2024.10.02
AWS Lambda で Headless Chromium と Puppeteer を用いた日本語対応 PDF 生成の実践ガイド
はじめに
グループ研究開発本部 次世代システム研究室のL.C.A(海外の出身)です。
最近、会社の業務でユーザー向けの PDF 文書を動的に作成する必要が出てきました。このようなニーズは、請求書やレポート、証明書などでもよく見られます。手作業を自動化することで多くの時間を節約することが可能です。
インターネット上には Headless Chromium を使用した PDF 作成に関する記事が数多くありますが、実際に実装する際には多くの課題がありました。この記事では、AWS Lambda 上で Headless Chromium と Puppeteer を用いて日本語対応の PDF 文書を生成する方法を詳しく解説し、実際に手順を示します。
目次
やりたいこと
クラウド上のサーバレス環境(AWS Lambda)で日本語対応の領収書 PDF ファイルを自動的に生成することを目指します。
特に以下の機能や利点を狙います:
- ユーザーの情報に応じた動的なPDF生成(事前にテンプレート用のHTMLを用意する)
- 日本語フォント対応
- PDF生成時間の削減
前提
- AWSアカウントが作成済みであること
- Lambdaとs3の基本的な知識があること
- Node.jsの基本的な知識があること
- 基本的なHTMLとCSSの知識があること
技術(ツール)選定
- Node.js (v18)
- Headless Chromium
- @sparticuz/chromium
- alixaxel/chrome-aws-lambdaの後継で、AWS lambdaでchromiumを使えるようにする
- Puppeteer: Headless Chromium を操作するための Node.js ライブラリで、ブラウザ操作の自動化が可能
- AWS
- AWS Lambda : サーバレスでスケーラブルな環境を提供し、維持管理コストを削減
- AWS S3 : Lambda で生成した PDF を S3 に保存
コード準備
テンプレート HTML の準備
以下は OpenAI ChatGPT 4o によって生成された領収書の HTML テンプレートです。
このテンプレートを使って、ユーザーの入力に応じた宛名で動的に PDF を生成します。
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>領収書</title>
<style>
body {
font-family: Arial, sans-serif;
margin: 0;
padding: 20px;
}
.container {
max-width: 600px;
margin: 0 auto;
border: 1px solid #ccc;
padding: 20px;
box-shadow: 2px 2px 12px #aaa;
}
.header {
text-align: center;
margin-bottom: 20px;
}
.details {
margin-bottom: 20px;
}
.details p {
margin: 5px 0;
}
.footer {
text-align: center;
margin-top: 20px;
}
</style>
</head>
<body>
<div class="container">
<div class="header">
<h1>領収書</h1>
</div>
<div class="details">
<p><strong>会社名:</strong>株式会社サンプル商事</p>
<p><strong>金額:</strong>¥8,500</p>
<p><strong>日付:</strong>2023年10月25日</p>
<p><strong>宛名:</strong>山田 太郎 様</p>
</div>
<div class="footer">
<p>ありがとうございました。</p>
</div>
</div>
</body>
</html>

lambdaコード
Lambda 関数の実装ロジック:
- エントリーポイントは
lambda handler function→index.mjs - ユーザーの入力に基づいて HTML を生成 →
generateHtml.mjs - Headless Chromium と Puppeteer モジュールを使用して HTML を PDF に変換 →
generatePdf.mjs - 生成した PDF を S3 に保存 →
uploadResultToS3.mjs
プロジェクト構成
/generate-receipts-lambda │ ├── Makefile # 自動化ビルドおよびデプロイツール │ ├── fonts # 必要なフォントファイルを格納 │ ├── NotoSansJP-VariableFont_wght.ttf │ └── ... # その他のフォントファイル │ ├── package.json # Node.js プロジェクトの依存関係とスクリプトの設定 │ ├── index.mjs # Lambda 関数のエントリーポイント │ ├── src # 主なビジネスロジック │ ├── generateHtml.mjs # HTML ファイルを生成するためのロジック │ ├── generatePdf.mjs # HTML を PDF に変換するためのロジック │ └── uploadResultToS3.mjs # PDF ファイルを S3 にアップロードするためのロジック
package.json
{
"name": "generate-pdf",
"version": "1.0.0",
"description": "",
"main": "index.mjs",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"author": "",
"license": "ISC",
"type": "module",
"dependencies": {
"puppeteer-core": "^21.6.0",
"uuid": "^10.0.0"
}
}
index.mjs
"use strict";
import { S3Client } from "@aws-sdk/client-s3";
import { generateHtml } from "./src/generateHtml.mjs";
import { generatePdf } from "./src/generatePdf.mjs";
import { uploadResultFilesToS3 } from "./src/uploadResultFilesToS3.mjs";
const BUCKET = "generate-receipts-test";
const s3 = new S3Client({ region: "ap-northeast-1" });
const errorResponse = (errorMessage) => {
console.error(errorMessage);
return {
statusCode: 500,
body: JSON.stringify({ error: errorMessage }),
};
};
export const handler = async (event, context, callback) => {
const { recipientName, customId } = event;
if (!recipientName || !customId) {
return errorResponse("Error: recipientName or customId is not defined");
}
console.log("Recipient Name:", recipientName);
console.log("Custom ID:", customId);
try {
const htmlContent = await generateHtml(recipientName);
const pdfBuffers = await generatePdf(htmlContent);
if (!pdfBuffers) {
throw new Error("Failed to generate pdf");
}
const { pdfS3Key } = await uploadResultFilesToS3(
s3,
BUCKET,
htmlContent,
pdfBuffers,
customId
);
console.log(`PDF uploaded to S3 with key: ${pdfS3Key}`);
const response = {
statusCode: 200,
body: JSON.stringify({
pdfS3Key,
recipientName,
}),
headers: {
"Content-Type": "application/json",
},
};
callback(null, response);
} catch (error) {
const message = "Error: " + error;
callback(null, errorResponse(message));
}
};
src/generateHtml.mjs
export const generateHtml = async (recipientName) => {
const fixedAmount = "8,500";
const fixedDate = "2023年10月25日";
const companyName = "株式会社サンプル商事";
const htmlTemplate = `
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>領収書</title>
<style>
body {
font-family: Arial, sans-serif;
margin: 0;
padding: 20px;
}
.container {
max-width: 600px;
margin: 0 auto;
border: 1px solid #ccc;
padding: 20px;
box-shadow: 2px 2px 12px #aaa;
}
.header {
text-align: center;
margin-bottom: 20px;
}
.details {
margin-bottom: 20px;
}
.details p {
margin: 5px 0;
}
.footer {
text-align: center;
margin-top: 20px;
}
</style>
</head>
<body>
<div class="container">
<div class="header">
<h1>領収書</h1>
</div>
<div class="details">
<p><strong>会社名:</strong>${companyName}</p>
<p><strong>金額:</strong>¥${fixedAmount}</p>
<p><strong>日付:</strong>${fixedDate}</p>
<p><strong>宛名:</strong>${recipientName} 様</p>
</div>
<div class="footer">
<p>ありがとうございました。</p>
</div>
</div>
</body>
</html>`;
return htmlTemplate;
};
src/generatePdf.mjs
import chromium from "@sparticuz/chromium";
import puppeteer from "puppeteer-core";
const generatePdf = async (htmlContent) => {
if (!htmlContent) {
throw new Error("htmlContent is null or undefined");
}
// Chromiumのグラフィックモードの設定を無効にする
chromium.setGraphicsMode = false;
// Puppeteerを使用してブラウザをランチするための設定
const browser = await puppeteer.launch({
args: [
"--disable-gpu",
"--disable-dev-shm-usage",
"--disable-setuid-sandbox",
"--no-first-run",
"--no-sandbox",
"--no-zygote",
"--single-process",
"--proxy-server='direct://'",
"--proxy-bypass-list=*",
"--font-render-hinting=none",
],
defaultViewport: chromium.defaultViewport,
executablePath: await chromium.executablePath(),
headless: chromium.headless,
ignoreHTTPSErrors: true,
});
const page = await browser.newPage();
// HTMLコンテンツを設定する
await page.setContent(htmlContent, { waitUntil: "networkidle0" });
// PDFを生成
const pdfBuffer = await page.pdf({
printBackground: true,
});
console.log("PDFが生成されました");
// リソースをクリーンアップ
await page.close();
await browser.close();
return pdfBuffer;
};
export { generatePdf };
src/uploadResultToS3.mjs
import { PutObjectCommand } from "@aws-sdk/client-s3";
import { v4 as uuidv4 } from "uuid";
export const uploadResultFilesToS3 = async (
s3,
bucketName,
htmlContent,
pdfBuffer,
customId
) => {
if (!htmlContent || !pdfBuffer) {
throw new Error("HTML content or PDF buffer is null or undefined");
}
console.log("Uploading files to S3...");
// S3にアップロードするためのユニークなキーを生成
const pdfS3Key = `receipts/${customId}/${uuidv4()}.pdf`;
console.log(`PDF S3 key: ${pdfS3Key}`);
try {
// PDFファイルをS3にアップロード
const putPdfCommand = new PutObjectCommand({
Bucket: bucketName,
Key: pdfS3Key,
Body: pdfBuffer,
ContentType: "application/pdf",
});
await s3.send(putPdfCommand);
console.log(`PDF file uploaded successfully: ${pdfS3Key}`);
// S3キーを返す
return {
pdfS3Key,
};
} catch (error) {
console.error(`Error uploading files to S3: ${error}`);
throw new Error(`Failed to upload files to S3: ${error.message}`);
}
};
Makefile
lambda_zip = lambda_function.zip
node_modules_zip = node_modules_layer.zip
font_layer_zip = font_layer.zip
all: prepare zip_lambda_function zip_node_modules_layer zip_font_layer clean
prepare:
rm -rf node_modules nodejs .fonts
rm -f $(node_modules_zip) $(lambda_zip) $(font_layer_zip)
npm install --production
zip_lambda_function: index.mjs
zip -9 -r $(lambda_zip) index.mjs src
zip_node_modules_layer: node_modules
mkdir -p nodejs/node_modules && \
cp -r node_modules/* nodejs/node_modules/ && \
zip -9 -r $(node_modules_zip) nodejs
zip_font_layer:
mkdir .fonts && \
cp -r fonts/* .fonts/ && \
zip -9 -r $(font_layer_zip) fonts
clean:
rm -rf node_modules nodejs .fonts
Lambda Layer 用ファイル準備
Lambda 関数のアップロードサイズには 50MB の上限があるため、Node モジュールや Chromium のサイズが簡単に超えてしまいます。そのため、Node モジュール、Chromium、フォントの部分を Lambda Layer にデプロイすることにします。
Headless Chromium
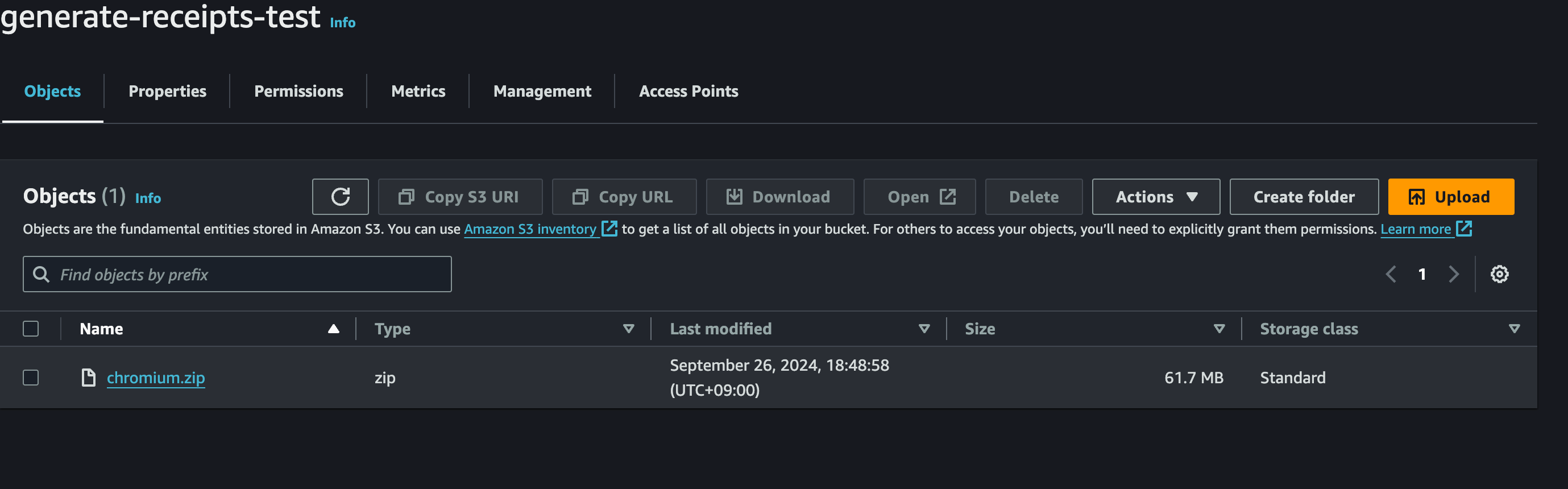
今回使用する@sparticuz/chromium ライブラリでは、GitHub の README に記載された方法を参照して ZIP ファイルを生成できます。
以下のコマンドを実行すると、Chromium フォルダ内に新しい chromium.zip ファイルが生成されます。このファイルを後で Lambda Layer にアップロードします。
git clone --depth=1 https://github.com/sparticuz/chromium.git && \ cd chromium && \ make chromium.zip
フォントファイル
Headless Chromium はデフォルトで英字フォントしかサポートしていないため、他の言語のフォントを使用したい場合は追加のフォントファイルが必要です。今回は Noto Sans Japanese – Google Fonts が提供する NotoSansJP を使用します。ダウンロードして解凍後、NotoSansJP-VariableFont_wght.ttf ファイルを fonts フォルダにコピーします。
AWS作業
S3準備
generate-receipts-test という名前のバケットを作成します。

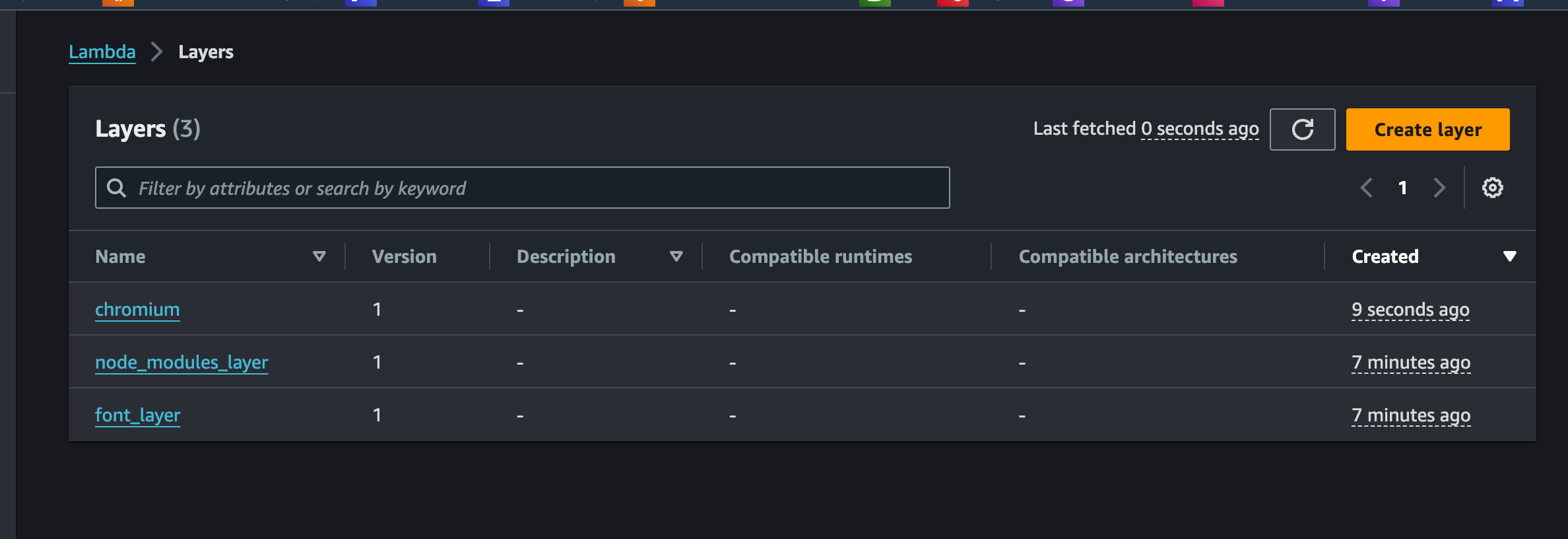
Layer 作成
- 必要なファイルを作成
- すでにMakefileを用意してので、ターミナルで
makeを実行すると、自動的にnode_modules_layer.zip、font_layer.zip、lambda_function.zipファイルが作成されます。
- すでにMakefileを用意してので、ターミナルで
- 先ほど作成した
chromium.zip、node_modules_layer.zip、font_layer.zipに基づいて 3 つの Layer を作成します。- メモ:Layer のアップロードサイズ上限は 50MB ですので、
chromium.zipは一度 S3 にアップロードし、S3 から再度アップロードします。
- メモ:Layer のアップロードサイズ上限は 50MB ですので、
Lambda 関数の設定
generate-receiptsという Lambda 関数を作成します。
generate-receipts関数にLayer を設定します。

- メモリを 1024MB、タイムアウトを 30 秒に設定します。
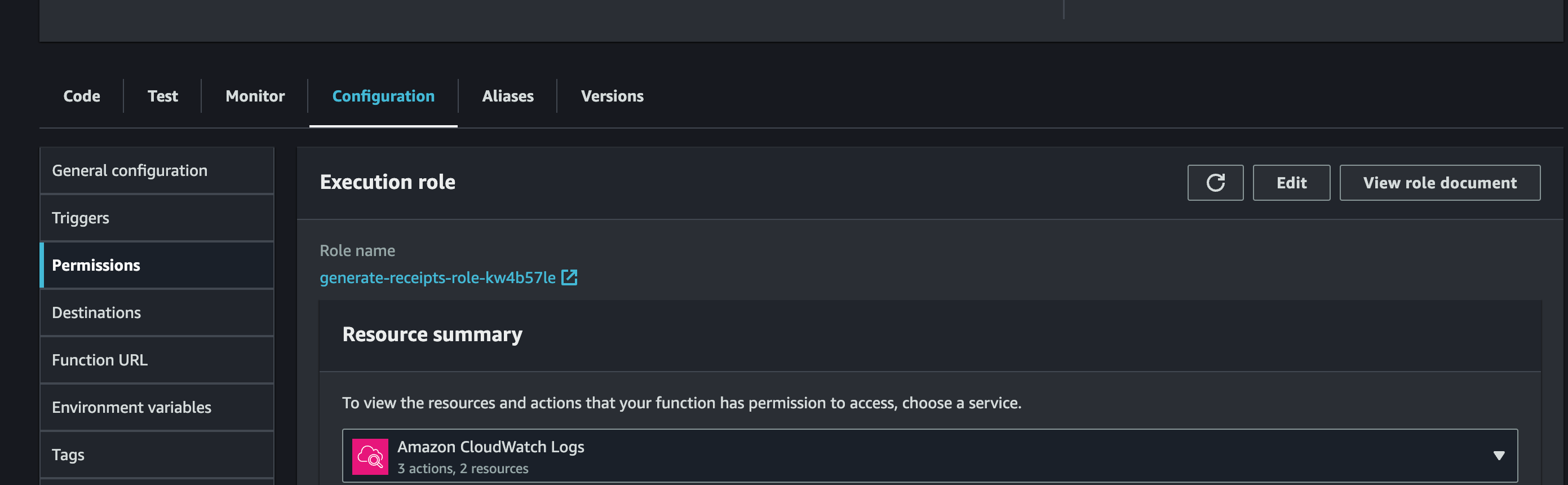
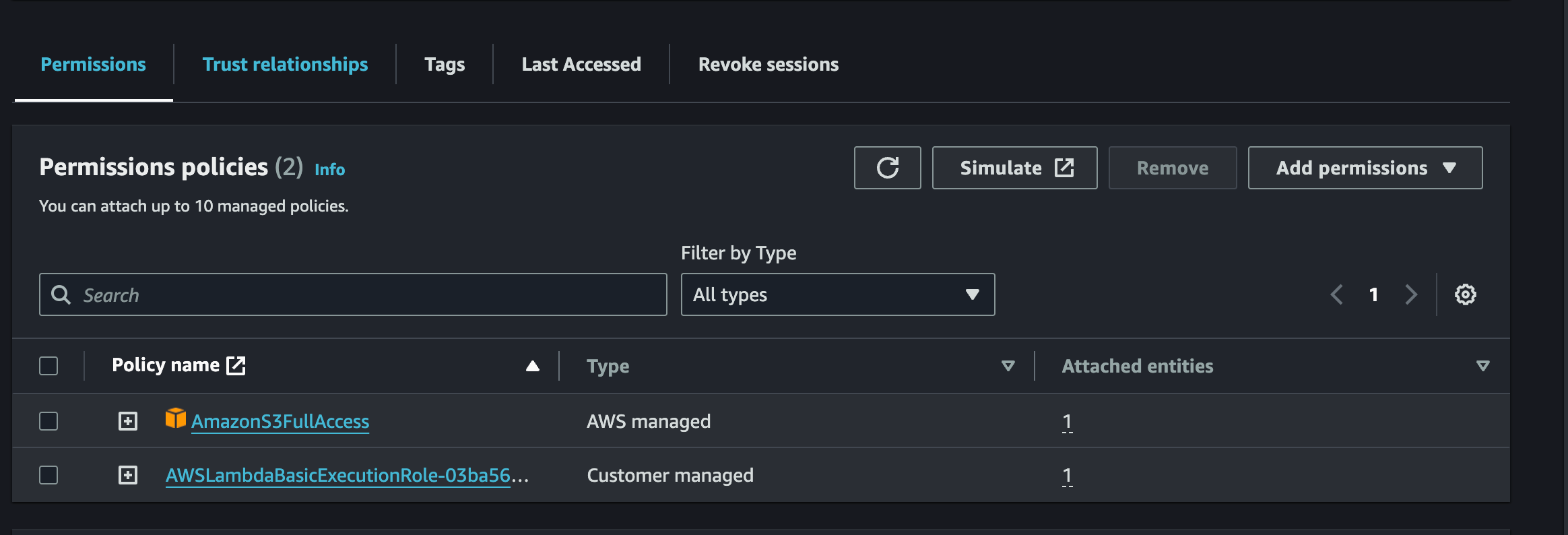
- S3 へのアップロードが必要なため、S3 の権限を設定します。
- IAM ロールに
AmazonS3FullAccessポリシーを追加します(テスト用のため、AmazonS3FullAccessの権限を付与)。
- IAM ロールに
以上ですべての設定が完了しました!テストを開始できます。
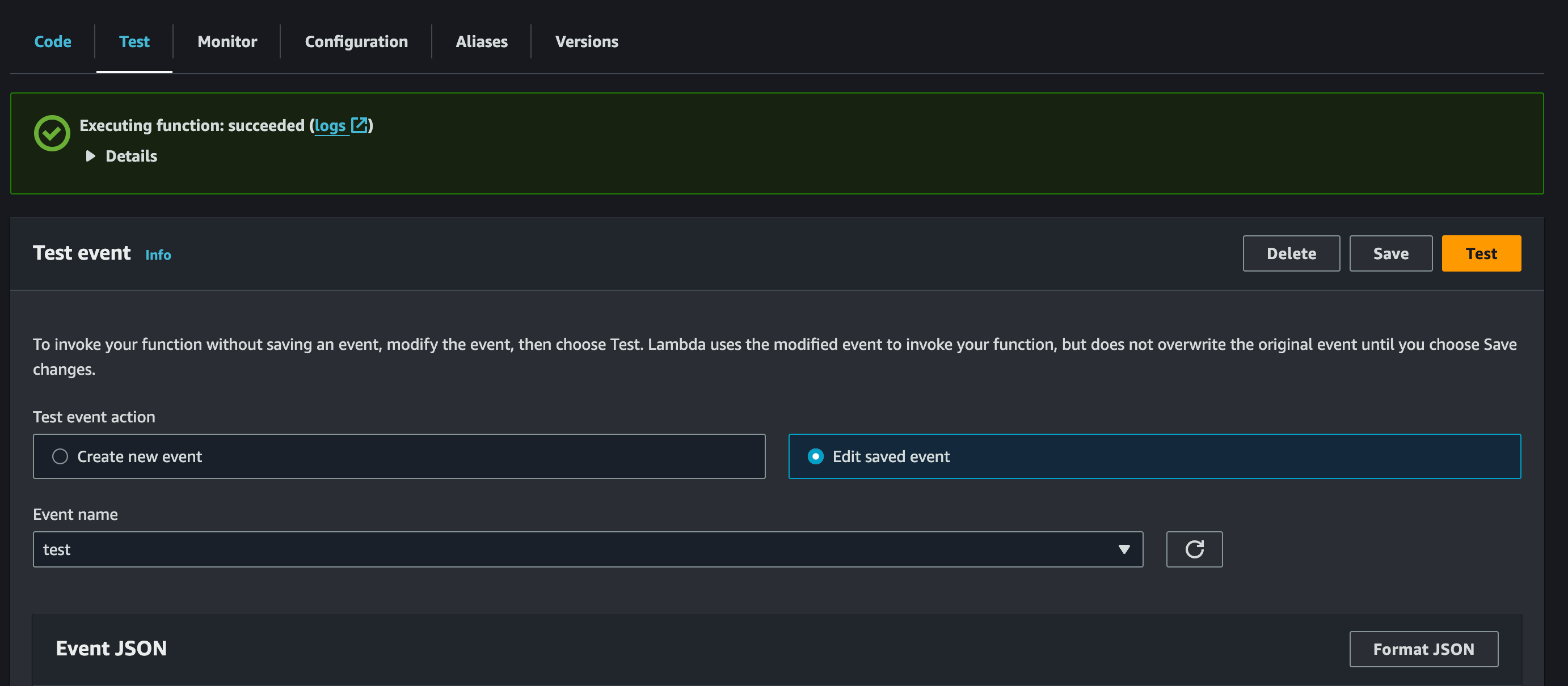
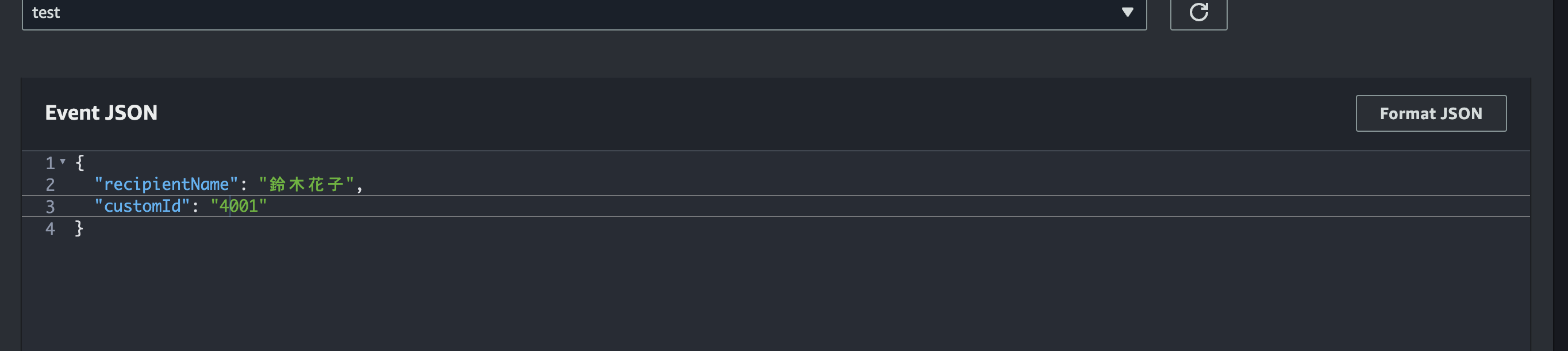
テスト実行
テスト時に JSON を設定し、Test をクリックします。実行が成功すると S3 に PDF がアップロードされ、宛名が設定した入力値に反映されています。
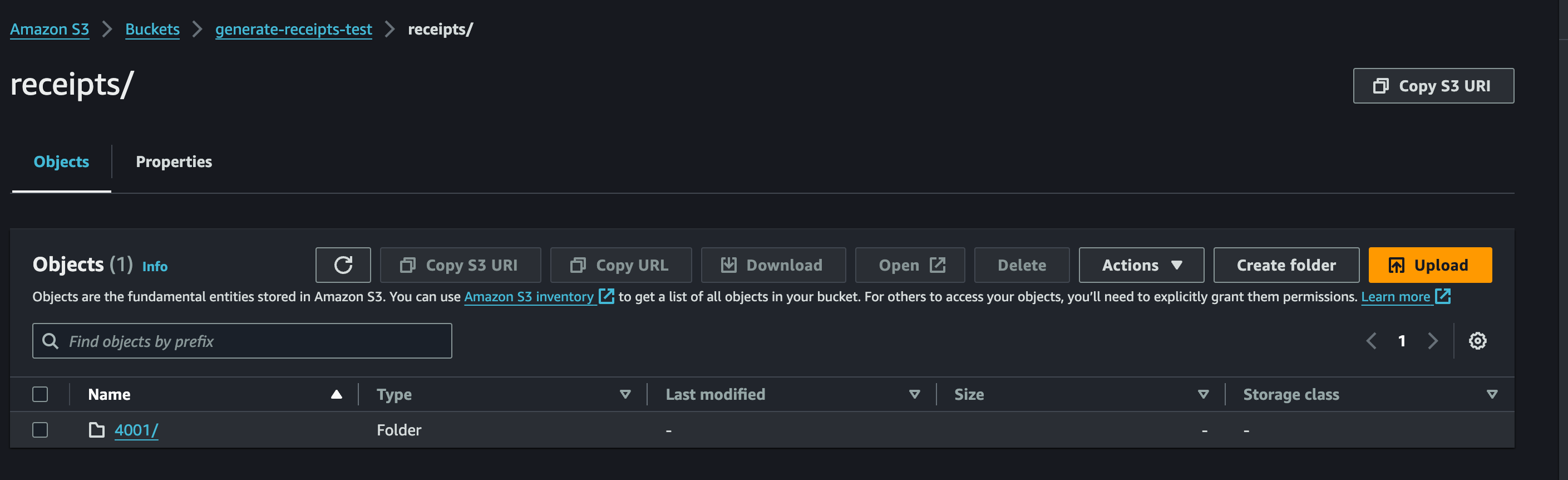
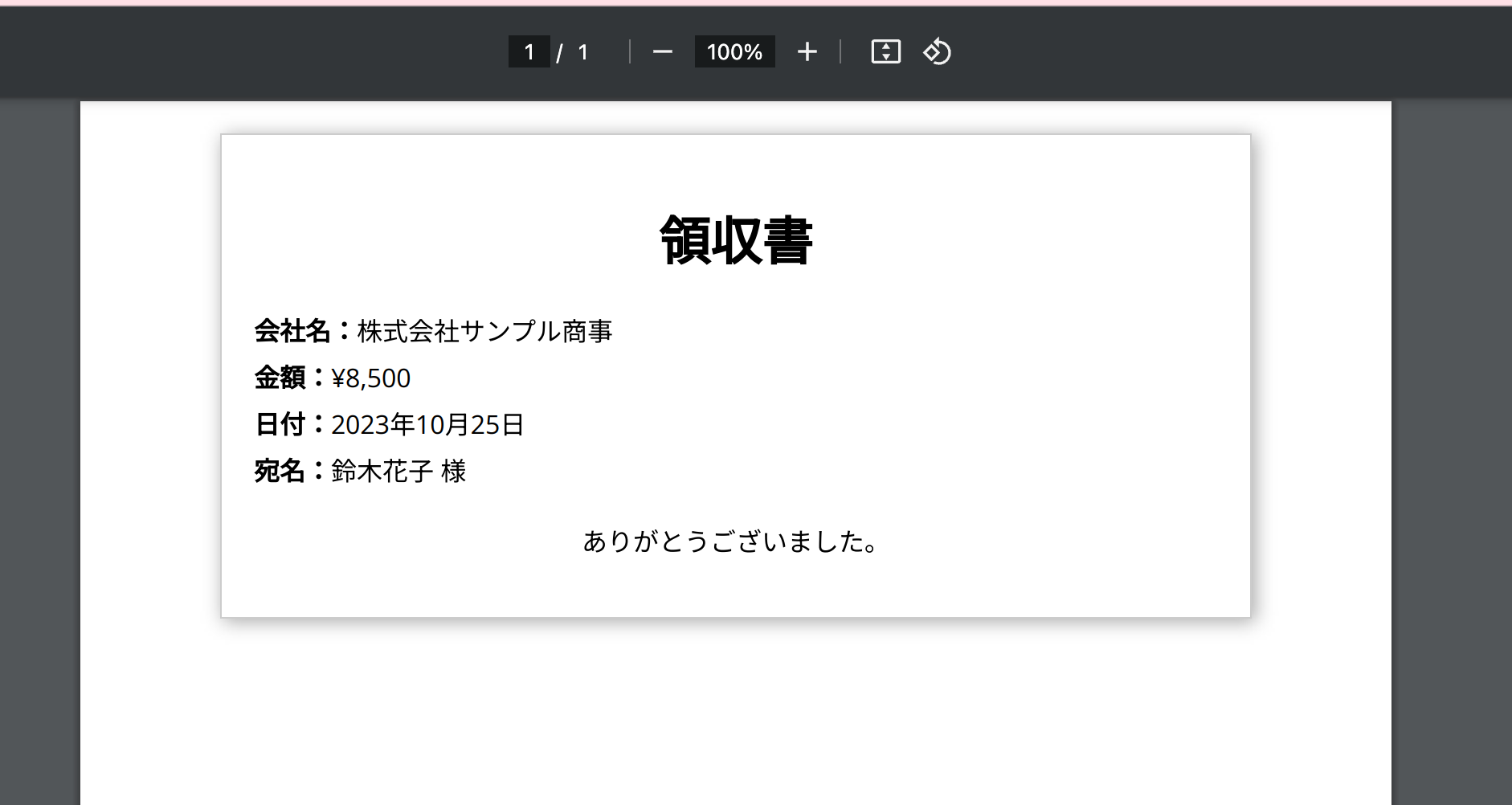
生成した領収書
Puppeteerを高速化
初めて Lambda を実行したとき、しばしば 30 秒のタイムアウトが発生しました。そこで、Puppeteer の高速化方法を調査しました。参考にした記事に基づき、コードの puppeteer.launch に引数を設定して、Chromium の起動速度を向上させました。これにより、ページのスクリプトやクエリの読み込みを減少させて、Puppeteer のLaunchを高速化しました。
Puppeteerが遅いなと感じたときの高速化Tips – Qiita
まとめ
この記事では、AWS Lambda 上で Headless Chromium と Puppeteer を利用して動的に日本語対応の PDF を生成する方法を紹介し、実際に実装しました。特に以下の点に注力しました:
- 日本語フォントの対応 : デフォルトではサポートされていない日本語フォントを追加し、日本語対応の PDF を生成する方法
- Puppeteer の高速化 : Puppeteer の起動速度を向上させるための具体的な設定と最適化の方法。
この記事の手法を応用することで、業務の自動化と効率化を図ることができるでしょう。さらに、AWS の他のサービスと組み合わせることで、顧客により付加価値の高いサービスを提供できます。
参考
- Lambda で puppeteer を動かす
- AWS Lambda 上で puppeteer を動かして、スクレイピングする
- Puppeteer が遅いなと感じたときの高速化 Tips
- Puppeteer の page.setRequestInterception(中国語)
- Lambdaを使ったPDFファイル作成とダウンロード – Qiita
最後に
グループ研究開発本部 次世代システム研究室では、最新のテクノロジーを調査・検証しながらインターネット上の高度なアプリケーション開発を行うエンジニア・アーキテクトを募集しています。募集職種一覧からご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD