2020.07.03
HBase から Bigtable へ移行する方法
次世代システム研究室の Y.I. です。
とあるプロジェクトにて CentOS6 系のクラウドサーバーで運用していた HBase を Google Cloud Platform (GCP) 上の Bigtable へ移行しました。その時に得た知見を紹介します。
前提
下記ツールが必要になります。事前にインストールしておきます。
Google SDK (gcloud / gcutilコマンド)
https://cloud.google.com/sdk/install?hl=ja
cbt コマンドインストール
https://cloud.google.com/bigtable/docs/cbt-overview?hl=ja
移行する各種名称を
– HBase テーブル名を my-table
– Bigtableインスタンス名を my-bigtable
– GCP プロジェクト名を my-project
– GCS(Google Cloud Storage) Bucket 名を gs://my_bucket
とします。
移行流れ
移行の流れは以下のようになります。
– HBase テーブル情報を取得する
– Bigtable にテーブル/カラムファミリー/GCポリシーを作成する
– HBase テーブルデータを SequenceFile へ エクスポートする
– SequenceFile を転送する
– SequenceFile を GCS へ アップロードする
– SequenceFile を Bigtable へ インポートする
では、各手順の詳細を説明していきます。
HBase テーブル 情報を取得する
HBase サーバー上にて、 HBase の各 table に対して HBase shell コマンドの describe, get_splits を実行して table 情報を取得します。取得する情報はサーバーのローカルディスク /var/tmp に出力する手順で記述します。
# 出力先Dir作り直し
rmdir /var/tmp/hbase_definition; mkdir /var/tmp/hbase_definition;
# hbase shell describe/get_splits 実行
echo "describe '${TABLENAME}'" | hbase shell > /var/tmp/hbase_definition/${TABLENAME}-schema.json
echo "get_splits '${TABLENAME}'" | hbase shell > /var/tmp/hbase_definition/${TABLENAME}-splits.txt
describe 出力例
describe my-table;
Table my-table is ENABLED
my-table
COLUMN FAMILIES DESCRIPTION
{NAME => 'my-family', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => '86400 SECONDS (1 DAY)', COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true
', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}
※ 「NAME = 'my-family'」を createfamily、 「TTL => '86400 SECONDS (1 DAY)'」 を setgcpolicy で利用します
get_splits 出力例
get_splits 'gmo_rw.hb_article_content' Total number of splits = 8 ["19_da75f", "399_4f95d2e79d4b26ca0ebc42bc8e004e28399", "440_a81f1e25adef62c447a614d09c7c4162440", "501_1f703944ece97a74934bbac098f1da02501", "501_962f111", "505_ba36", "752_0916"] ※ splits ありなしで createtable の指定が変わってきます
Bigtable にテーブル/カラムファミリー/GCポリシーを作成する
Bigtable の操作は全てローカルPCの terminal にて cbt コマンドで実施します。
テーブル (createtable)
splitsなしの場合
cbt -instance my-bigtable createtable my-table
splitsありの場合
cbt -instance my-bigtable createtable my-table splits="19_da75f","399_4f95d2e79d4b26ca0ebc42bc8e004e28399","440_a81f1e25adef62c447a614d09c7c4162440","501_1f703944ece97a74934bbac098f1da02501","501_962f111","505_ba36","752_0916" ※ splits の区切りに空白があるとエラーになります。空白を取り除いたカンマ区切りへ変更してください。
カラムファミリー (createfamily)
cbt createfamily my-table my-family
GCポリシー (setgcpolicy)
cbt setgcpolicy my-table my-family maxage=86400s
HBase テーブルデータを SequenceFile へ エクスポートする
HBase サーバーにて実施します。 HBase から HDFS へデータをエクスポートします。
1テーブルの場合
hbase org.apache.hadoop.hbase.mapreduce.Export "my-table" "hbase_export/my-table"
複数のテーブルの場合
# 対象テーブル
arr=("table01" "table02" "table03" ....)
# export
for i in ${arr[@]}; do echo $i; hbase org.apache.hadoop.hbase.mapreduce.Export "${i}" "hbase_export/${i}"; done
SequenceFile を転送する
エクスポートしたデータを HDFS からローカルディスクへコピーしたのち gcloud/gcutil コマンドが使えるサーバーへ転送します。
HDFS からローカルディスクへコピー
# ローカルDIR作り直し rmdir /var/tmp/hbase_export; mkdir /var/tmp/hbase_export; 1テーブルの場合 hdfs dfs -get "hbase_export/my-table" "/var/tmp/hbase_export/my-table"
複数のテーブルの場合
# 対象テーブル
arr=("table01" "table02" "table03" ....)
# HDFS -> ローカルディスクへコピー
for i in ${arr[@]}; do echo $i; hdfs dfs -get "hbase_export/${i}" "/var/tmp/hbase_export/${i}"; done
# 転送
gcloud/gcutil コマンドが使えるサーバーにて、 scp などでエクスポートしたファイルを転送します。
scp -r from-server:/var/tmp/hbase_export /var/tmp/
SequenceFile を GCS へ アップロードする
gcloud/gcutil コマンドが使えるサーバーにて、 GCS(Google Cloud Storage) へアップロードします。
# GCP の Projectを設定 gcloud config set project my-project # 転送したDIR cd /var/tmp # GCS へアップロード gsutil -m cp -r ./hbase_export gs://my_bucket
SequenceFile を Bigtable へ インポートする
gcloud が使えるサーバーにて、Cloud Dataflow を使って GCS 上の Sequence file を Bigtable へインポートします。 Dataflow ではいくつかのテンプレートが用意されており、今回はGCS上の SequenceFile を Bigtable へインポートするため 「GCS_SequenceFile_to_Cloud_Bigtable」テンプレートを利用します。
# 変数設定
TABLENAME="my-table"
# dataflow実行
gcloud dataflow jobs run migration-${TABLENAME} --gcs-location gs://dataflow-templates-asia-northeast1/latest/GCS_SequenceFile_to_Cloud_Bigtable --region asia-northeast1 --staging-location gs://my_bucket/tmp --parameters bigtableProject=my-project,bigtableInstanceId=my-bigtable,bigtableTableId=${TABLENAME},sourcePattern=gs://my_bucket/hbase_export/${TABLENAME}/part*
※ こちらコマンド内容は 下記 GCP Web Console にて GUI で Dataflow job を作り、 command line で表示するとコマンドを組み立てて表示してくれます。
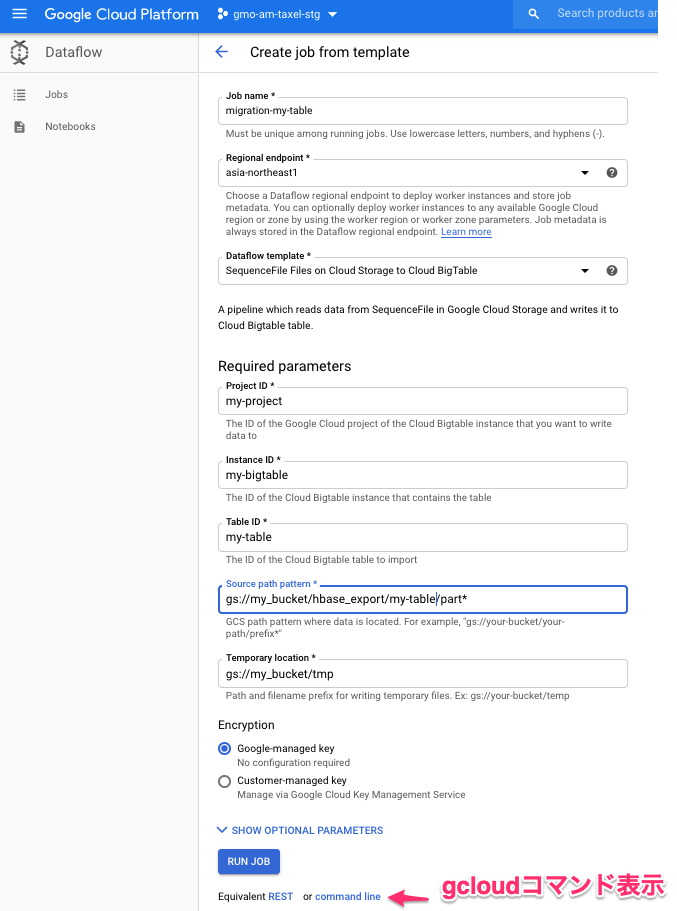
dataflow jobが登録されると gcloud dataflow コマンドが返ってきます。 GCP Web Console にて、 Dataflow job の実行状況を確認して正常終了したら Bigtable へのデータ移行が完了となります。
参考URL
HBase から Bigtable への移行に際して、参考にした情報をまとめておきます。
– HBase から Cloud Bigtable へのデータの移行
https://cloud.google.com/solutions/migration/hadoop/hadoop-gcp-migration-data-hbase-to-bigtable?hl=ja
– Google Cloud SDKインストール
https://cloud.google.com/sdk/docs?hl=ja#rpm
– cbtコマンドインストール
https://cloud.google.com/bigtable/docs/cbt-overview?hl=ja
– Bigtable テーブルの管理 cbtコマンド
https://cloud.google.com/bigtable/docs/managing-tables?hl=ja
最後に
Bigtable を利用するのは初めてでしたが、 GCP のドキュメントは充実していて大きな問題もなくデータ移行できました。Dataflowも使いやすく動作速度も速く移行が楽にできます。目安として記載しておきますが、1000万レコードのテーブルのインポートが数分で完了しました。しかしアプリケーション側は一部ハマって解決までに数日かかったことがありました。その話については別の機会でご紹介できればと思います。
次世代システム研究室では、グループ全体のインテグレーションを支援してくれるアーキテクトを募集しています。アプリケーション開発の方、次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。
皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD


