2015.12.22
スケールアウト可能なSQLエンジンのベンチマークテスト:Presto vs Spark SQL vs Hive on Tez
1、初めに
次世代システム研究室のL.G.Wです。最近リリースした関連記事推薦システム:TAXEL byGMOに携わっております。
このシステムは多様なデータソースからの集計・解析・ETLが重要になるので、性能とビジネス要件を満たすSQLエンジンを選定するため、主要なSQLエンジンのベンチマークテストを実施しました。
“Small Start, Scale Fast” – 最初のハードウェアコストをなるべく低く抑え、ビジネスが拡大したらシステムも拡張できることが前提です。主にバッチ処理用途で、ある程度のリアルタイム性も要求されます(数分間~1時間内)。データの規模は数十GBから数TBくらいの想定です。
主要なSQLエンジンとして、スケーラビリティを考慮しRDBは対象から除外、下記のHadoop系のSQLエンジンを候補にしました:
- Hive(MapReduce)
- Presto
- Spark SQL
- Hive on Tez
- Impala(Cloudera)
- Apache Drill(MapR), Tajo(LinkedIn)
今回は上記候補の中から開発要件にマッチしたHive、Presto、Spark SQLの3つを比較しました。Hiveに関してはHive on TezというMapReduceから実行エンジンを切り替えたものがあり、TezはMapReduceより数倍速く、同じ安定性も持つという実証実験があるのでHive on Tezを利用し、従来のHive(MapReduce)は除外しています。Impalaは候補から外しましたが、本Blogのまとめにおいて、筆者の経験からImpalaについてもコメントを付けました。
- Presto
Facebookが開発しオープンソースとして公開した、インメモリーSQLエンジン - Spark SQL
Sparkと連携が容易なDAGベースのSQLエンジン - Hive on Tez
MapReduceに替わるHiveの進化版(DAGベース)。実行スピードとデータスケールを両方重視。Cost Based Optimizationをサポート
DB性能のベンチマークテストは、基本的にTPC基準で実施されていますが、今回の検証目的と対象から考えると、汎用的かつ重いTPCの実施を見送り、UC Berkely AMP Labのビッグデータベンチマークをベースにして、実際のシステム要件(Insert Overwrite可能)にあわせてカスタマイズしてベンチマークを行いました。
2、テスト条件
2.1 テスト環境
Master Node: 3
Slave Node: 5
Hardware
CPU: 4 vCore per Node
Memory: 16 GB per Node
Software
HDP: HDP-2.2.6.0-2800
Hadoop: HDFS 2.6.0.2.2
YARN: 2.6.0.2.2
Presto: Prest-0.86
Spark SQL: Spark 1.2.1.2.2
Tez: 0.5.2.2.2
Hive: 0.14.0.2.2
Java: 1.7.0
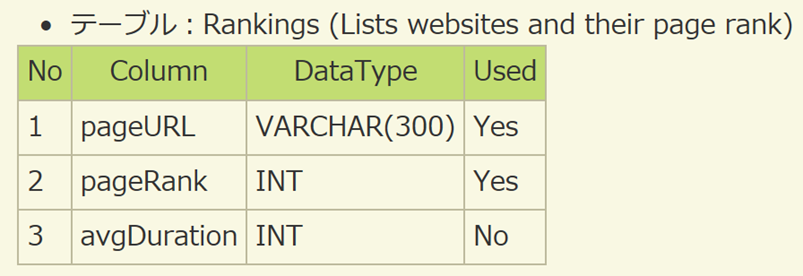
2.2 テストデータのスキーマ&規模
テストデータはウェブページのアクセスログを想定、下記の二つテーブルを定義する:

下記の5つデータセットを用意:
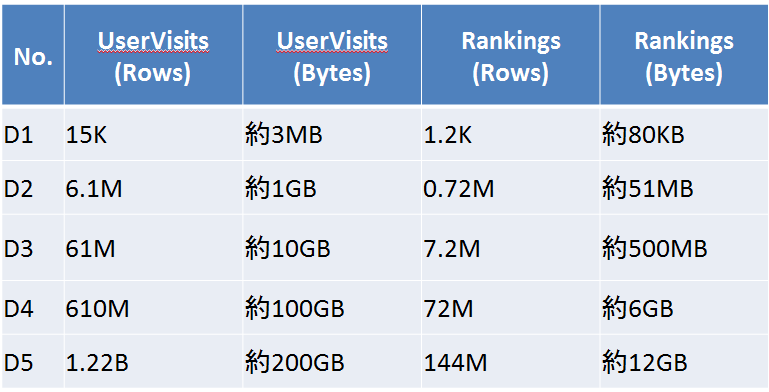
データはORCのフォーマットでSnappy方式で圧縮しHDFS上に格納。最大のデータセットは1。
2.3 テストSQL
今回はAMP Labが定義したベンチマークのSQL(Scan Query, Aggregation Query, Join Query)と、カスタマイズしたSQL(Sort Query, Insert Query)を検証した:
[table id=4 /]
上記のQ3とQ4の出力件数は100件に制限。ソートしてからの件数制限となるので、クエリ性能には影響しない。
3、テスト結果
3.1 概要
上記の5つのSQLを、5つのデータセットに対して実行。結果は下図のようになりました。一般的に、同じSQLの2回目の実行はキャッシュのため速くなるので、下記の結果は1回目の実行時間のみを計測しています。また、PrestoはクエリQ5(Insert Overwrite)をサポートしないので、PrestoのQ5は検証できませんでした。さらに、データサイズが大きくなると、PrestoとSpark SQLはメモリーが足りなくて失敗したクエリが見られました。一方、Hive on Tezはすべてのデータセットに対しすべてのクエリが成功しています。
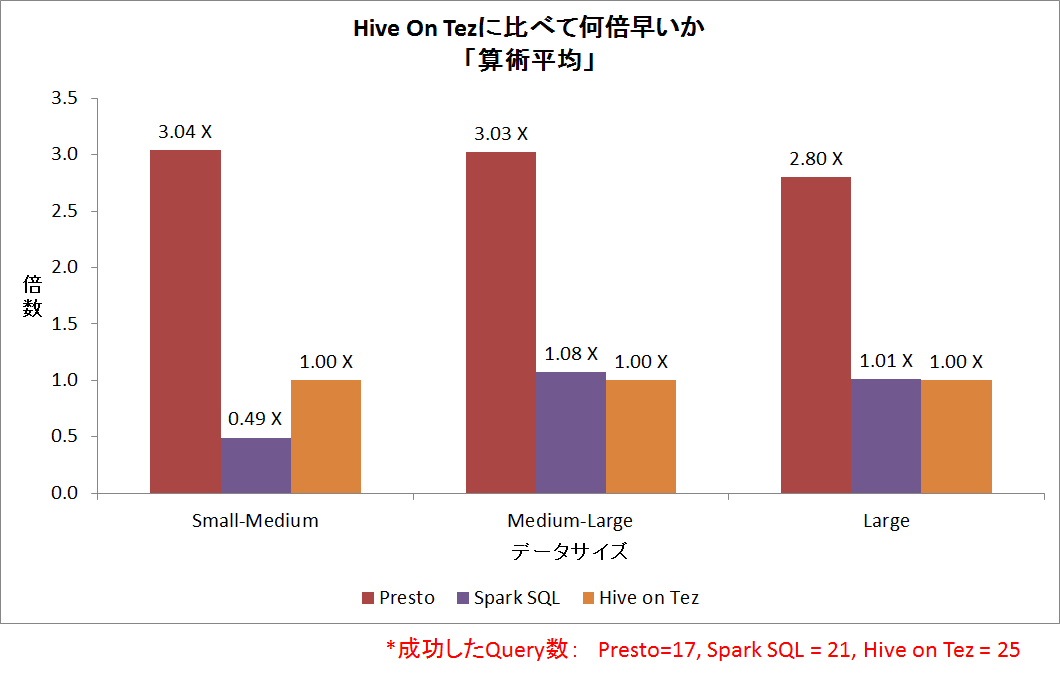
上図の縦軸はHive on Tezの実行時間をベースにして、Spark SQLとPrestoが何倍速いかを示す。上図の横軸はSmall-MediumはデータセットD1、D2とD3上のQ1~Q4の平均実行結果、Medium-LargeはデータセットD3、D4とD5上のQ1、Q2とQ4の平均実行結果、LargeはデータセットD5上のQ1、Q2とQ4の平均実行結果。
単純に成功したクエリの実行スピードから見ると、Prestoが3倍以上速いものの、メモリーを一番大きく消費し、OutOfMemoryで失敗することが多かったです。一方、Spark SQLとHive on Tezは実行スピードが近いが、Hive on Tezが最も安定しておりOutOfMemoryも発生しなかった。
3.2 データ規模別の比較
下図は各SQLエンジンのD2~D5の実行時間を示しています。どのデータセットに対するどのクエリでもPrestoが一番速いい結果ですが、データサイズが大きくなると複雑なクエリ(Q3)はメモリー不足で落ちました。また、Spark SQLは大きいデータセット(D4とD5)ではHive on Tezより少し速いが、複雑なクエリ(Q3)ではやはりメモリー不足で落ちることがありました。一方、Hive on Tezは実行スピードは他と比べて速いわけではないですが、すべてのクエリにおいて成功しています。シンプルなクエリ(Q1)については一番速かったです。Insert OverwriteのSQL(Q5)はD4で約45分、D5では約90分となりました。
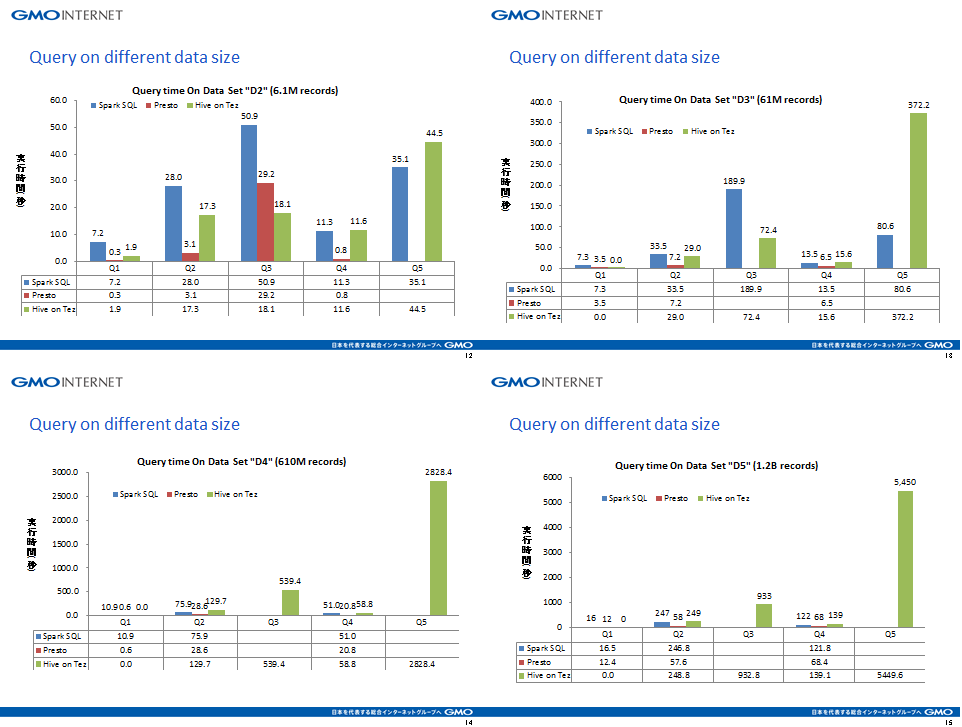
上記の図で数値が空白の場合は、クエリが失敗したことを表す。
3.3 スケーラビリティー比較
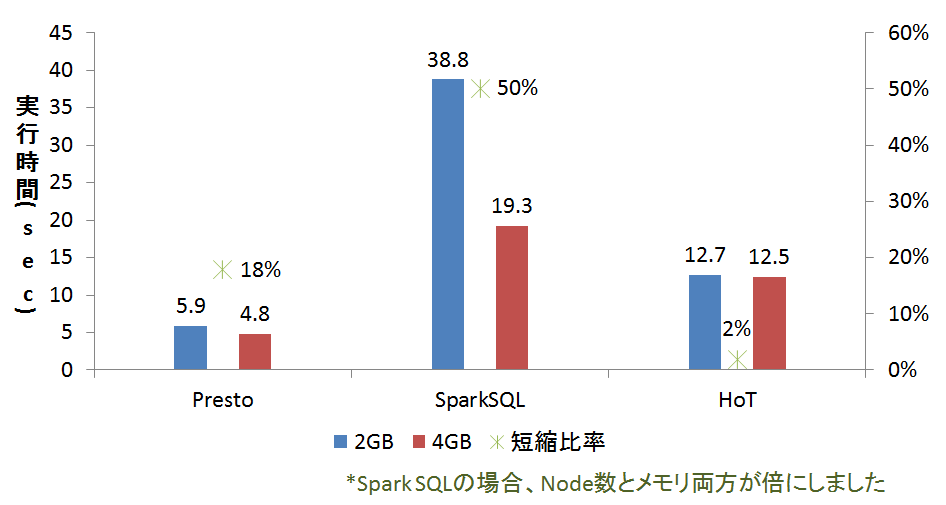
スケーラビリティーは大事なシステム要件であるため、今回のベンチマークテストでも軽く検証しています。メモリーを倍にしたら、実行時間がどう変わるか検証してみました。結果は下記の図となりました。実行時間は3回の平均値としました。Prestoの場合は18%くらい改善するが、Hive on Tezは2%しか改善していない。つまり、Hive on Tezの性能はメモリーにあまり依存していないと考えられます。一方、Spark SQLの場合はメモリーとノード数をそれぞれ倍にしたら50%まで改善したので、ほぼ線形のスケーラビリティーを持つように見えました。
3.4 補足(Presto)
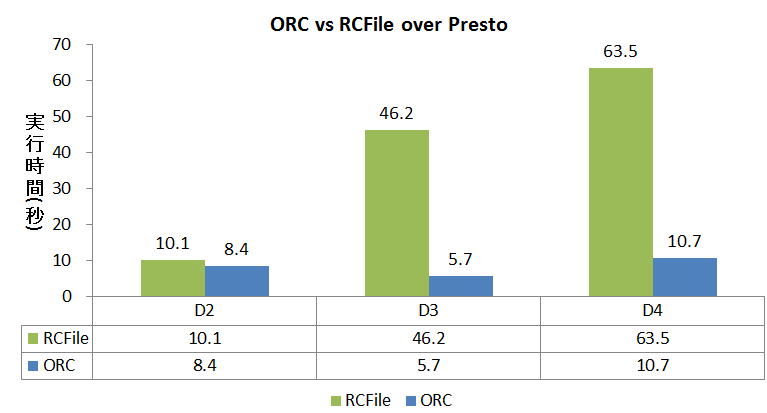
データ格納フォーマットはSQLエンジンの性能に大きな影響を及ぼします。公正を期すため、すべてのデータフォーマットをORCテーブルに統一しましたがPrestoの場合のみ、ORCとRCFile両方の比較テストを行いました。結果は下記の図です。ORCテーブルの場合、実行時間はRCFileより約5倍速い結果に。参考までにCloudera社は、Impala Vs PrestoのベンチマークテストにはORCテーブルではなく、RCFileを使ってベンチマークをしていました。
4、まとめ
4.1 結論
今回、Presto、Spark SQLとHive on Tezの性能に関して、数万件から数十億件までのデータに対し、数パターンのクエリを実行して比較した結果、TAXEL byGMOのシステムではHive on Tezを選定しました。主な理由は三つあり:
(1)スピードがPrestoより遅いが、OutOfMemoryが発生しない(メモリ要求が低い)
(2)大規模データでも、安定して全てのSQL実行を成功した(三つ中に唯一)
(3)Cost Base Optimizerもサポートされ、チューニング余地がある。(但し、今回CBO起用しても数%~10%までしか改善していない)。
また、本システムにおいては、全ての計算資源(CPU、ノード、メモリなど)がYarnに管理される前提もあることで、Hive on TezがYarnとシームレスに連できるのもメリットです。
Spark SQLはOutOfMemoryが発生しますが、別ノードでタスクをリトライするので、ロバスト性が魅力的です。さらに、リソースが倍になると処理スピードも倍になるので、スケーラビリティーが三つの中で一番良い結果となりました。また、ジョブごとに計算資源を指定できるため、リソース利用の柔軟性もメリットです。Spark SQLはただのSQLというだけでなく、スクリプト言語のようにプログラミングを加えて複雑なデータ加工がやりやすいため、実は一部のバッチ処理にSpark SQLを採用しています。
一方、Prestoはリアルタイム性を再優先し、メモリが十分あるシステムではベストな選択になると思われます。ただし、OutOfMemoryが発生すると、ワークノードが全てクラッシュし再起動しなければならないため、運用上の注意が必要です。Prestoはシステム要件であるInsert OverwriteとYarnでのリソース分配をサポートしていないため、採用を見送りました。
Prestoと同様にインタラクティブなクエリができるSQLエンジンとしてCloudera社のImpalaがあり、筆者の利用経験から見ると、Prestoよりさらに高速ですがメモリー消費が激しくOutOfMemoryがよく発生し、Hive MetaStoreとの同期エラーが時々起こることで、いろいろ注意が必要でした。
4.2 チューニングポイント(Basic)
SQLエンジンは当然、パラメータのチューニングで性能に大きく差が出ます。今回のベンチマークにおいては、深いチューニングではなく、なるべくデフォルトまたは推奨設定を利用しました。各SQLエンジンの基本的なパラメータ設定は以下のとおりです:
- Presto
- task.max-memory
- task.shard.max-threads (default: number of CPU cores * 4)
- JVM option: Xmx4G
- Spark SQL<\li>
- executor-memory, executor-cores, num-executors
- spark.sql.shuffle.partitions, spark.sql.codegen
- Hive on Tez
- task.max-memory
- task.shard.max-threads (default: number of CPU cores * 4)
- JVM option: Xmx4G
参考資料
- チューニング参照資料
- https://streever.atlassian.net/wiki/display/HADOOP/Hive+Performance+Tips
- https://spark.apache.org/docs/latest/sql-programming-guide.html
- https://prestodb.io/docs/current/installation/deployment.html
- http://docs.hortonworks.com/HDPDocuments/HDP2/HDP-2.1.1/bk_installing_manually_book/content/rpm-chap1-11.html
- 関連ベンチマークテスト
今回のベンチマーク結果も同時にSlideshareで公開していますので、あわせてご覧ください。リンクはこちら
最後に
次世代システム研究室では、ビッグデータプラットホームの設計・開発を行うアーキテクトとデータ解析エンジニアを募集しています。ご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。
皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD