2025.06.10
AIエージェントの実力を測る方法:Cline と Devin の優秀さは測れるのか
D.M.です。AIエージェント選定時の基準について解説します。
結論ファースト
・モデル+エージェントの性能評価
SWE-Bench Verified が妥当な指標なのではないでしょうか。
・単純評価が難しい箇所1 UI・UXの違い
IDE, Teminal, Cloud (Webブラウザ)の3種がある。
・単純評価が難しい箇所2 コードベースの把握手法
インデックス型と構文解析型がある。
イントロダクション:
AIエージェントの理解に障害となる課題
現状エージェントの数が多すぎる課題があると思います。
ざっと思いつくものを書いてみました。
GitHub Copilot Coding Agent
Cursor Agent Mode
Cline
Windsurf
Claude Code
Codex Agent
Devin
Lovable
…
これら乱立する開発用AIエージェントツールをどのように把握していけばよいのでしょうか。
この記事でやりたいこと
AIエージェントの性能に影響を与えそうな要素を軸にして、ツールを分類して理解できるように、頭に整理しやすい状態を作りたいです。
アジェンダ:2つの軸
1. 性能を評価する評価指標ってあるんでしょうか?
2. 単純な数値比較ができない部分はどのような箇所か?
※特に2は、ツールのUI・UXといった使用感やコードベースの把握力などがあると考えています。
1. 性能を評価する評価指標ってあるんでしょうか?
AIエージェントの開発力を測る観点としては、以下2点を組み合わせと解釈できるのではないでしょうか。
モデル自体の実力
エージェント自体の実力
これらを表す指標としてLLM関連のベンチマークテストが世の中には多数あります。
突然ですがグラレコを用意しました。(社内でAIに絵を描かせるのが流行っています。文字がまだ崩壊しますが、お許しください)
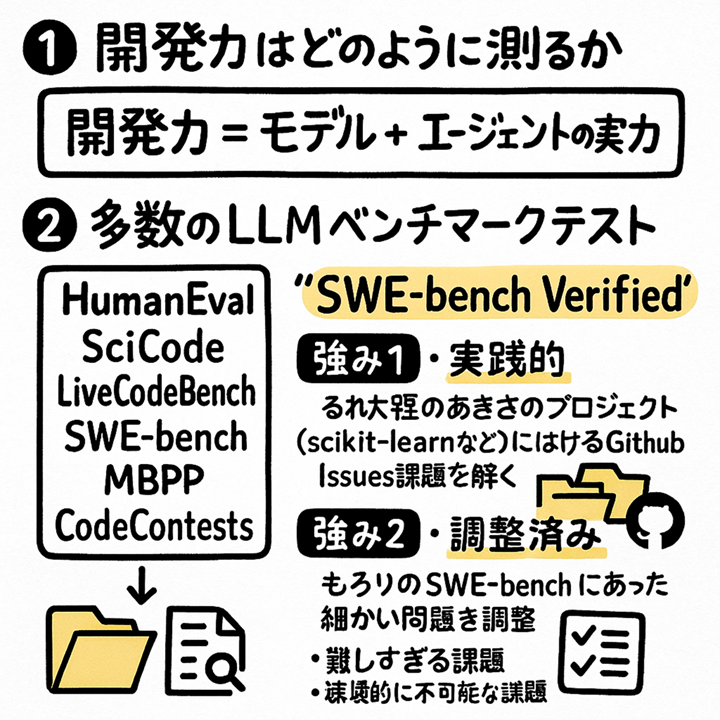
上の図にもあるように、パッと調べただけでも6種類ぐらい出てきました。
SWE-Bench
HumanEval
MBPP
SciCode
LiveCodeBench
CodeContests
多分もっとあると思います。
結論としては、 SWE Bench Verified がおそらく現段階で最も練り込まれたベンチマークテストになるかと思います。
SWE Bench Verified の強み
SWE Bench Verified の強みとして非常に実践的というのがあります。(グラレコでは漢字が崩壊してるんですが)
GitHubの既存プロジェクト scikit-learn など結構有名な大きいプロジェクトで課題 issues をいい感じに切り出してAIに解かせています。 他のベンチマークではアルゴリズムの課題、競技プログラムみたいな課題が多く、必ずしも実践的ではないとも解釈できるようなところがあるのではと思います。この SWE-Bench Verified は500問ぐらいあり、実践的な課題で実力を測っていくという点で改善されています。
Verified ベリファイドがついてる版とついてない版とありまして、ベリファイドがついてるほうが実践に即した調整済みですよという意味です。難しすぎるタスク、条件が充分に提示されていなかったり環境的に困難だったりするような微妙なケースとかでバツになっちゃうような辺をOpenAIが中心になって色々アノテーションつけて分類し相談しながら削っていって新しく作り直したのがこの Verified というテストになります。
※SWE Bench Verified について OpenAI の公式の解説はこちら。
https://openai.com/ja-JP/index/introducing-swe-bench-verified/
※SWE-Bench は元々問題が2,294個ありました。 公式サイトの説明 https://www.swebench.com/original.html
興味深いのが、SWE-Bench Verified が各モデルのプレスリリース時に最も多く参照されているという点です。
現在の点数一覧
公式サイトにはランキング形式でモデルとAIエージェントが列挙されています。(2025年6月現在)
https://www.swebench.com/#verified
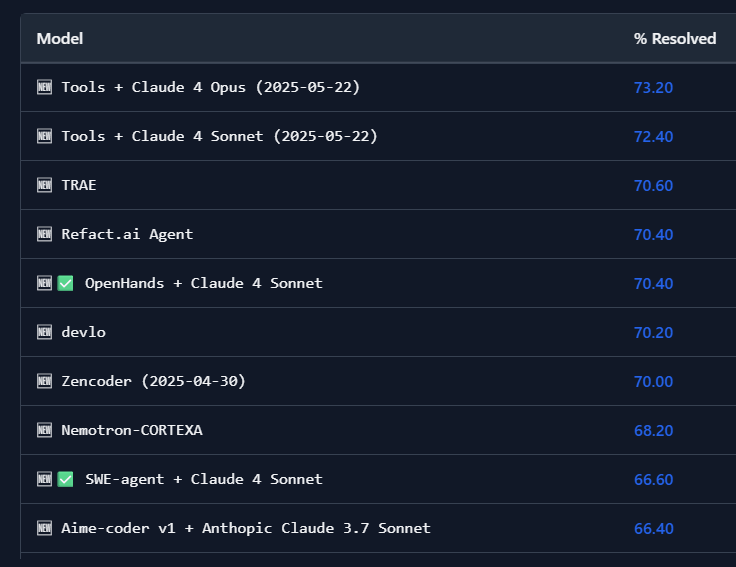
このランキングには「モデル単体」と「モデル+エージェント」の組み合わせが混在しています。
この各社の発表はモデル単位で数値を出しています。逆にエージェントツールはモデルに依存するので両方組み合わせてやって出しています。この辺りはそういうもんなんだぐらいで理解してもらえたらと思います。
開発力が上位のAIエージェントで、OSSのものをいくつか紹介しておきます。
Refact.ai
スコア 70.40%
イギリスのSmall Magellanic Cloud Ai 社のOSS。
VSCodeなどIDE上で動作します。
https://github.com/smallcloudai
Verifiedで70%超のスコアを出したことがブログで公開されています。
https://refact.ai/blog/2025/open-source-sota-on-swe-bench-verified-refact-ai/
こちらによるとこのエージェントは複数のモデルを利用しているようです。
Orchestration model: Claude-3.7
Debug sub-agent — debug_script(): Claude-3.7 + o4-mini
Planning tool — strategic_planning(): o3
OpenHands
スコア 70.40%
OpenHands + Claude 4 Sonnet の組み合わせでの成績です。
https://github.com/All-Hands-AI/OpenHands
いわゆるDevinをオープンソースで実現しようとした OpenDevin というOSSが名前を変えてOpenHandsになっています。
SWE-agent
スコア 66.60%
SWE-agent + Claude 4 Sonnet の組み合わせでの成績です。
https://swe-agent.com/
プリンストン大学とスタンフォード大学の研究者によって開発されたOSSです。
ほとんどすべてのモデルに対応しており、 SWE Bench の Leaderboard ランキングでは多数のモデルのスコアが登録されています。試金石の一つになっていると思われます。
Augment Agent
スコア 65.40%
これは VSCode のエクステンションです。
今後なんか今有料化でやっていきますよみたいなTwitter Xで書かれたんで、これから盛り上がってくるんじゃないかというところです。
Leaderboardに出てこないOpenAIのモデル
ちょっと不思議なのがOpenAIのo3やo4-miniがSWE-Benchの公式ページには出ていないことがありました。
プレスリリースにはすごい点が記載されているのに、なぜSWE-Bench公式には出てないのでしょうか。
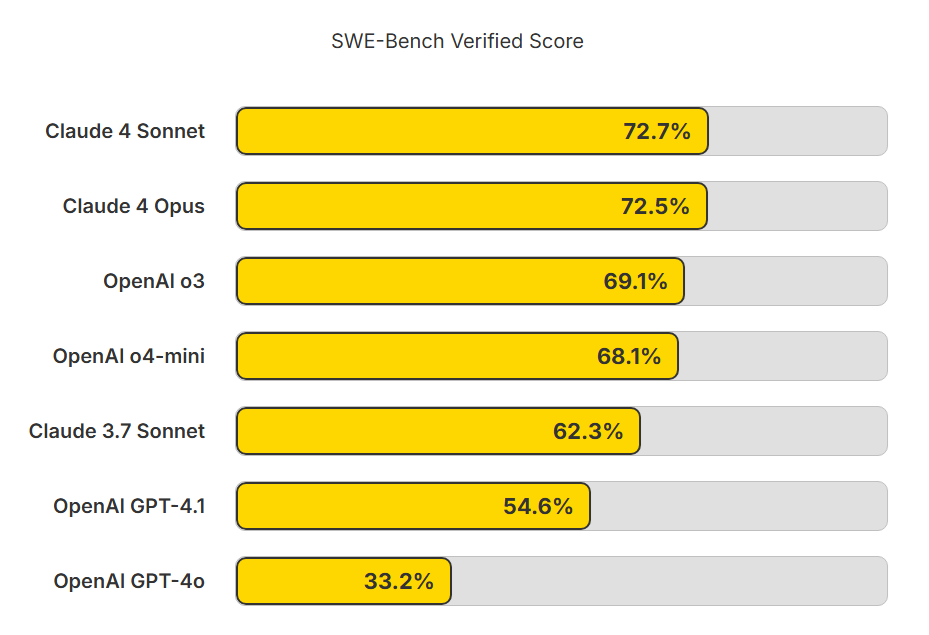
Claude 4 Sonnet 72.7%
Claude 4 Opus 72.5%
OpenAI o3 69.1%
OpenAI o4-mini 68.1%
Claude 3.7 Sonnet 62.3%
OpenAI GPT-4.1 54.6%
OpenAI GPT-4o 33.2%
ここからは推測ですが、理由としてこれらの点が条件付きであるということがあると思います。
例えば、o3, o4-mini のリリース時の記事では以下の文章がありました。
「SWE-bench では、256kの最大コンテキスト長を使用しており、o4-mini の正答率が約3%向上し、o3 の正答率への影響は<1%です。また、当社内のインフラで実行できない23のサンプルを除外しています。」
https://openai.com/ja-JP/index/introducing-o3-and-o4-mini/
また、Claude 3.7 Sonnet のリリース時についても、素で SWE-Bench Verified でやっていくと63.7なんですけど、ちょっと補助するだけですぐ70.3まで取れますよっていう補足が端っこのほうに書いてあったりします。
“custom scaffolding” (カスタム スキャフォールディング) について、微妙にわかりずらいのでChatGPTに推測してもらいました。
ーーーーー
脚注によると、AnthropicはSWE-benchの評価において、単純なプロンプト(ゼロショットまたはフューショット)に加えて、特定のタスク解決戦略 を用いた評価も行っています。この戦略は、モデルが問題解決に利用できる追加の情報や構造を提供する ことを意味していると考えられます。
具体的には、以下のようなものが考えられます。
問題の分解: 複雑な問題をより小さなステップに分解し、モデルが段階的に解決できるように促す。
関連情報の提供: バグ修正に必要なコード箇所や関連するドキュメントの一部など、ヒントとなる情報をプロンプトに含める。
思考プロセスの誘導: モデルに特定の思考プロセス(例: まず問題の原因を特定し、次に修正案を考え、最後にコードを生成する)をたどるように指示する。
画像内の表を見ると、Claude 3.7 SonnetのSWE-benchスコアは 62.3% / 70.3% となっています。脚注によれば、この “/” の後の高い方のスコア (70.3%) が、この「custom scaffolding」を用いた戦略、つまりシステムレベルでの最適化と複数回の試行(system-level optimization and multiple attempts) を行った結果であると説明されています。低い方のスコア (62.3%) は、より標準的なプロンプト手法(例: ゼロショットのCoTプロンプト)によるものと考えられます。
つまり、「custom scaffolding」とは、AnthropicがSWE-benchでClaude 3.7 Sonnetの性能を最大限に引き出すために、標準的なプロンプトに加えて施した、問題解決を補助するための特別な工夫や仕組みと言えます。
ーーーーー
具体的には以下のページになります。
https://www.anthropic.com/news/claude-3-7-sonnet
条件付きとはいえ、この2社は依然として強いモデルを出している状況といえると思います。
LiveCodeBench
次点で LiveCodeBench があります。
LeetCode、AtCoder、Codeforcesなどの競技プログラミングから定期的に新しい問題を収集し、評価データセットを更新しています。既存のベンチマークテストの問題として、モデルが過去問を学習してしまうことがありますが、未学習の問題を定期的に追加することでデータの汚染問題に対応しています。結果として、最新のモデルに対しても有効な評価ができるというロジックのようです。
ただ、このベンチマークはモデルの実力のみを計測しているようで、SWE-BenchのようにAIエージェントを計測しているのは載っていませんでした。また、比較的新しいベンチマークであるため(2024年に提案されている)、こちらのスコアを大々的に喧伝しているプレスリリースも少ないようです。
大元の論文: http://arxiv.org/abs/2403.07974
Leaderboard もありますので、気になる方はこちらもチェックしてみてください。
https://livecodebench.github.io/leaderboard.html
Terminal-Bench
https://www.tbench.ai/
1点、注目しているベンチマークに Terminal-Bench があります。
こちらは Claude Code や Codex CLI はコマンドラインのターミナルをベースにしたAIエージェントのベンチマークテストです。
ターミナルにはシンプルゆえに柔軟性があるという点が強みになるという前提のもと、ターミナルでのエージェントに特化したベンチマークになっています。
Claude 4 の発表時に突然取り扱われたのですが、Claude Code と Codex CLI の性能を比較する上で重要だったものと思われます。
https://www.anthropic.com/news/claude-4
1. 性能を評価する評価指標ってあるんでしょうか?の結論
・モデルとエージェントの実力は、現段階では SWE-Bench Verified で確認するのがよさそう。
2. 単純な数値比較ができない部分はどのような箇所か?
次がちょっと数値評価が難しそうなところで、以下2点を取り扱っていきます。
・UI・UX的な観点での優位性
・コードベースの把握手法の優位性
UI・UXの違いによる優位性
機能面では、全ツールが基本的なこのソフトウェア開発フローができる状態にあると思います。
プロンプトで指示→実装→テスト→コミットプッシュみたいなところはある程度できます。
ただ、その画面の出し方、UI・UX的な使いやすさは差があります。
(またChatGPTにグラレコを起こしてもらいました)
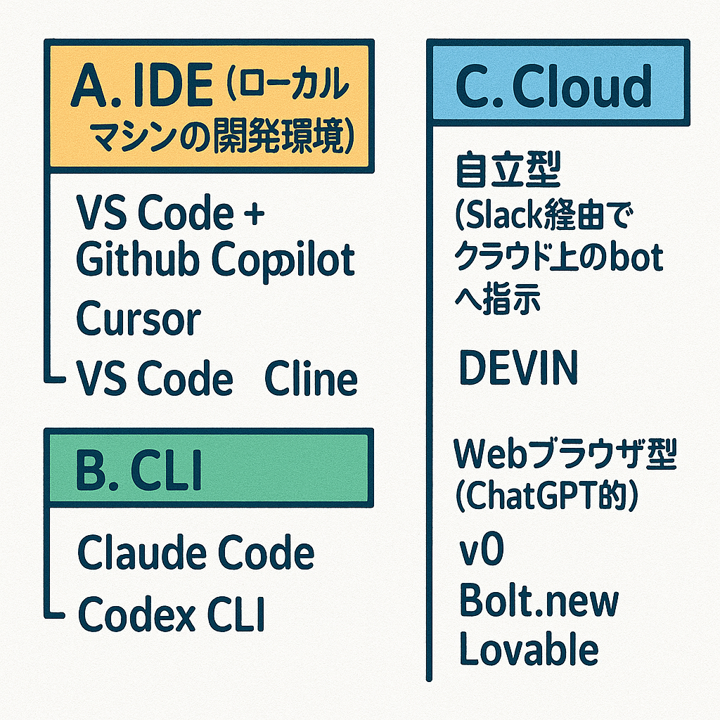
A. IDEベース(VSCodeプラグイン)
GitHub Copilot
Cursor
Cline
このAのIDEの強みとしては、これ基本的に開発者の皆さんが普通に使ってる開発環境なので、導入が非常に簡単というのがあります。GitHub Copilot は弊社グループでも数年前から利用実績がありますし、世間的にもものすごい普及しました。
加えて、モデルが定額制という点がすごくいいよねって言ってる方がちらほらおり、世の中的にコストメリットという点で支持されているという印象があります。逆にIDEベースのClineは現状実質API課金のみのため、やっぱりコストがいつの間にかさんでいく(1日で1000円以上という単位)、これがGitHub CopilotやCursorは月額19ドル(2600円)、30ドル(4500円)みたいな世界なので、ある程度安心して腰を据えて利用できるというのが主流の意見と思います。
B. コマンドラインターミナル
Claude Code
Codex CLI
主流のIDEに対抗してなのか、なぜか本家OpenAIとAnthropicが突然ターミナルのAIエージェントアプリをリリースしました。
25年3月 Anthropic Claude 3.7 Claude Code
25年4月 OPenAI o4-mini Codex CLI
これ両方ともターミナルで使うチャットのアプリで、1行でインストールできる非常に手軽なものです。
コマンドラインを叩きながら、該当フォルダのコード把握、ソースコードの実装やテストなどをバキバキ進められるようなツールになっています。
私は社内の小さいPythonのツールをいじることがあるんですが、わざわざ大きいIDEを立ち上げるってよりかはコマンドラインで軽く修正するだけだったりするので、特にこのCLIのツールが結構十分に対応できているというのがあり、個人的にはこれらがとても気に入っています。
C. クラウド型
Devin
Bolt.new
Lovable
v0
Slack経由だったりブラウザのチャットを入り口にして、クラウド上にある仕組みに出して全部お任せして、開発を進められます。
クラウド上のAIエージェントツールの最大の特徴は実行環境自体を持っているという点です。まるでメンバーが増えたかのように、自分のローカル環境では別の作業をすることができます。IDEやTerminalではAIのやってくれた結果ファイルがすぐ読めるので、一般的なペアプログラミングに近いようなユーザー体験になるっていう特徴があり、この点でUXが全く異なります。
UI・UXの優越を数値化することは難しい
現状のUI・UX分類ではローカルIDEが主流ですが、Devinのように丸投げできるというのは非常に魅力的であるため、長期的にみるとクラウドのAIエージェントが主流になっていく可能性が充分あると考えられます。
これらツールの優位性を図る指標は現状ありませんが、実質的な開発力は内部のモデル+エージェントの実力に依存するので、SWE-Benchで上位のものを使いやすい環境を選ぶのが重要になってくると思います。
ただ、Devin自体は上述のSWE-Benchのランキングには出てきません。(数値はあるけど数年前のもの)
主観的、体感的な感想を集めていくというのが現実的なアプローチになるのではと感じています。
コードベースの把握方法の違い
大きく分けると以下の2点です。
RAG型
ソースコード全体をインデックス化します。EmbeddingしてVector DBに入れておき、関連するソースコードを検索によって把握する方式です。
これは皆さんもよくご存知のやり方だと思います。
実際のツールを見ると
Gitub Copilot Chat Workspace
Cursor Codebase
Devin
数年前からあるようなツールは基本的には全てのコードをベクトル化して検索するっていう形式をとっています。
AST型
アブストラクト シンタックス ストラクチャー ASTを使ってコード全体を把握します。
やや新しめなツール、Cline や Claude Codeは基本的にはこの構文解析アプローチを取っていて、必ずしもデータベースを持ってるわけじゃないんだけど全体を把握できるっていうことがあると。
Clineの強み
RAGとASTの違いはなんなんじゃと思いまして、Cline の OSS をコードリーディングをさせてグラレコにしました。
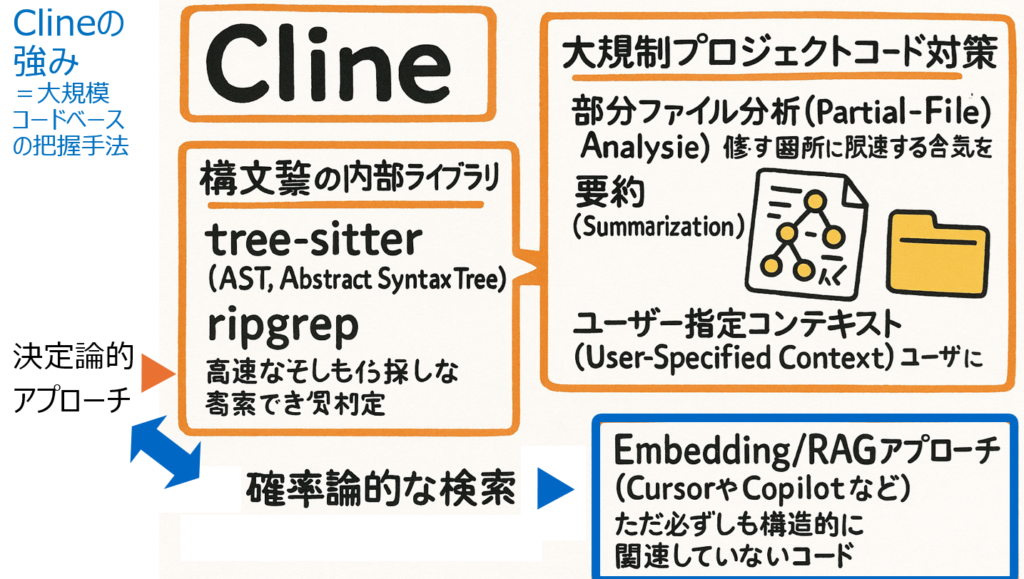
Cline公式ページでも大規模コードベースの把握はうちらめちゃくちゃ得意よとものすごい強く謳っています。
内部の特徴としては Tree Sitter でこのASTの全体の Tree を作ってあげて、ripgrep (多機能で高速なgrep)でファイル検索を行って、コードの関連性を理解しています。
なぜ Cline は大規模コードベースに対して強いのか
大規模コードベースに対しては、上述のAST分析を行ったのちに、さらにその部分分析 Partial Analysis を実行しています。
・フォルダーの特定機能だけを分析
・その特定のフォルダーの要約を随時作って知識を保存。大量のファイルを読まなくても要約を読めば分かる
・ユーザーがAIへこのファイル読んでくださいっていうのを指定
こういったアプローチで効率化を図ることで、従来のツールよりもコードベース全体を理解できるとうたっています。
コードベースRAGは何が問題なのか
ここからは仮説を含みますが、以下のようにRAGの問題点を解釈しています。
エンべディングによるインデックス検索は、検索にヒットしたベクターは関連性があるっていうのをコサイン類似度の数値で近い順に並べてるだけなので、あくまで確率が高いものが上がっている状態になります。確率的に近い=論理的に意味があるだろうっていう推測の元にやっている。
Clineの方は逆にこのもう構造的な理由付けをして決定論的にこれは近いっていういうのを決めてかかってる。
だから2つのアプローチが違うので別の意味での精度を上げられる。
コードベース把握手法の優越を数値化することは難しい
ASTは新しめのツールが採用していますが、今後主流になっていくかはまだわかりません。
これは仮説ですが、例えばスパゲティコードの場合、そもそも構造がめちゃくちゃなんで、ASTはまともな作れないのではと思ったりします。文脈レベルで紐付けられるRAGアプローチの方がもしかしたら有効な可能性はあるのではと思ったりしています。
加えて、難しいところとして、このソースコード把握力というのは直接的に数値化ができていないと思います。一方、間接的な意味では、SWE-Benchの点が高い場合は関連コードの把握ができていることを示すと解釈できるともいえると思います。このあたりについては今後も議論をチェックしていきたいと思いました。
2. 単純な数値比較ができない部分はどのような箇所か?の結論
・UI・UX的な観点での優位性
・コードベースの把握手法の優位性
これらを数値化するものは現段階ではないため、主観的な経験と他の利用者の意見に依存して判断していく他ないと思われます。(間接的にベンチマークの数値に現れるかもしれない)
今日のまとめ
LLM+AIエージェント性能評価
SWE-Bench Verified が優れていると思います。
UI・UX の優位性
分類として、 IDE、 Teminal、Cloud (Webブラウザベース)があります。
実質的な開発力は内部のモデル+エージェントの実力に依存するので、SWE-Benchで上位のものを使いやすい環境を選ぶのが重要になってくると思いますが、全部出ていないので最終的には自分で触ってみたり評判を聞いていくほかないかと思っています。
コードベースの把握手法の優位性
インデックス型と構文解析型があります。
これらの有効性どっちが優れてますみたいのが直接的に数値化できる指標は今のところないので、ここはちょっと今後もう少し調べつつSWE-Benchを代替的に評価に利用することや実際の環境で成果が出るかを検証していくクリアにしていく必要があるかなと思っています。
採用に力を入れています。鋭意募集中
GMOインターネットグループ グループ研究開発本部 次世代システム研究室では、最新のテクノロジーを調査・検証しながらインターネットやロボットに関するアプリケーション開発を行うエンジニア、アーキテクトを募集しています。募集職種一覧 からご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD