$', {"title": key, "vec": vec})
# redis-cli
# 127.0.0.1:6379> JSON.GET test:000 $.title
# "[\"test:000\"]"
さて,ベクトルデータの準備ができたので,それに対してIndexを作成をしましょう。アルゴリズムや要素の型,次元,距離を指定します。今回はアルゴリズムはFLATを指定しましたが,HNSWを指定することも可能です。また,距離も今回使用したコサイン類似度のほかL2距離などを利用することも可能です。
FT.CREATE idx:vss_flat ON JSON
PREFIX 1 test: SCORE 1.0
SCHEMA
$.title TEXT WEIGHT 1.0 NOSTEM
$.vec AS vector VECTOR FLAT 6 TYPE FLOAT32 DIM 2048 DISTANCE_METRIC COSINE
これで検索を行う準備ができました。実際の検索クエリもredis-cliから発行するのは面倒(ベクトルの次元が多いので。。)なので,Pythonのスクリプトを準備します。
import redis
import random
import json
import time
import numpy as np
#import pandas as pd
from redis.commands.search.query import Query
client = redis.Redis(host="127.0.0.1", port=6379, decode_responses=True)
time_sum = 0
query = (
Query('(*)=>[KNN 5 @vector $query_vector AS score]')
.sort_by('score')
.return_field('score', 'title')
.dialect(2)
)
vec = [0] * 2048
for j in range(2048):
vec[j] = random.random()
start = time.time()
result_docs = (
client.ft("idx:vss_flat")
.search(
query,
{"query_vector": np.array(vec, dtype=np.float32).tobytes()}
).docs
)
print(result_doc)
このスクリプトは,ランダムなベクトルを生成し,そのベクトルに近いベクトルをKNN法で5件取得します。さらに,ベクトルに対応するデータ(今回はタイトル)も同時に取得できます。このように,非常にシンプルな手順でベクトル検索を行うことが可能です。
3.性能を見てみる
さて,2で準備したRedisとスクリプトを使って,性能を見てみましょう。検索スクリプトを修正して,1000回の検索を実行し,検索にかかった合計実行時間を取得します。実行環境はM2 MacBook Pro(32GB)上にRancherDesktopで構築したコンテナです。
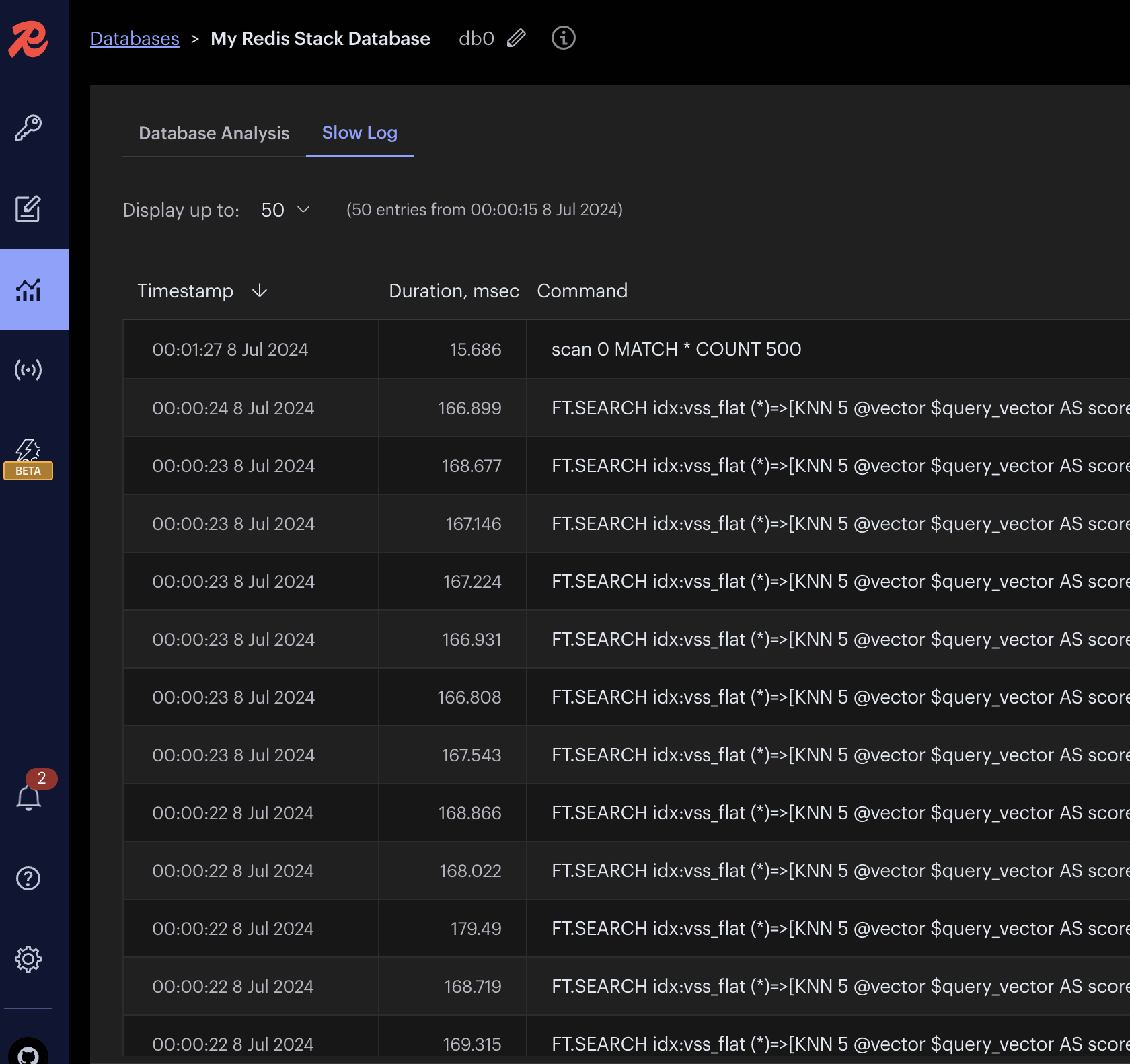
実行結果は,172.4秒でした。つまり,1回の検索にかかる時間は平均172ミリ秒です。図1のように,Redis InsightのSlowlogを見ても,だいたい170ミリ秒前後なので,安定してこのくらいの時間で結果を取得できているようです。
FT.CREATE idx:vss_hnsw ON JSON
PREFIX 1 test: SCORE 1.0
SCHEMA
$.title TEXT WEIGHT 1.0 NOSTEM
$.vec AS vector VECTOR HNSW 6 TYPE FLOAT32 DIM 2048 DISTANCE_METRIC COSINE
結果は,1350秒でした。1回あたり,1.35秒かかっていることになります。これはあくまでも今回の条件でのものですので,件数が増えてくるとFLATがどんどん遅くなり,HNSWの利点が生きてくるでしょう。
手元で実験的に動かすアプリケーションであれば,10万個のベクトルを検索して700ミリ秒で結果が返ってくれば,十分速くて使えると言えるのではないでしょうか。
参考までに,著名なベクトルデータベースであるMilvusのパフォーマンス評価を見ると,スタンドアローン環境で1000万ベクトルに対して検索をかけると,p99で700ミリ秒程度のレイテンシのようですので,市場で評価を得ている製品に近い性能が出ている,と言えるでしょう。
4.まとめ
今回は,RedisStackでベクトル検索を行い,レイテンシを調査しました。結果,小規模データであればローカルマシンのコンテナ上でも700ミリ秒程度のレイテンシで結果を得ることができ,実験的なアプリケーションには十分であることがわかりました。
次世代システム研究室では,グループ全体のインテグレーションを支援してくれるアーキテクトを募集しています。アプリケーション開発者の方,次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら,ぜひ募集職種一覧からご応募をお願いします。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD