2024.10.15
続・GPT-4oで画像解析をやってみた Fine-tuning編
TL;DR
- OpenAIは2024年10月1日に公開した新しいAPIの1つがVision Fine-tuningです。これはGPT-4oの画像認識能力を追加学習(ファインチューニング)できる新機能です。Vision Fine-tuning APIは、最低10枚の画像と期待する返答の学習データを準備するだけで、Web上で手軽に実行と検証が可能です。
- 今回、実験として美雲このはの画像を使ってキャラクターを認識させたり、問題のあるグラフの可視化を指摘させるなどの学習をさせて、期待通りの回答を得ることができました。なお、人物や顔、CAPTCHAなど利用規約に違反する画像は学習できない点に注意が必要です。
はじめに
こんにちは、グループ研究開発本部・AI研究室のT.I.です。OpenAIでは、2024年10月1日に、いくつかの新しいAPIをリリースしました。今回のBlogでは、その1つであるvision fine-tuning API (Introducing vision to the fine-tuning API)について解説します。
これはGPT-4oに画像を入力して、期待する回答を追加学習させ、GPT-4oを自分好みにカスタマイズできる機能です。例えば、画像に写っている物体の名前を回答させるような学習が可能です。公式サイトで紹介されている例は、次のようなものです。
{
"messages": [
{ "role": "system", "content": "You are an assistant that identifies uncommon cheeses." },
{ "role": "user", "content": "What is this cheese?" },
{ "role": "user", "content": [
{
"type": "image_url",
"image_url": {
"url": "https://upload.wikimedia.org/wikipedia/commons/3/36/Danbo_Cheese.jpg"
}
}
]
},
{ "role": "assistant", "content": "Danbo" }
]
}

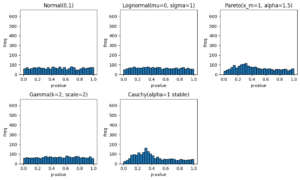
GPT-4oのFine-tuningを試してみる:「美雲このは」をご存知でしょうか?
ConoHa by GMOとは、レンタルサーバーやVPNなどを提供するホスティングサービスです。シンプルなプラン構成と低コストであることが特徴です。最近では、ブラウザだけで簡単に画像生成AIを利用できる「ConoHa AI Canvas」の提供も開始しました。このサービスの応援団長を務めるのが「美雲このは」です。「このは」は、座敷わらしユーチューバー(このはチャンネル)としても活躍しています。賢いGPT-4oなら当然、「このは」をご存知のはずですよね。
…ご存知ない?そうですか。それでは、GPT-4oに教えてあげましょう。実験として、公開されている壁紙画像を使って、GPT-4oをFine-tuningしてみましょう。とりあえず、壁紙を適当にみつくろってきました。
まず、学習データを作成します。以下のように、画像を変換してjsonl形式で保存します。
import base64
import json
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
with open('conoha_train.jsonl', 'w', encoding='utf-8') as f:
for image_path in glob.glob("conoha/*.jpg"):
base64_image = encode_image(image_path)
url = f"data:image/jpeg;base64,{base64_image}"
system_message = "あなたはconohaに関する質問に答えるAIアシスタントです。"
user_prompt = "この画像に写っているキャラクターは誰ですか?"
expected_answer = "美雲このはです。"
item = {
"messages": [
{ "role": "system", "content": system_message },
{ "role": "user", "content": user_prompt },
{ "role": "user", "content": [
{
"type": "image_url",
"image_url": {
"url": url,
}
}
]
},
{ "role": "assistant", "content": expected_answer }
]
}
f.write(json.dumps(item, ensure_ascii=False) + '\n')
OpenAI platformで、DashboardからFine-tuningを選択して、Createを選択します。

Createという新しいモデルを作成するボタンがあります。すると以下のような表示が出ますので、ベースモデルとしては、gpt-4o-2024-08-06を選択します。
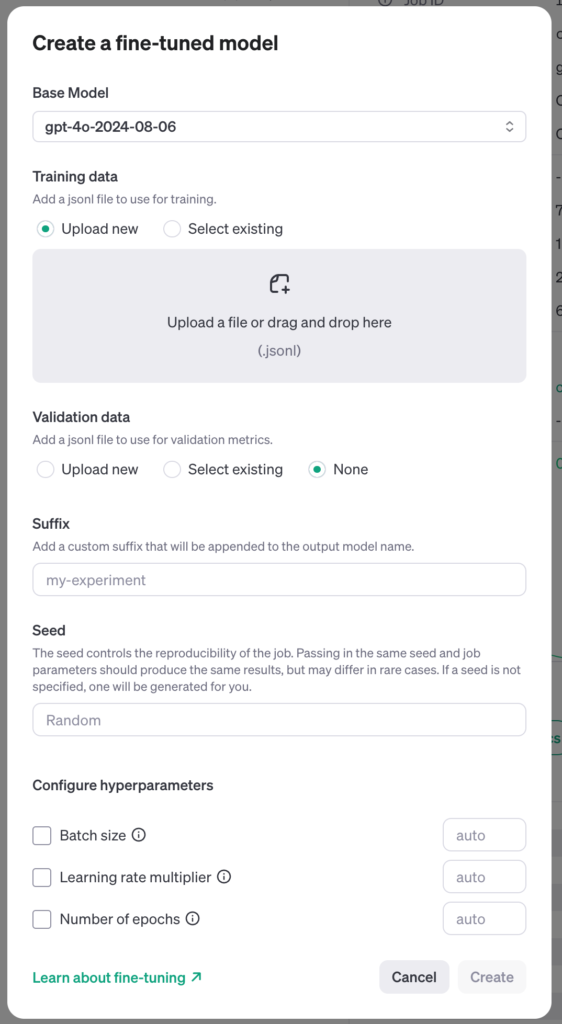
データをアップロードして、学習を開始します。ただし、最低10枚の画像が必要です。実験では、20枚の画像をアップロードしましたが、利用規約に反するとして7枚がスキップされていました。どの画像がスキップされたのかは具体的には不明です。
トレーニング画像には、人物、顔、CAPTCHA、利用規約に違反する画像を含めることはできません。これらの画像を含むデータセットは自動的に拒否されます。
実在する人物のプライバシーの問題などを考慮しているようです。確かに、実験として人物の画像(を生成して)で学習させようとすると、このようなメッセージが出て全て却下されました。
Training file file-… contains 12 examples with images that were skipped for the following reasons: contains people. These examples will not be used for training. Please visit our docs to learn how to resolve these issues. Using 0 examples from training file file-….
一方で、今回の検証やこちらのBlog(OpenAI の Vision Fine-Tuning を試す)のようにキャラクターのイラストなら許容されるようです。アップロードしたデータの検証が完了すると、fine-tuningのジョブが投入されます。今回の場合、fine-tuning自体は5分ほどで完了しましたが、開始までに少し時間がかかることもありました。使用されたトークン数は約3万トークンでした。OpenAIによると、10月中は1日あたり100万トークンまで無料で利用できますが、以降は、100万トークンあたりのコストは$25となるそうです。
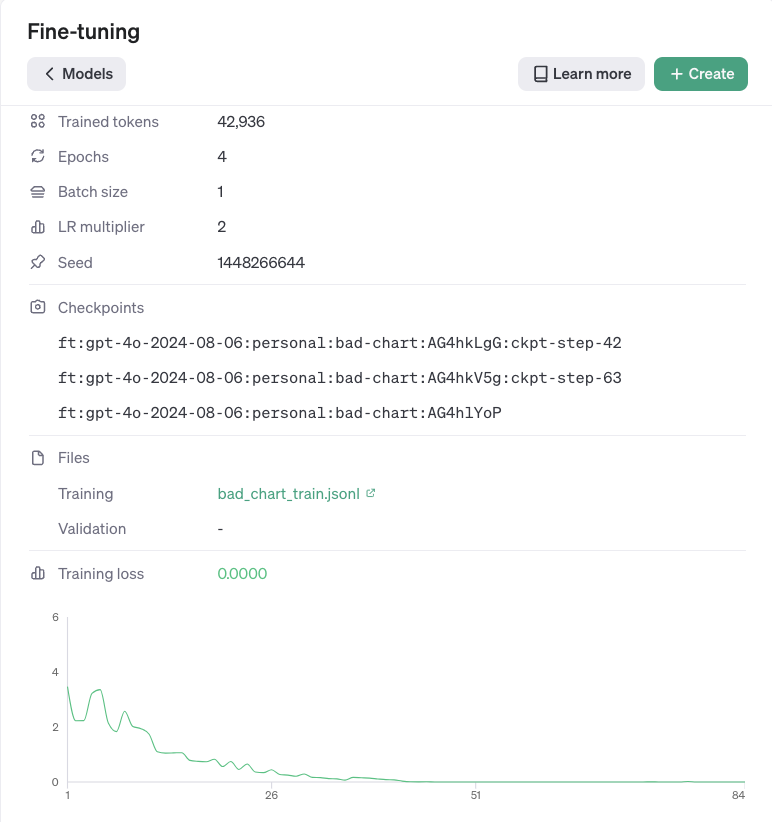
学習結果は、以下のように表示されます。
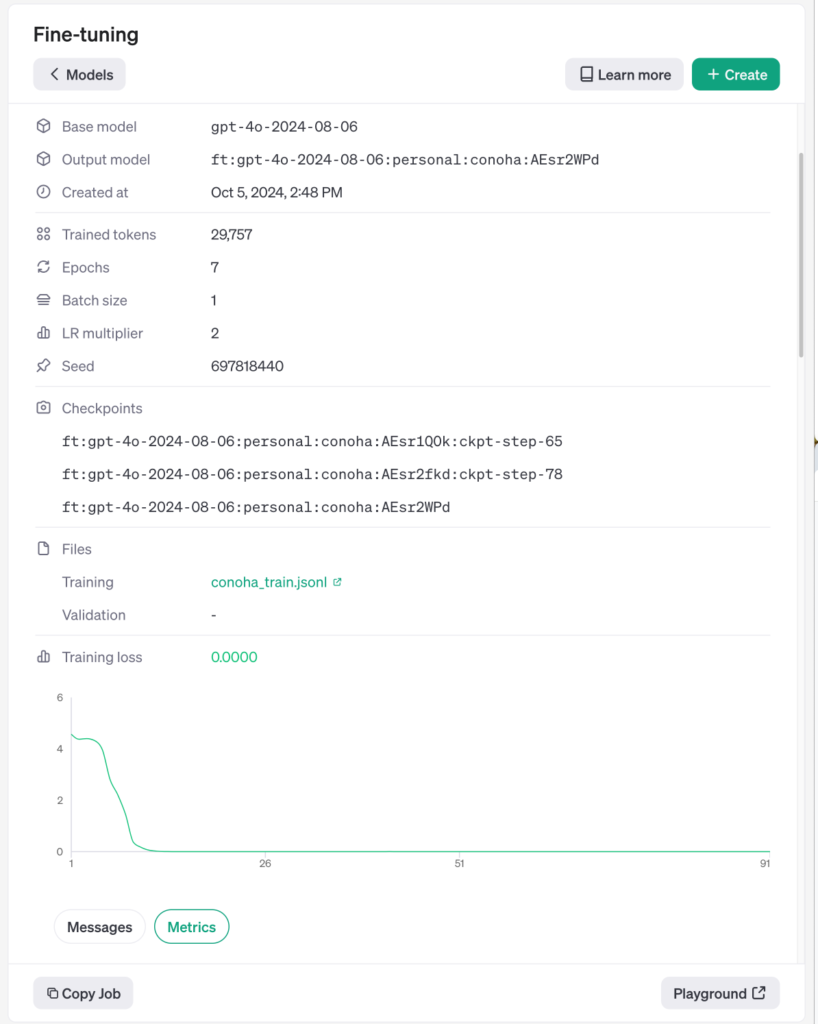
ステップを重ねると損失が減少し、精度が向上していきます。終了後にPlaygroundを選択すると、今回のfine-tuningモデルを試すことができます。学習に使っていないイラストをアップロードして質問しました。
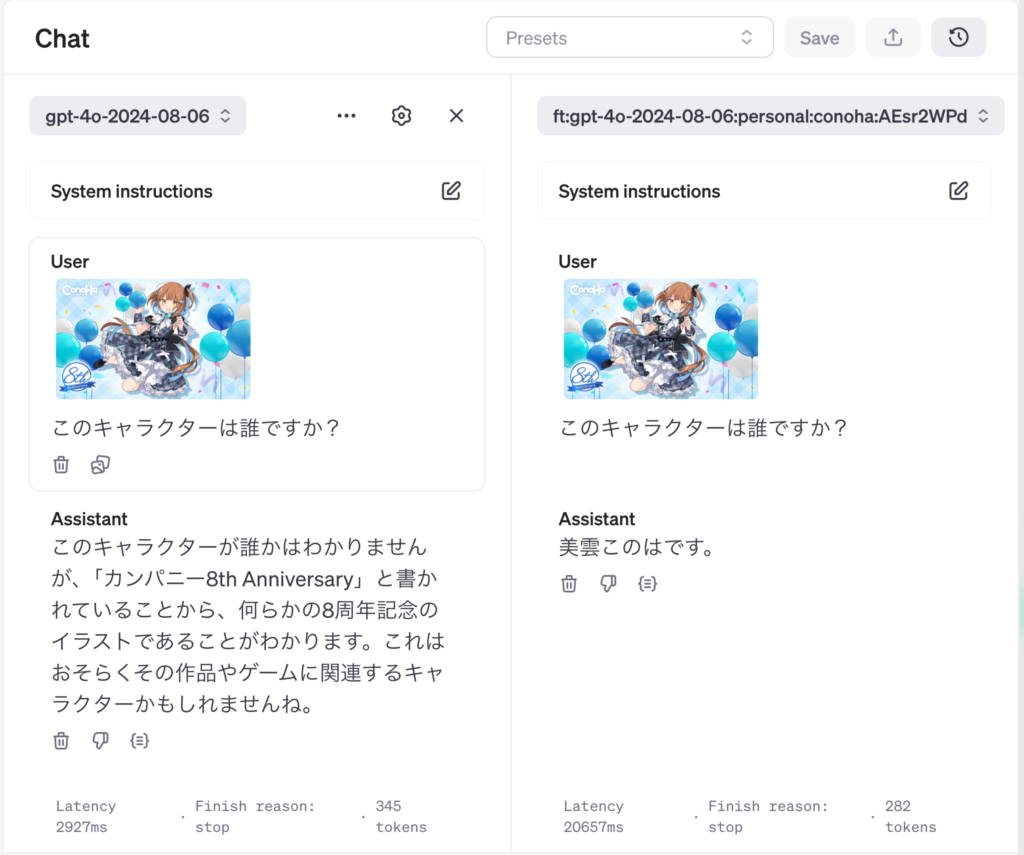
左側にある元のgpt-4o-2024-08-06では、イラストの文字を読み取って推定していますが、正確な回答は得られませんでした。一方で、右側の今回Fine-tuningしたモデルでは、「このは」と正しく回答してくれています。このように、学習後のモデルと元のモデルを自動的に比較してくれるため、追加学習の効果を簡単に確認でき、とても便利です。
なお、コードで実行する場合は、以下のようになります。
import glob
from IPython.display import Image, display
from openai import OpenAI
client = OpenAI()
for image_path in glob.glob("conoha/test/*.jpg"):
display(Image(image_path))
base64_image = encode_image(image_path)
url = f"data:image/jpeg;base64,{base64_image}"
system_message = "あなたはconohaに関する質問に答えるAIアシスタントです。"
user_prompt = "この画像に写っているキャラクターは誰ですか?"
messages = [
{ "role": "system", "content": system_message },
{ "role": "user", "content": user_prompt },
{ "role": "user", "content": [
{
"type": "image_url",
"image_url": {
"url": url,
}
}
]
},
]
model = 'ft:gpt-4o-2024-08-06:personal:conoha:AEsr2WPd'
completion = client.chat.completions.create(
model=model,
messages=messages
)
print(completion.choices[0].message.content)
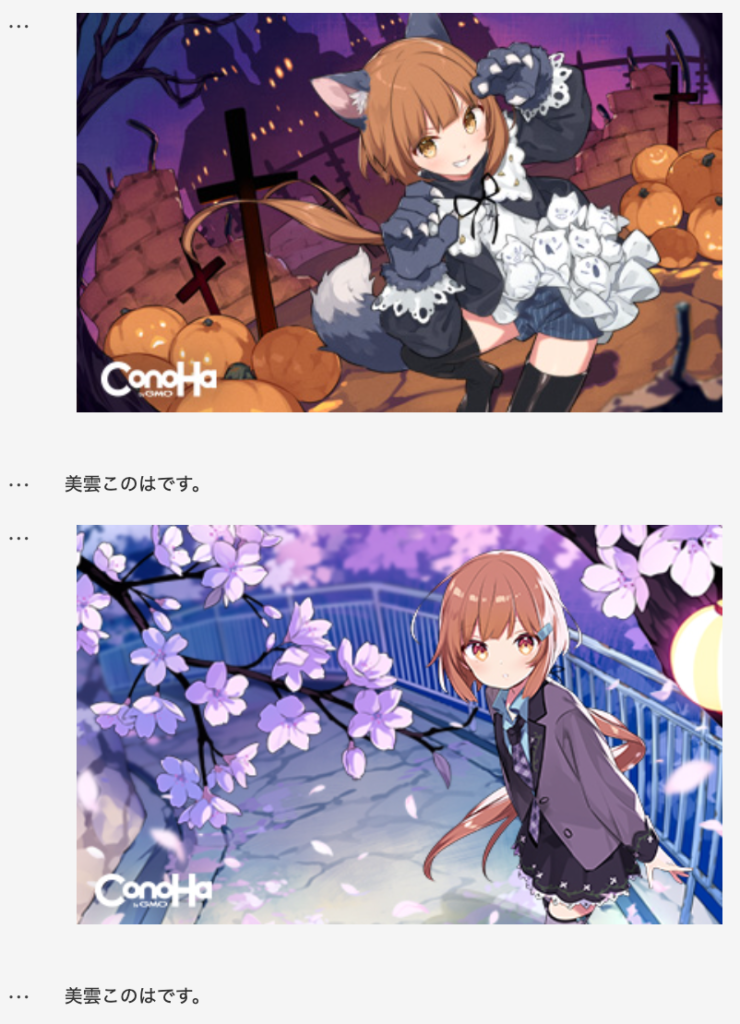
さて、「このは」を無事認識してもらうことに成功しました。
GPT-4oにグラフのダメ出しをしてもらう
次に、何かデータサイエンティストの業務で活用できそうな課題について考えてみます。前回(GPT-4o)や前々回(Turbo with Vision)でデータの分析結果のグラフの画像を与えて、解説をさせてみましたが、細かい数値の読み取りなどは難しいという結果でした。今回、Fine-tuningをしたところで、この精度が良くなる見込みは薄いです。そこで、課題の方向性を変更し、可視化の品質や問題点を学習してもらうことにしました。まずは、間違った可視化方法の例を用意し、注意点を指摘してもらいます。
ダメな可視化その1、棒グラフの途中の省略。棒グラフは棒の長さで数値の大小を比較するので、ゼロから始まらない場合、データの比較が困難で、読み手に混乱を招くので、省略を避けるべきです。
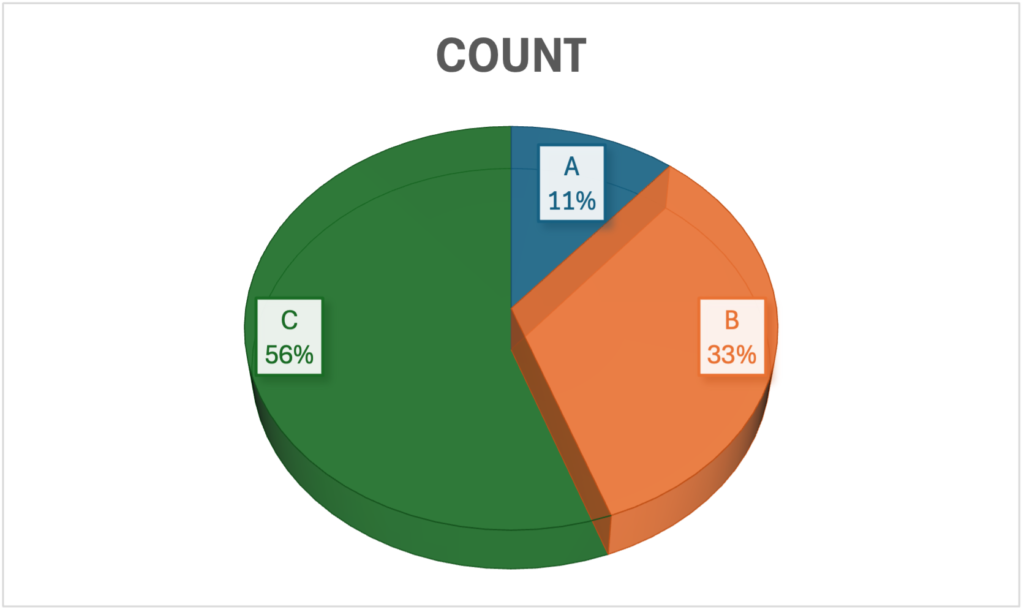
ダメな可視化その2、 3D(3次元)円グラフ。円グラフは数値の比較が難しく分析の可視化として使用には注意が必要で使用しない方が無難です。更にそれを立体化させた3Dグラフは数量の比較が困難でミスリーディングであるのでやめた方が良いです。
それぞれ10枚ずつ、合計20枚の画像を用意して、Fine-tuningを行います。棒グラフに関してはChatGPTを使って、seabornによるサンプルコードを生成させてからy軸の範囲を変更して、棒グラフの途中の省略を行いました。3D円グラフに関しては、寧ろ通常のpythonの可視化ライブラリで作成が面倒だったので、適当にネットの画像検索で見つけたものを利用し、テスト画像としては、Excelで適当なものを作成しました。与えるjsonlの内容は以下のような内容です。グラフの解説への回答として、その可視化の問題点を指摘するように学習させます。
{
"messages": [
{ "role": "system", "content": "あなたはグラフを解説するAIアシスタントです。" },
{ "role": "user", "content": "このグラフを解説してください。" },
{ "role": "user", "content": [
{
"type": "image_url",
"image_url": {
"url": "data:image/jpeg:base64,/..."
}
}
]
},
{ "role": "assistant", "content": "3D円グラフは量を比較するために適切な可視化ではありません。" }
]
}
先ほどと同様に作成した学習データをでアップロードして、DashboardでFine-tuningを行います。今回の学習ではおよそ10分程度で完了しました。
テストとして、それぞれ2枚の画像を用意して、Fine-tuningしたモデルに問い合わせてみました。結果は以下の通りです。
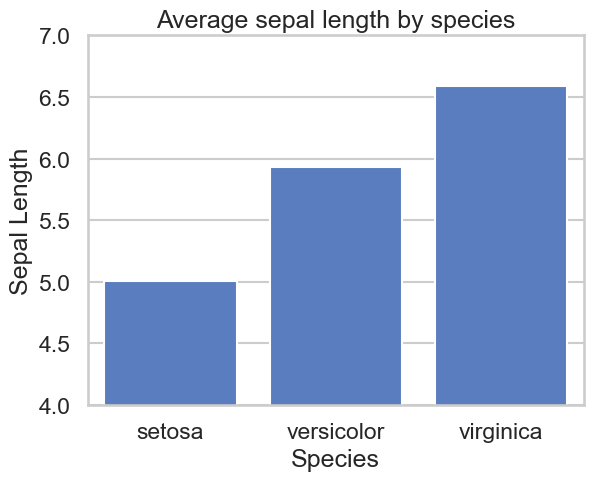
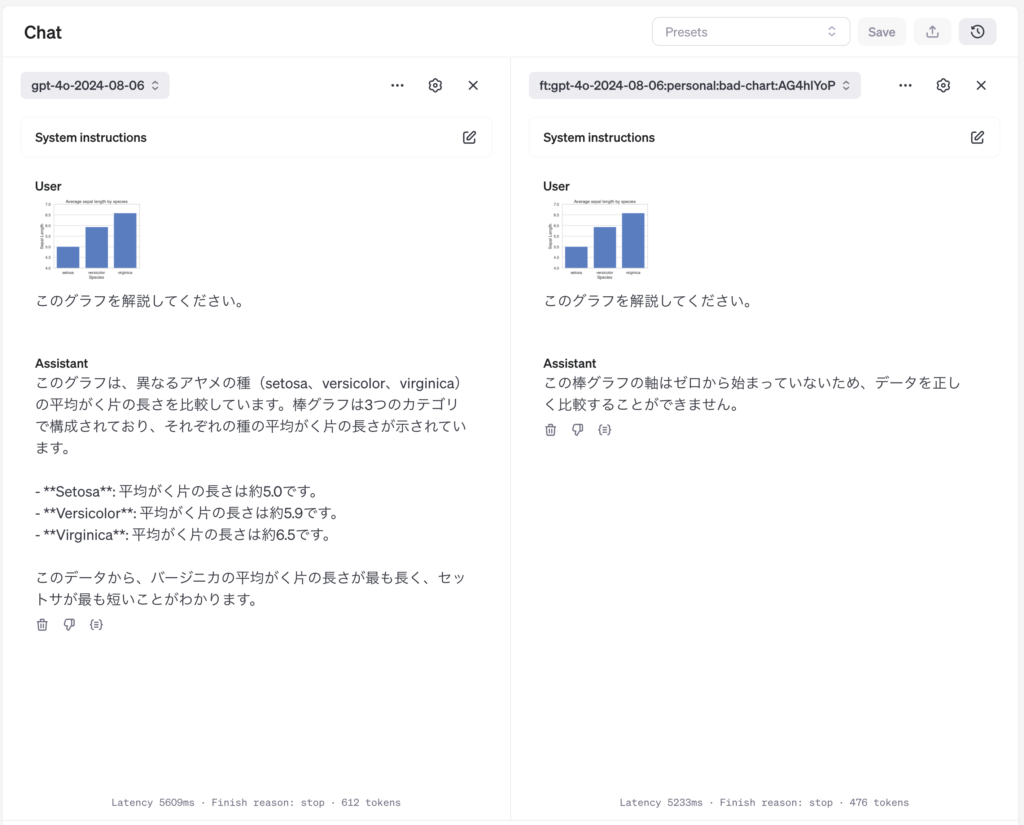
さて、ダメな棒グラフを解説してもらいました。素のGPT-4oでは、真面目に解説して比較してくれています。数値に関しては大体正しいのですが、いかんせん有名なデータセットですので、どこまでグラフから読み取っているのか懸念点はあります。一方で追加学習したものは、最初から不適切だと指摘してくれています。
次に、3D円グラフを解説してもらいました。
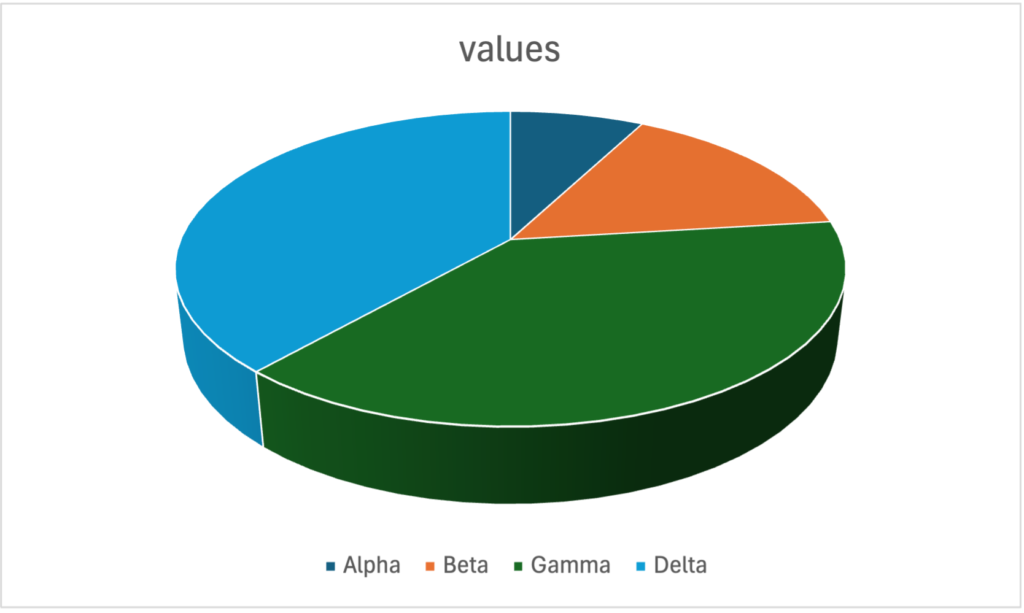
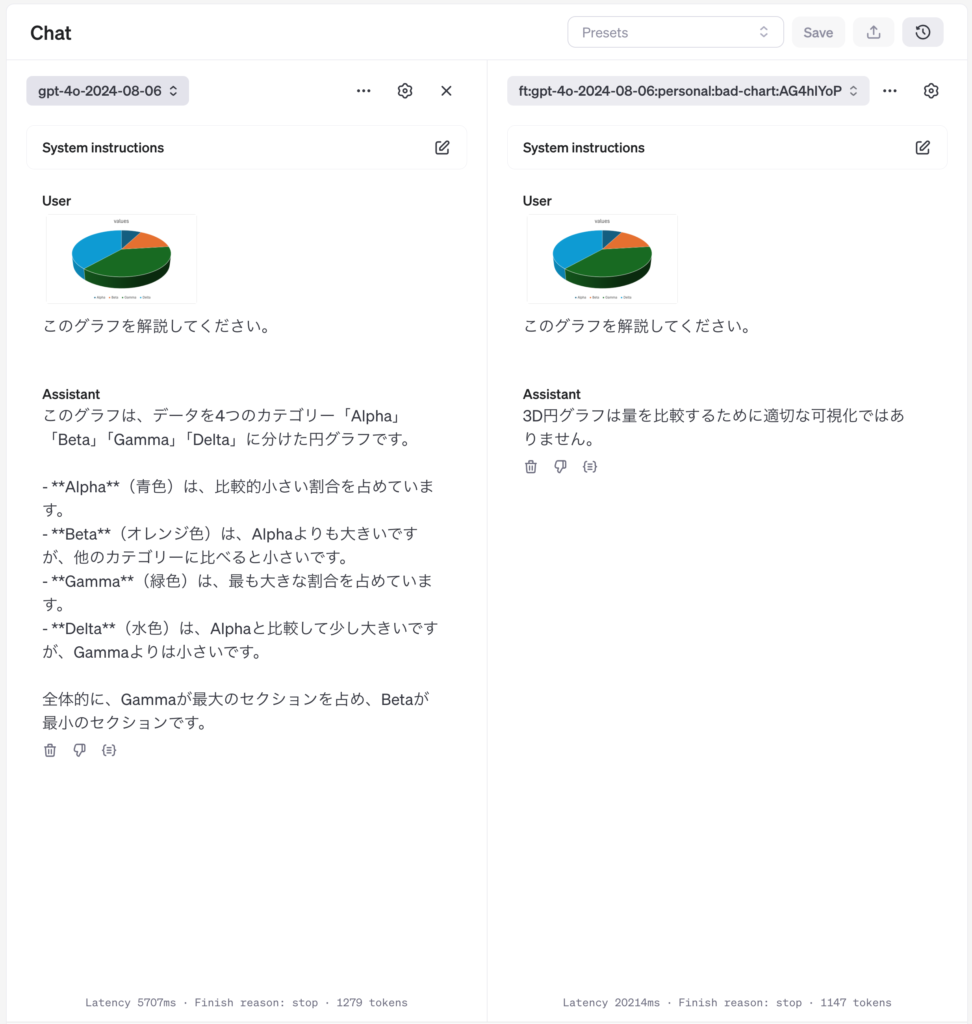
3D円グラフを解説してもらいました。素のGPT-4oでは、真面目に解説して比較してくれています。しかし、DeltaはGammaよりも小さいとする回答は正しくありません。実はGammaとDeltaの数値は同じです。Alpha, Beta, Gamma, Deltaの数値はそれぞれ、10, 20, 50, 50 が正解です。このように自ら3D円グラフが比較のためには不適切であることを露呈しています。また、DeltaはAlphaの5倍もあるので、少し大きいというGPT-4oの回答もやや違和感があります。一方で追加学習したものは、最初から不適切だと指摘してくれています。
まとめ
今回のBlogでは、GPT-4oのVision Fine-tuningを試してみました。使い方は簡単で、必要な画像データを準備したら特定の形式に変換、期待される回答とセットで学習データを作成して、OpenAI platformにアップロードするだけです。悪用を防ぐために、学習データには一定の制限があるので注意が必要ですが、実行する課題によっては、有用なAIアシスタントを作成することができるでしょう。10枚程度のデータセットから手軽に追加学習をできる点が便利ですが、実際の課題に適用する際には、データセットの品質や量と性能の検証が必要かと思います。今回のように特定の問題がある事例を学習させることで、AIアシスタントがその問題を指摘することができるようになるのも魅力的です。
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。皆さんのご応募をお待ちしています。
参考資料
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD