2024.06.12
Gemini Advancedでデータ分析をやってみた
TL;DR
- Geminiの有料プランGemini Advancedでは、5/14から100万トークンもの入力に対応したGemini 1.5 Proを提供開始、更に5/21からスプレッドシートをアップロードしてのデータ分析や可視化が可能になりました。これはPythonのコードを生成して実行するする機能です。
- データ分析の性能としてはGemini AdvancedはChatGPT-4oとほぼ同等の性能で
どんぐりの背比べ甲乙が付け難いです。Geminiの場合、Google Sheetsなどと連携でき、データの取り込みやエクスポートが容易です。一方のChatGPTは、可視化したグラフがより見やすい印象です。 - しかし、Gemini AdvancedもChatGPT-4oも指示が曖昧では適切な集計ができないなど、データサイエンティストの視点から見ると、生成AIに任せきりでは不安な点が多く見受けられます。分析に生成したコードも冗長なものが多く生成の再現性にも懸念がありますので利用には注意が必要です。
はじめに
こんにちは、グループ研究開発本部・AI研究室のT.I.です。2024/05/15のGoogle I/Oで発表されましたが、Gemini AdvancedユーザーはGemini 1.5 Proが利用できるようになりました。(Google Japan Blog: Gemini 1.5 Pro を Gemini Advanced に搭載)元々、Gemini 1.5 Proは2月に発表されておりGoogle AI StudioやAPI経由で利用可能でしたが、Gemini Advancedに提供されたことでより多くのユーザーが手軽に利用できるようになりました。

Gemini 1.5 Pro の特徴は最大100万トークンという大きなコンテキストウィンドウを持つことです。Google I/Oでは近い将来に200万トークンまでの拡張を予定していると発表されています。そして5/21のアップデート(Gemini アプリの機能アップデート)で、下記のデータ分析機能が追加されました。今回のBlogでは、Gemini Advanced (Gemini 1.5 Pro)によるデータ分析について紹介します。
2024.05.21
Gemini Advanced 限定機能: データ分析
- 更新内容: 複数のスプレッドシートをアップロードして、迅速にデータを処理・探索し、プレゼンテーション用のグラフを作成し、詳細な分析を行うことができます。Google スプレッドシート、CSV、Excel ファイルを Google ドライブから、またはデバイスからアップロードすることができます。
- 理由: 効率的にデータを処理、探索、分析、可視化して、注目すべき点を短時間で見つけることができます。
Gemini Advanced の使い方
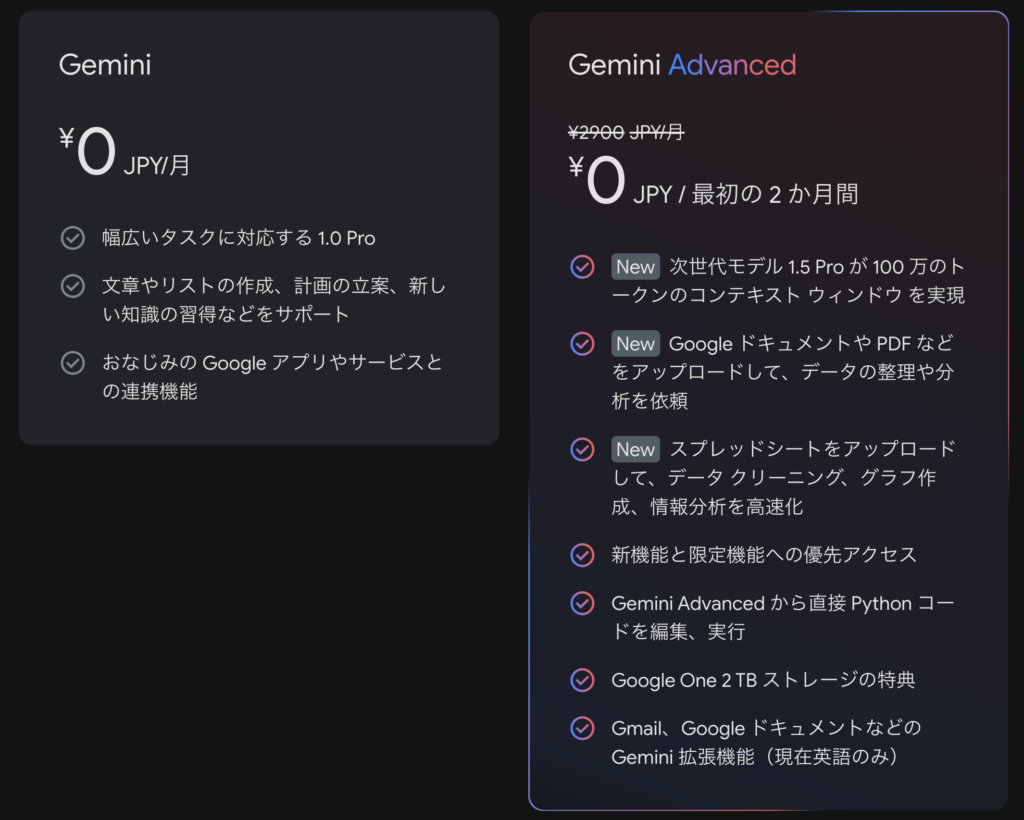
まず、Gemini Advancedを利用するには有料プランに加入する必要があります。最初の2ヶ月は無料ですが、その後は月額2,900円かかります。(ChatGPT Plusが月額$20なので、両方使うなら毎月6,000円ほどかかります💰)Google One 2TBストレージがつくことを考えるとお得なのかもしれません。
100万トークンのコンテキストウィンドウを試してみるために、実験してみました。適当に青空文庫から取ってきたテキストファイルをアップロードしてみました。100万トークンまではありませんが、約45万字程度の文章量で、Google AI Studioで確認すると28万トークンほどの分量のようです。
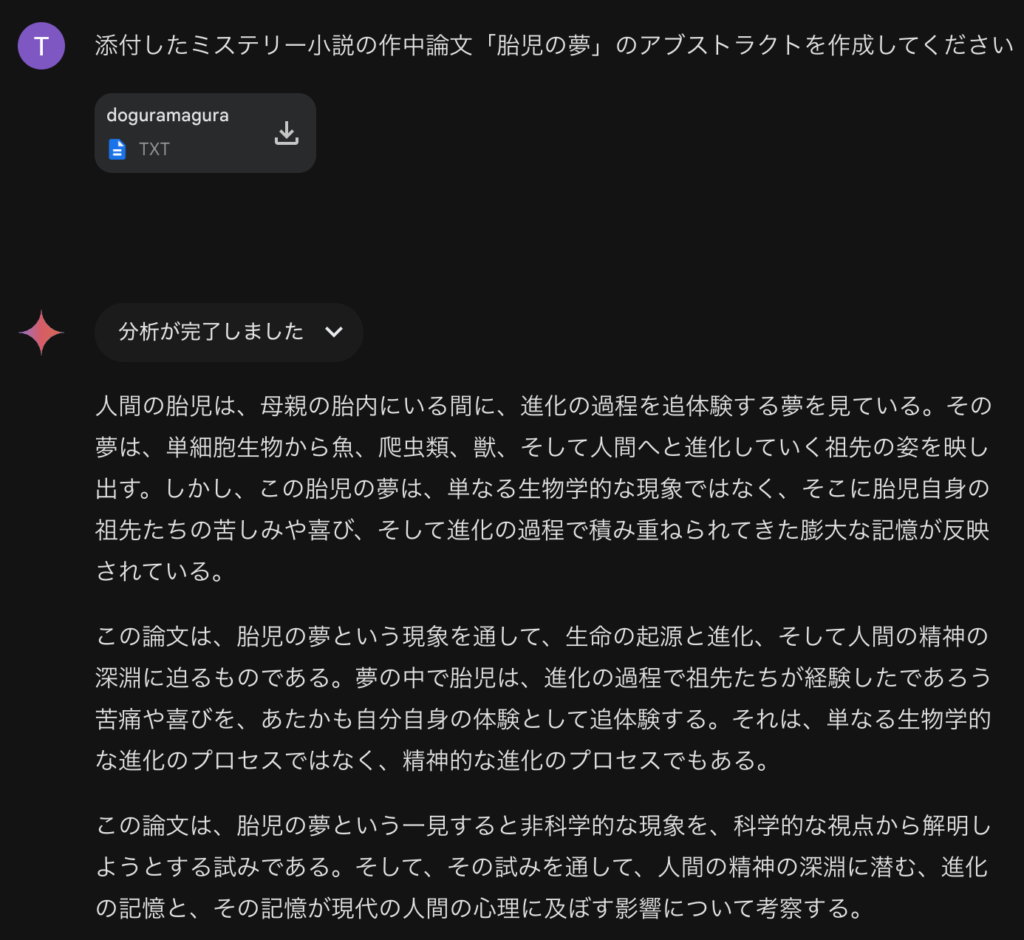
うーん、概ね問題なく内容の要約ができているみたいですね。有名な作品なので事前知識があるのでは?とテキストを与えずに質問すると以下のように間違った回答をハルシネーションしてしまいました。確かに、入力したテキストを元に回答しているようですね。どうやって、100万ものコンテキストウィンドウを達成しているのか、その技術は気になりますね。以前のBlogで何度も紹介しているように、GeminiなどのLLMの根幹技術であるTransformerは、入力長の二乗に比例して計算コストが増大します。流石にまともに100万トークンを処理しているのは不可能かと思われるので、何らかの工夫がされているのでしょう。
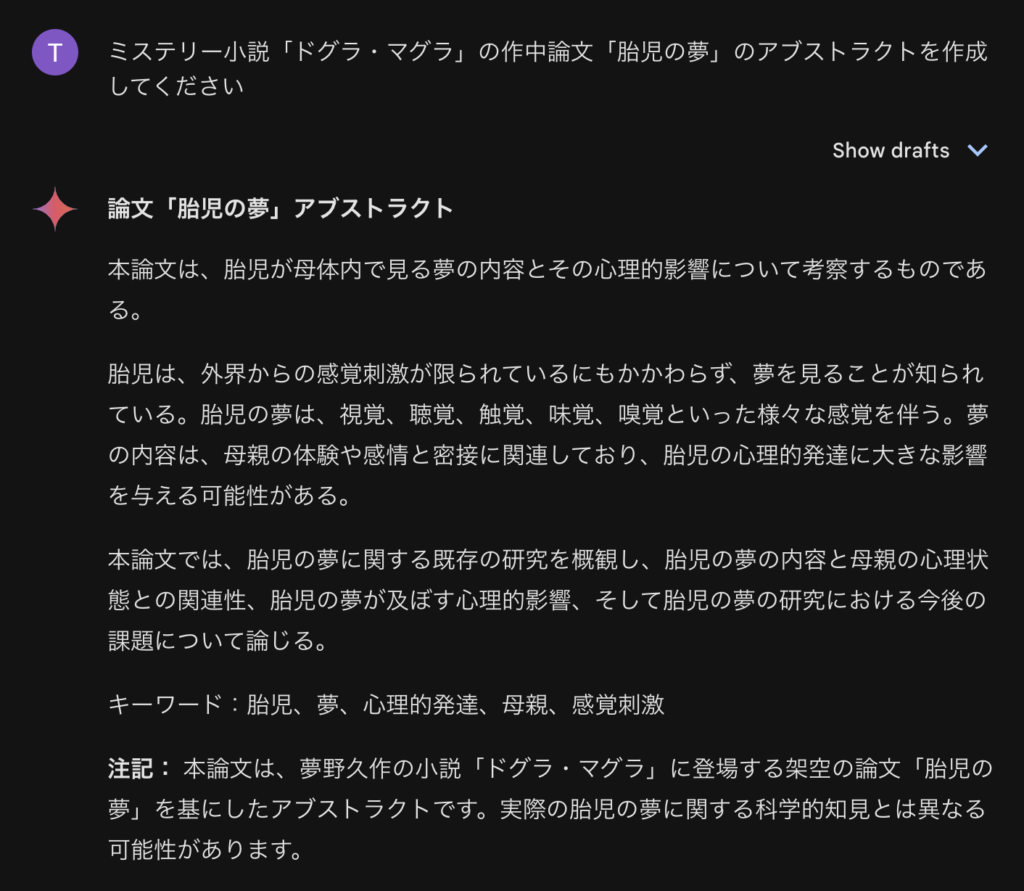
Gemini Advanced でデータ分析してみた
では、Gemini Advancedを使ったデータ解析の例として、学生の試験結果のデータを解析してみます。適当にChatGPTで作ったサンプルをcsvファイルに保存します。これは2つのクラス(AとB)の合計10名の生徒の国語・数学・理科・社会・英語の5教科の試験結果(各教科100点満点)を2回分のデータを含んでいます。これをGemini Advancedにアップロードして分析させてみます。
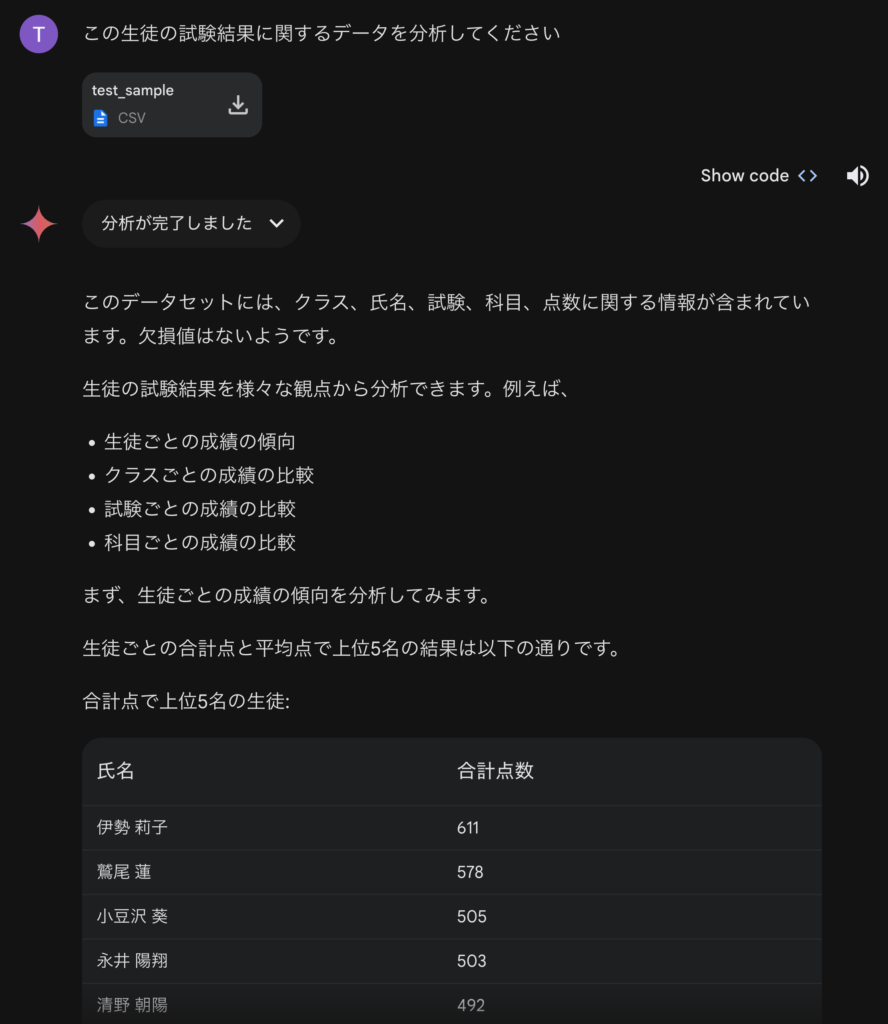
Geminiは最初にどのようなデータであるか簡単に説明してくれました。これは裏では何をやっているのかは、Show codeをクリックしてコードを展開して確認ができます。
Pythonのpandasを利用してデータを読み込んで集計しています。この種の処理はChatGPTでの解析とほぼ同等ですね(初手で、pandasのオプションを変更し行数と列数の表示上限を解除していますが、大量のデータの誤って表示させると大変なことになるのでやめた方が無難ですよ)。
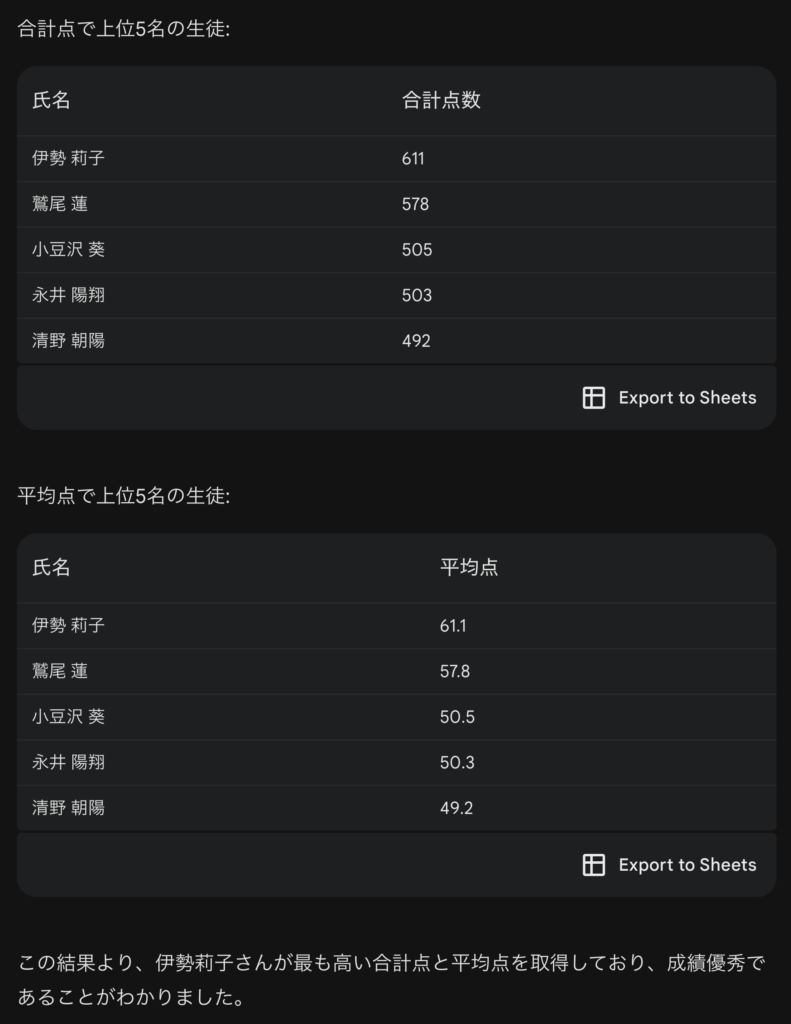
以下は先ほどの出力の続きです。このように成績上位のリストを出力してくれました。テーブルの右下にExport to Sheetsというボタンがあります。これをクリックするとGoogle Sheetsに結果をエクスポートして、Google Sheets上で更に詳細な分析・可視化が可能です。このようなGoogleの他のサービスとのシームレスな連携は便利ですね。
このPythonの処理コードは以下の通りです。
# Calculate the total score and average score for each student
df_agg = df.groupby(['氏名'], as_index = False)['点数'].agg(合計点数 = 'sum', 平均点 = 'mean')
# Sort the DataFrame by total score in descending order and print the top 5 rows
print("生徒ごとの合計点:")
print(df_agg[['氏名','合計点数']].sort_values(by='合計点数', ascending=False).head(5).to_markdown(index=False,numalign="left", stralign="left"))
# Sort the DataFrame by average score in descending order and print the top 5 rows
print("生徒ごとの平均点:")
print(df_agg[['氏名','平均点']].sort_values(by='平均点', ascending=False).head(5).to_markdown(index=False,numalign="left", stralign="left"))
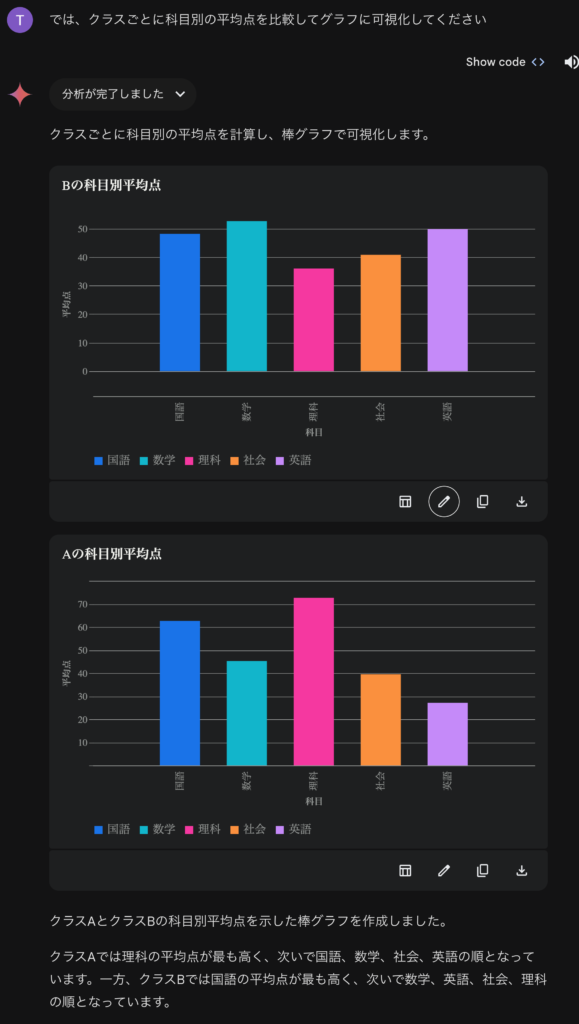
さて、どんどん続けていきましょう。集計してグラフを作成してもらいました。
グラフに続き、詳細な数値についても説明してくれました。
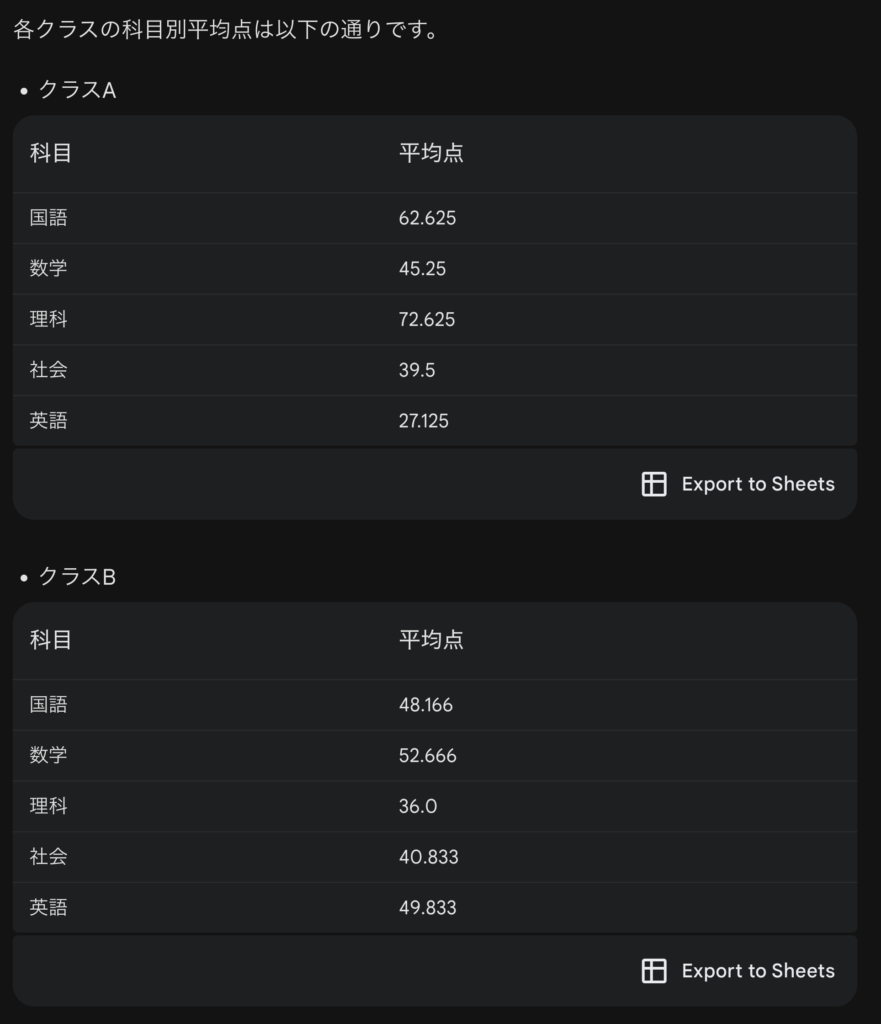
このグラフについては、右下のCustomize the chartをクリックすることでグラフの種類や軸などの名称を変更できます。また、イメージファイルとして保存することも可能です。
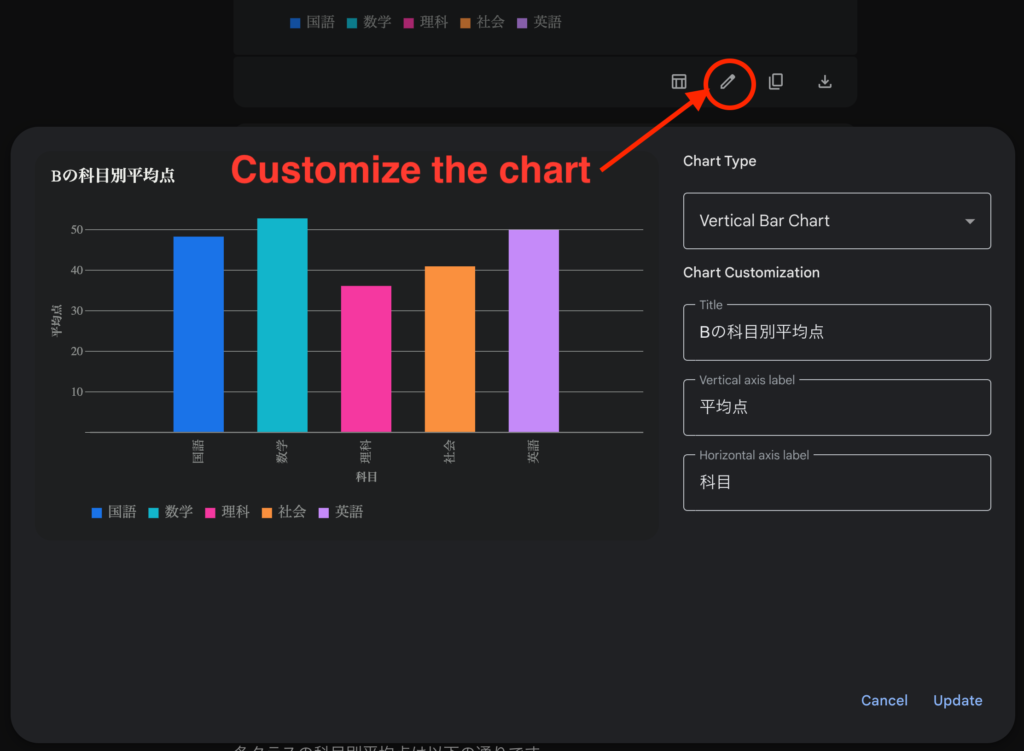
Geminiは可視化にあたっては、altairというライブラリを使用しています(Vega-Altair https://altair-viz.github.io/index.html)。同様のことをChatGPTでやろうとすると、matplotlibを使い日本語のフォントがないために、文字化けで苦労することを考えると、ちゃんと日本語が表示できるので良いですね(ただ、明朝体ではなくゴシック体のほうが)。ただ、科目名をわざわざ90度回転させてますが、この文字数ならそのまま表示しても問題ないのではないでしょうか。棒グラフの可視化で頻繁にされている処理を理解せずに真似ているだけだと思われます。今回の場合では、文字数が少ないので回転が不要であることを理解できていない感じですね。また、横軸で科目は分かりますので、科目毎に個別の色を設定しないほうが見やすいです。
import altair as alt
# Calculate average scores for each class and subject
df_class_agg = df.groupby(['クラス','科目'])['点数'].mean().reset_index()
# Create a pivot table for visualization
df_pivot = df_class_agg.pivot(index='クラス', columns='科目', values='点数')
# Plot bar charts for each class
for class_name in df_pivot.index:
df_plot = df_pivot.loc[class_name].reset_index()
df_plot = df_plot.rename(columns = {class_name:'平均点'})
chart = alt.Chart(df_plot).mark_bar().encode(
x=alt.X('科目', axis=alt.Axis(labelAngle=-90)),
y=alt.Y('平均点', title='平均点'),
color = '科目',
tooltip = ['科目','平均点']
).properties(
title=f'{class_name}の科目別平均点'
).interactive()
# Save the chart as a JSON file
chart.save(f'{class_name}_average_scores.json')
さて、このデータセットですが、実は2回分の試験結果が含まれています。第1回と第2回の点数を比較してみましょう。以下のように、途中でエラーが何度も発生しましたが、諦めずに何とか処理して可視化してくれました。
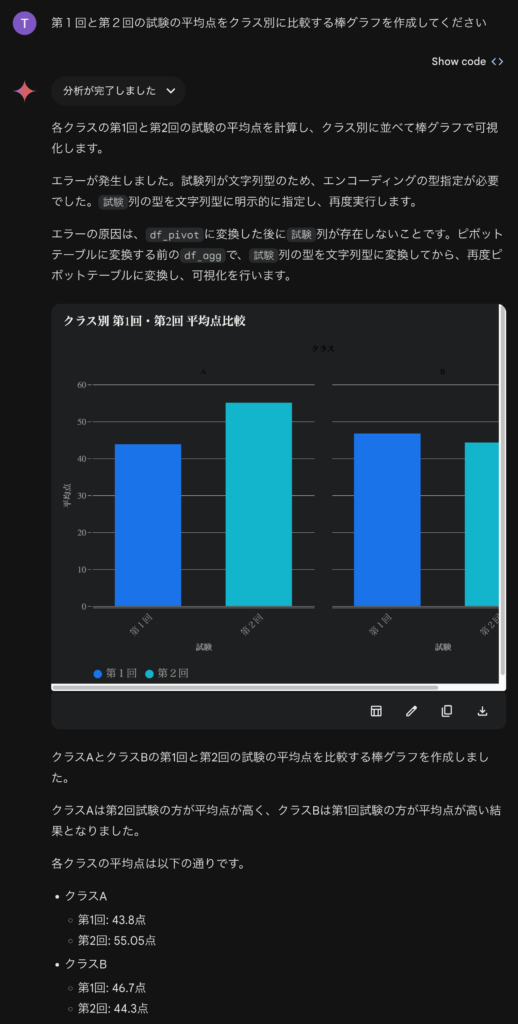
しかし、残念なことにクラス名の文字色が黒で背景に被って読みにくいです。そこでダークテーマをオフにしてみました。
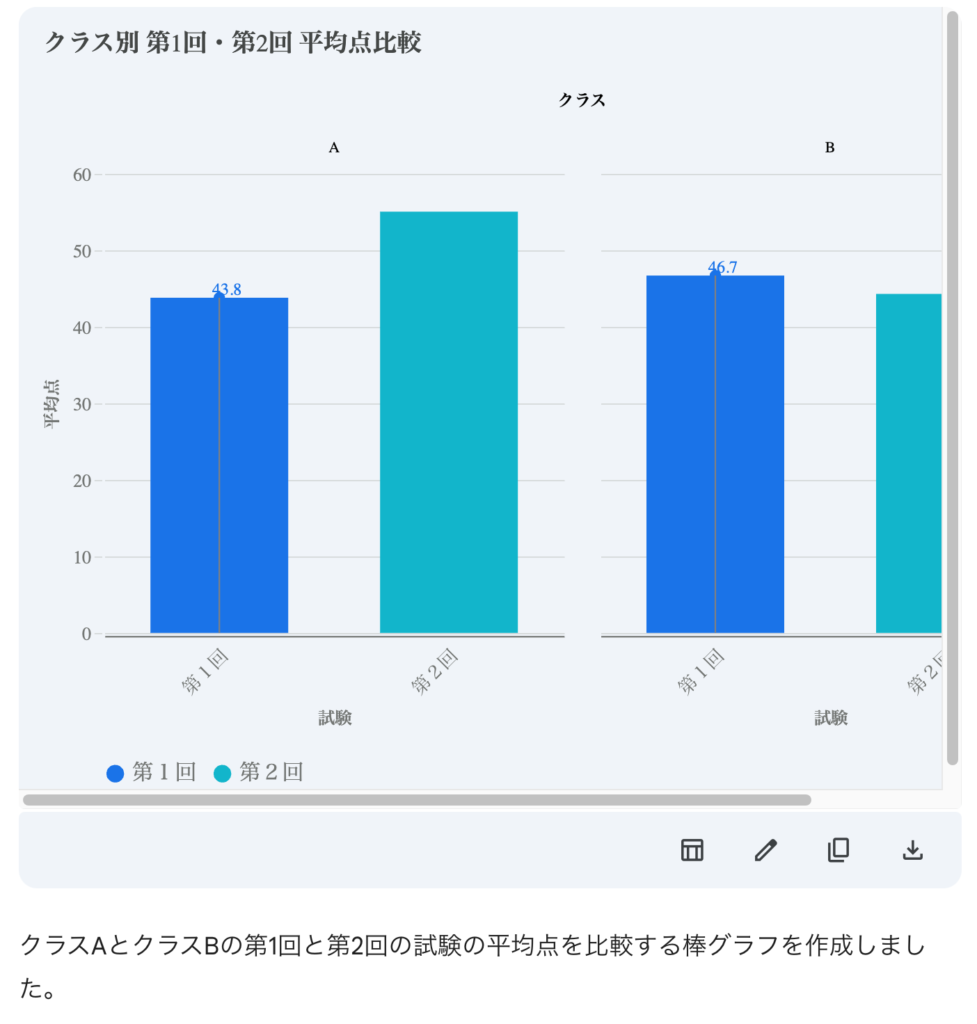
ダークテーマをオフにして読みやすくなりましたが、第1回などのラベルが無駄に傾いていたり、横幅が不足していたりと少々惜しいです。
この分析では、Gemini は一旦全ての処理コードを生成して実行、エラーが出たらコードを修正して再実行しています。今回の場合、2回のエラーで止まったので、計3種類のコードを生成しています。最終的に生成されたコードは以下の通りです。
import altair as alt
# Filter the data for '第1回' and '第2回' exams
df_filtered = df[df['試験'].isin(['第1回', '第2回'])].copy()
# Calculate average scores for each class and exam
df_agg = df_filtered.groupby(['クラス', '試験'])['点数'].mean().reset_index()
# 明示的に`試験`列を文字列型に変換
df_agg['試験'] = df_agg['試験'].astype(str)
# Create a pivot table for visualization
df_pivot = df_agg.pivot(index='クラス', columns='試験', values='点数').reset_index()
# Create a chart for each class
base = alt.Chart(df_agg).encode(
x=alt.X('試験:N', axis=alt.Axis(title='試験', labelAngle=-45)),
y=alt.Y('点数:Q', axis=alt.Axis(title='平均点')),
tooltip = ['試験','点数']
)
# Combine points and text into a single chart object
chart = base.mark_bar().encode(
color='試験:N'
)
# Create a selection that chooses the nearest point & selects based on x-value
nearest = alt.selection(type='single', nearest=True, on='mouseover',
fields=['試験'], empty='none')
# Transparent selectors across the chart. This is what tells us
# the x-value of the cursor
selectors = base.mark_point().encode(
opacity=alt.value(0),
).add_selection(
nearest
)
# Draw points on the line, and highlight based on selection
points = chart.mark_point().encode(
opacity=alt.condition(nearest, alt.value(1), alt.value(0))
)
# Draw text labels near the points, and highlight based on selection
text = chart.mark_text(align='center', dx=5, dy=-5).encode(
text=alt.condition(nearest, '点数:Q', alt.value(' '))
)
# Draw a rule at the location of the selection
rules = base.mark_rule(color='gray').encode(
x='試験:N'
).transform_filter(
nearest
)
# Put the five layers into a chart and bind the data
chart_combined = alt.layer(
chart, selectors, points, rules, text
).properties(
width=300,
height=300
).facet(
column='クラス:N',
title='クラス別 第1回・第2回 平均点比較'
)
# Save the chart
chart_combined.save('class_exam_average_scores_comparison.json')
Gemini Advancedの分析をGPT-4oと比較してみた
Gemini Advancedのデータ分析の性能を比較するため、GPT-4oでも同様の分析をしました。以下のデータと指示はほぼ同じです。
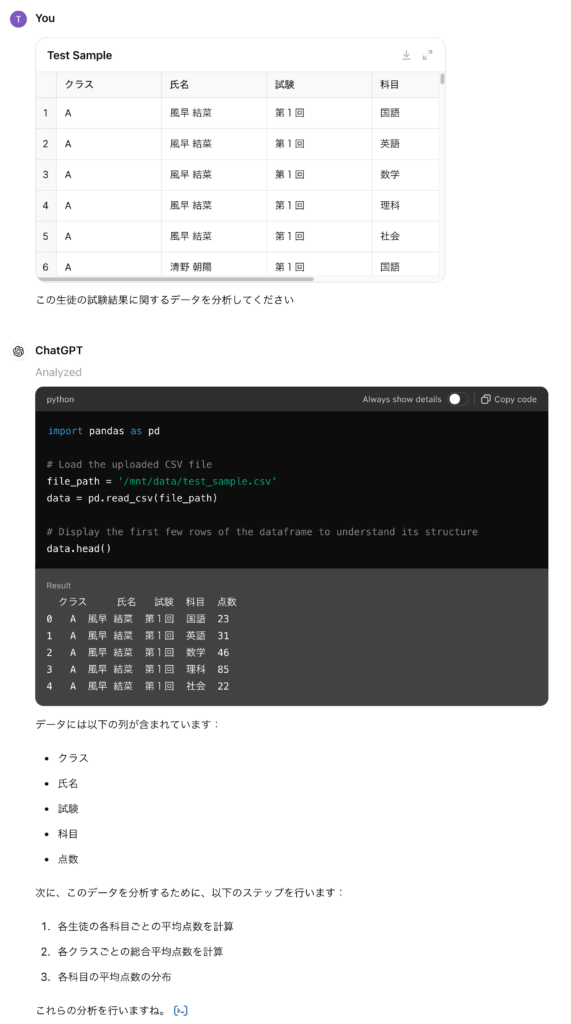
処理としては、Gemini Advancedとほぼ同じでPythonのコードを生成して実行しています。簡単な集計結果は勝手に説明してくれます。

average_scores_per_student = data.groupby(['氏名', '科目'])['点数'].mean().unstack()
# Calculate overall average score per class
average_scores_per_class = data.groupby('クラス')['点数'].mean()
# Calculate average scores for each subject
average_scores_per_subject = data.groupby('科目')['点数'].mean()
import ace_tools as tools
# Display the calculated data
tools.display_dataframe_to_user(name="Average Scores Per Student", dataframe=average_scores_per_student)
tools.display_dataframe_to_user(name="Average Scores Per Class", dataframe=average_scores_per_class)
tools.display_dataframe_to_user(name="Average Scores Per Subject", dataframe=average_scores_per_subject)
average_scores_per_student, average_scores_per_class, average_scores_per_subject
グラフを作成してもらいました。Gemini Advancedと同じく、棒グラフで可視化してくれました。先ほどChatGPTでは、日本語のフォントがないために日本語が文字化けすると述べましたが、実は最近のChatGPT4oではPythonで生成した画像ファイルを表示するのではなく、データから改めてグラフを生成しているため文字化けの問題は解消されています。別途、フォントファイルをアップロードして指定する必要はなくなったので便利ですね。
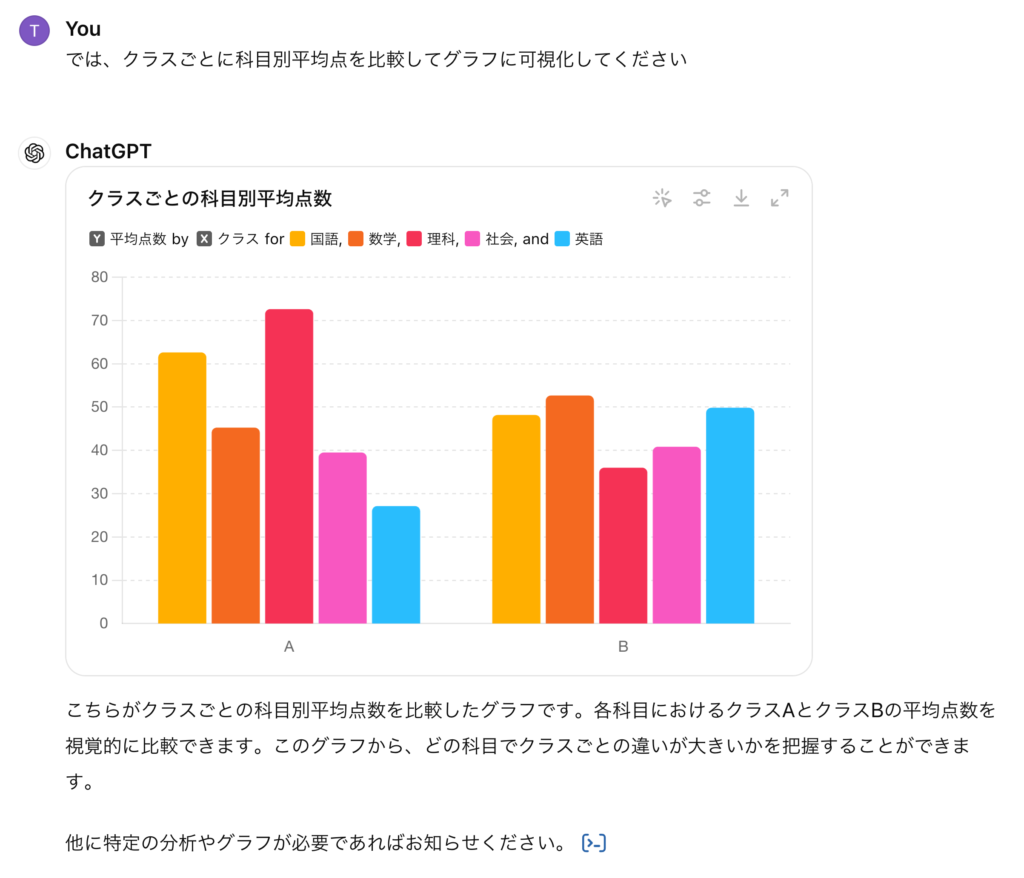
ただし、表示をstaticに切り替えると、日本語のフォントがないために文字化けするので注意が必要です。
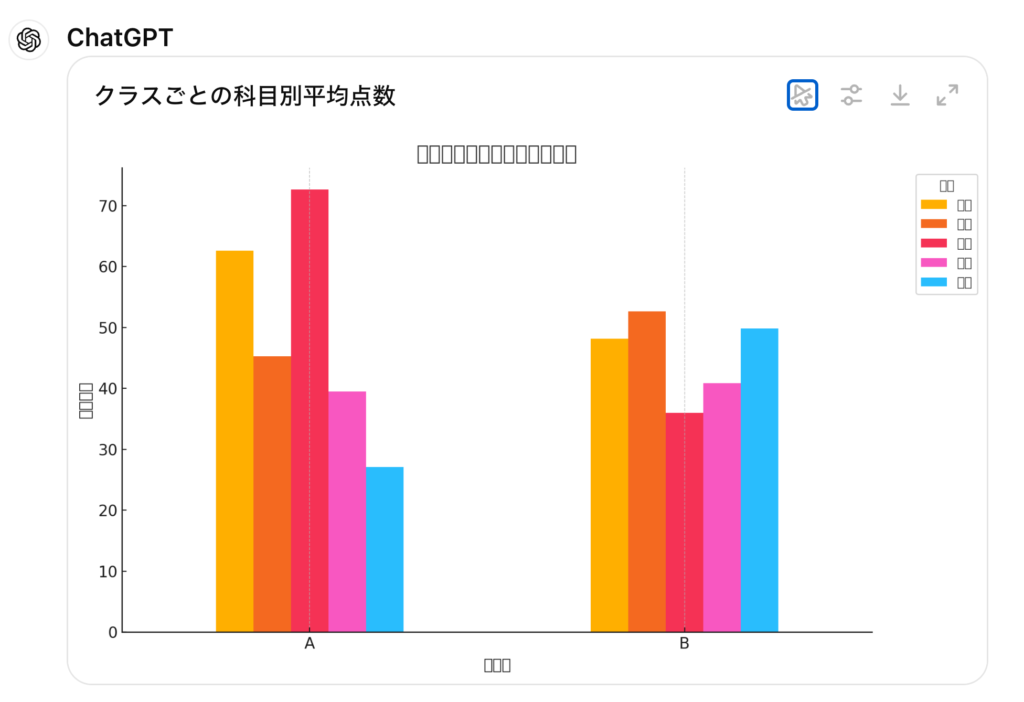
分析で生成されたコードは以下の通りです。従来通り、matplotlibでの可視化を試みますが、日本語のフォントがないのでここではエラーが発生しています。staticでない可視化の場合、average_scores_per_class_subjectに集計したデータを別途、処理してグラフを生成しているみたいです。ただ、その処理に関してはユーザー側では見ることができませんので詳細は不明です。
import matplotlib.pyplot as plt
# Calculate average scores per class for each subject
average_scores_per_class_subject = data.groupby(['クラス', '科目'])['点数'].mean().unstack()
# Plotting the average scores per class for each subject
plt.figure(figsize=(10, 6))
average_scores_per_class_subject.plot(kind='bar', figsize=(10, 6))
plt.title('クラスごとの科目別平均点数')
plt.xlabel('クラス')
plt.ylabel('平均点数')
plt.legend(title='科目', bbox_to_anchor=(1.05, 1), loc='upper left')
plt.xticks(rotation=0)
plt.grid(axis='y')
# Show the plot
plt.tight_layout()
plt.show()
その後のクラス別の試験結果の比較についても、同様に処理してくれました。Gemini AdvancedのよりもChatGPTのグラフの方が見やすいですね。
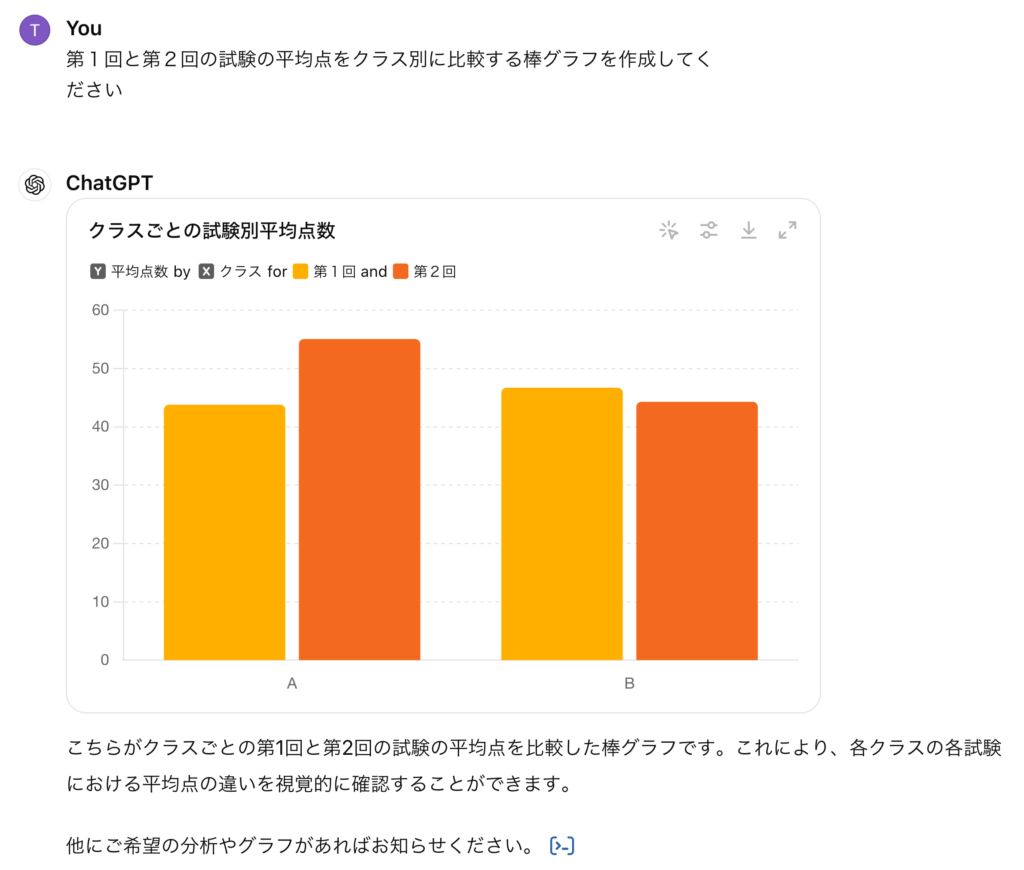
こちらのコードも先ほどと同様に、以下のようにmatplotlibでの可視化を試みています(そして文字化けする)。
# Calculate average scores for each test by class
average_scores_per_class_test = data.groupby(['クラス', '試験'])['点数'].mean().unstack()
# Plotting the average scores per class for each test
plt.figure(figsize=(10, 6))
average_scores_per_class_test.plot(kind='bar', figsize=(10, 6))
plt.title('クラスごとの試験別平均点数')
plt.xlabel('クラス')
plt.ylabel('平均点数')
plt.legend(title='試験', bbox_to_anchor=(1.05, 1), loc='upper left')
plt.xticks(rotation=0)
plt.grid(axis='y')
# Show the plot
plt.tight_layout()
plt.show()
Gemini Advanced(とChatGPT)の分析をデータサイエンティストの視点でチェックしてみた
さて、Gemini AdvancedやChatGPT-4oを使えば、確かに簡単にデータを分析できそうです。しかし、その精度や内容は問題ないのでしょうか?データサイエンティストの観点から、分析の進め方やコードについて厳しくチェックしてみました。
集計指標の設定の問題
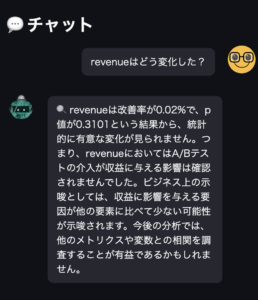
Gemini AdvancedやChatGPT-4oは、教科単位の平均点を計算してくれましたが、その評価方法は正しいでしょうか?最初に述べたようにこのデータセットは100点満点の5教科の試験結果です。Geminiが最初に出した集計で成績上位の生徒と平均点が紹介されましたが、最初見た瞬間にトップの伊勢さんの平均点が61.1点というのはおかしいと思いました。プロンプトへの指示が曖昧だったことが原因ではありますが、各試験の成績としては5教科の合計点としてまずは集計することが一般的です。クラス別の平均点を比較する際も同様でした。GeminiやChatGPTでは、個人ごとに集計してからクラスの平均値を比較するのではなく、全体の平均を出してしまっているため、試験の成績として不自然な数値の比較がされてしまっています。
平均点といった曖昧な用語は、データ分析の現場では認識に齟齬を生む原因となります。何をどのようにして集計した量なのかきちんと説明することが重要です。日平均なのか週平均なのか、粒度を明確にすることが必要です。また、今回は5教科全て100点満点だったからよかったものの、教科ごとに満点が異なる場合、単純な平均値を集計することに意味はありません。
以下のようにちゃんと試験の合計点を計算してからクラス別の平均値を比較するように指示すると納得できる結果となりました。しかし、このような指示をするためには、どのようなデータをどのように処理しているのかを理解している必要があります。生成AIに丸投げではなく、きちんと分析するデータを理解して集計する指標を設定することが重要です。ただし、自分自身でコードを書くことと比較すると自然言語での指示は冗長となり曖昧さも残るため、どこまで指示を細かくするかは難しいところです。
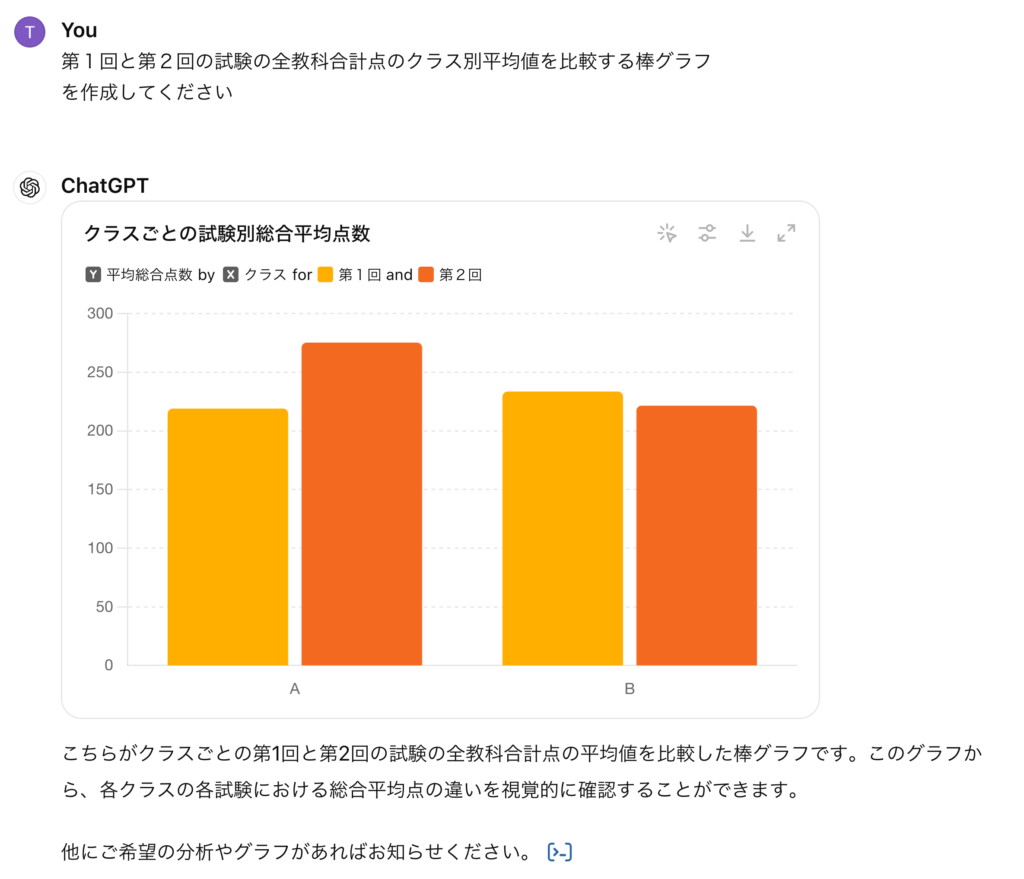
分析のコードは下記の通りです。
# Calculate total scores for each student in each test
total_scores_per_student_test = data.groupby(['氏名', '試験'])['点数'].sum().unstack()
# Merge total scores with class information
student_class = data[['氏名', 'クラス']].drop_duplicates().set_index('氏名')
total_scores_per_student_test = total_scores_per_student_test.join(student_class)
# Calculate average total scores per class for each test
average_total_scores_per_class_test = total_scores_per_student_test.groupby('クラス').mean()
# Plotting the average total scores per class for each test
plt.figure(figsize=(10, 6))
average_total_scores_per_class_test.plot(kind='bar', figsize=(10, 6))
plt.title('クラスごとの試験別総合平均点数')
plt.xlabel('クラス')
plt.ylabel('平均総合点数')
plt.legend(title='試験', bbox_to_anchor=(1.05, 1), loc='upper left')
plt.xticks(rotation=0)
plt.grid(axis='y')
# Show the plot
plt.tight_layout()
plt.show()
分析コードの品質について
GeminiもChatGPTも結局はPythonのコードを生成して実行することでデータ分析しています。そのコードの品質や可読性も懸念があります。例えば、Geminiが2度失敗してようやく生成できた、クラス別の平均点を計算するコードは以下の通りです。
# Filter the data for '第1回' and '第2回' exams df_filtered = df[df['試験'].isin(['第1回', '第2回'])].copy() # Calculate average scores for each class and exam df_agg = df_filtered.groupby(['クラス', '試験'])['点数'].mean().reset_index() # 明示的に`試験`列を文字列型に変換 # df_pivot['試験'] = df_pivot['試験'].astype(str) # (注) 2回目の実行時にはこの行が存在していた。df_pivotに"試験"列が存在しないためエラーとなる df_agg['試験'] = df_agg['試験'].astype(str) # (注) 実はこの変換処理も不要 # Create a pivot table for visualization df_pivot = df_agg.pivot(index='クラス', columns='試験', values='点数').reset_index()
実はその後のaltairの可視化のコードで、このdf_pivotは使っていません。なぜ、このようになっているかというと以下のような試行錯誤の結果です。
- 1回目に生成して失敗したコードでは
df_pivotを使ってプロットしようとしてデータの形式がうまくいかず失敗。 - 2回目は型指定が原因として修正、同時に
df_aggでプロットするように変更しています。前者の修正は本来は不要で後者の修正で動作するのですが、変数型を変更しようとした”試験”列が、そもそもdf_pivotに存在しないため失敗(まったく余計なことを)。 - 3回目はエラーを反映して
df_pivotの型変更処理を削除し成功。
と中々苦労しながらの処理となっています。
結局、様々な処理を行っているように見えますが基本的にはデータをフィルタリングして平均値を計算しているだけです。その平均値も先ほど指摘したように5教科の合計の平均ではなく、科目ごとの平均を計算しています。その後にaltairの可視化の際に様々なオプションを指定するためコード自体はとても長い処理となっています。ChatGPTが生成する分析コードも同様の問題があります。pandas の集計ロジックが冗長で、途中段階の集計した変数がいくつも定義されており、後々の分析で混乱を招く原因となります。また、可視化のコードもあまり洗練されていません。このようなコードは可読性が悪く、デバッグや修正が難しいです。特にJupyter NotebookやVisual Studio Codeでの分析で複数のcellに跨った処理が発生すると、後々の管理が大変になります。慣れが必要ですが、自分ならこのようにして処理を繋げて集計します。
_df = (
df.query('試験 in ["第1回", "第2回"]') # 第1回、第2回のデータを抽出(このデータの場合不要であるが、一応)
.groupby(['試験', 'クラス', '氏名'], as_index=False)
.agg(合計点=('点数', 'sum')) # 個人・試験ごとの全教科の合計点を算出
.groupby(['試験', 'クラス'], as_index=False)
.agg(平均点=('合計点', 'mean')) # クラスごとの平均点を算出
)
これで一気に以下の集計ができます。
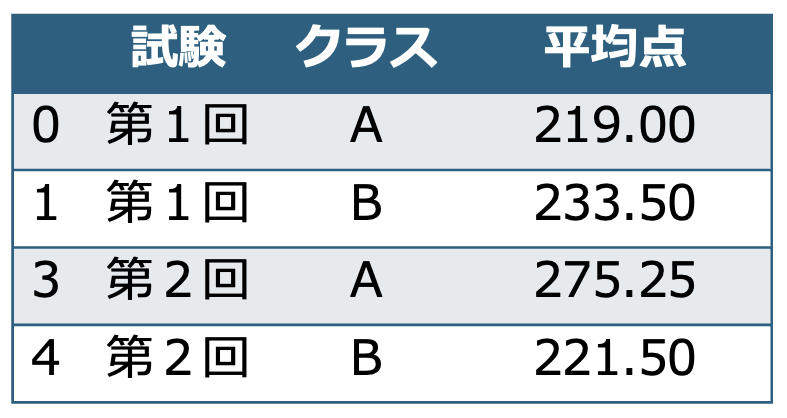
可視化に際しては、この集計したデータフレームを使って、こんな感じでしょうか。
import seaborn as sns
sns.set(
context='talk', style='whitegrid',
rc={'font.family': 'Hiragino Maru Gothic Pro'} # 文字化けないように日本語のフォントを指定
)
sns.catplot(data=_df, x='クラス', y='平均点', hue='試験', kind='bar', height=5, aspect=1.2)
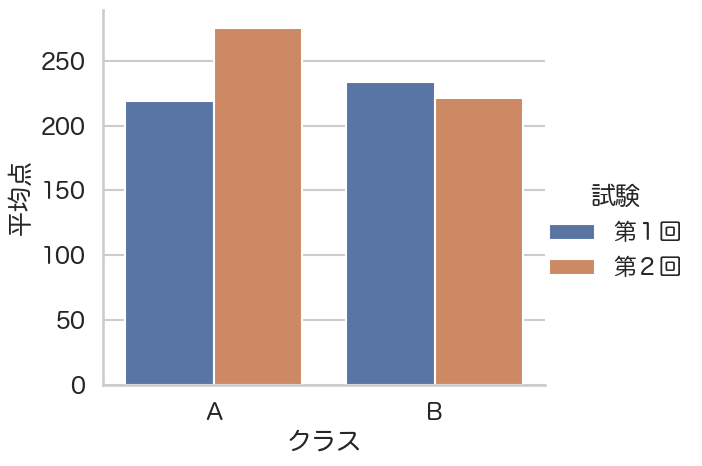
seabornライブラリを使って上記のように可視化するとシンプルに出来て、コードも短くなります。ChatGPTのサンプルのように、pandasのデータフレームを使って可視化し、matplotlibの個別の機能で微調整するなら下記のようになります。ChatGPTなどが生成するコードでは、matplotlibのPyplotインターフェース(plt.何々)でグラフを修正することが多いですが、これは若干古いスタイルです。下記のようなオブジェクト指向インターフェース(ax.何々)の方が後々の微調整がし易く、コードの分量も少なくて済みます。なお、それよりも最初からseabornを使って処理した方がシンプルに記述できるのでお勧めではあります。
fig, ax = plt.subplots(figsize=(6, 4)) # ChatGPTのコードに合わせるため pivot_table でdataframeを変形しています _df.pivot_table(index='クラス', columns='試験', values='平均点')[::-1].plot(kind='barh', width=0.8, ax=ax) ax.legend(title='試験', loc='upper left', bbox_to_anchor=(1.05, 1)) ax.set(xlabel='平均点') # "クラス"の軸ラベルは省略可能
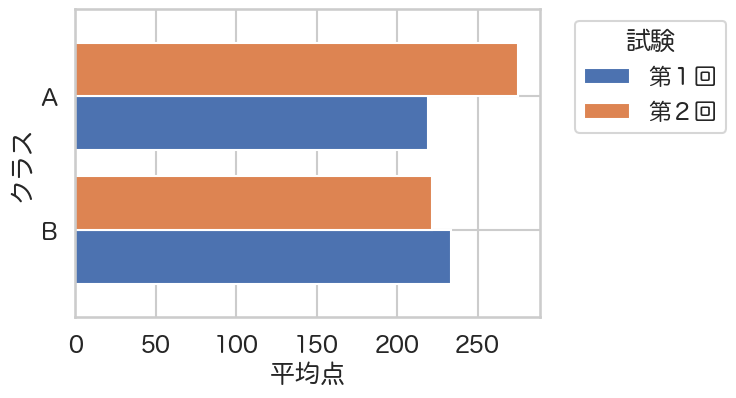
作成したグラフからのフィードバック・微調整ができない
GeminiやChatGPTのデータ分析のプロセスは、プロンプトとデータから分析コードを生成、それを実行という流れになっています。通常のデータ分析の際には作成したグラフを目視して、点の大きさや色、ラベルの位置など、必要に応じて見やすいように微調整します。今回のGeminiの分析では、不必要なラベルの回転や色が背景と重なって文字が読みにくかったり、グラフ全体が画面に収まらないなどの問題が発生しました。今のGeminiやChatGPTでは、これを修正するためのフィードバックができません。ユーザーがグラフを見て再度指示をして修正する必要がありますが、プロンプトでの指示では非常に手間がかかり不確実です。
GeminiやChatGPTはマルチモーダルで画像の入力は可能なので、出力したグラフを入力に使って生成AIに修正させることは可能かもしれませんが、以前のBlogでの実験(GPT-4oを使って画像を分析をしてみた)からもわかるように、その精度については限界があるため、現状では難しいでしょう。
分析プロセスの再現性の問題
分析プロセスの再現性についても問題があります。GeminiやChatGPTが生成するコードは、その都度異なるものが生成されることがあり、分析過程の再現性が保証されません。例えば、先ほどと同じプロンプトでGemini Advancedで分析すると以下のように今度は総合点を評価しました。
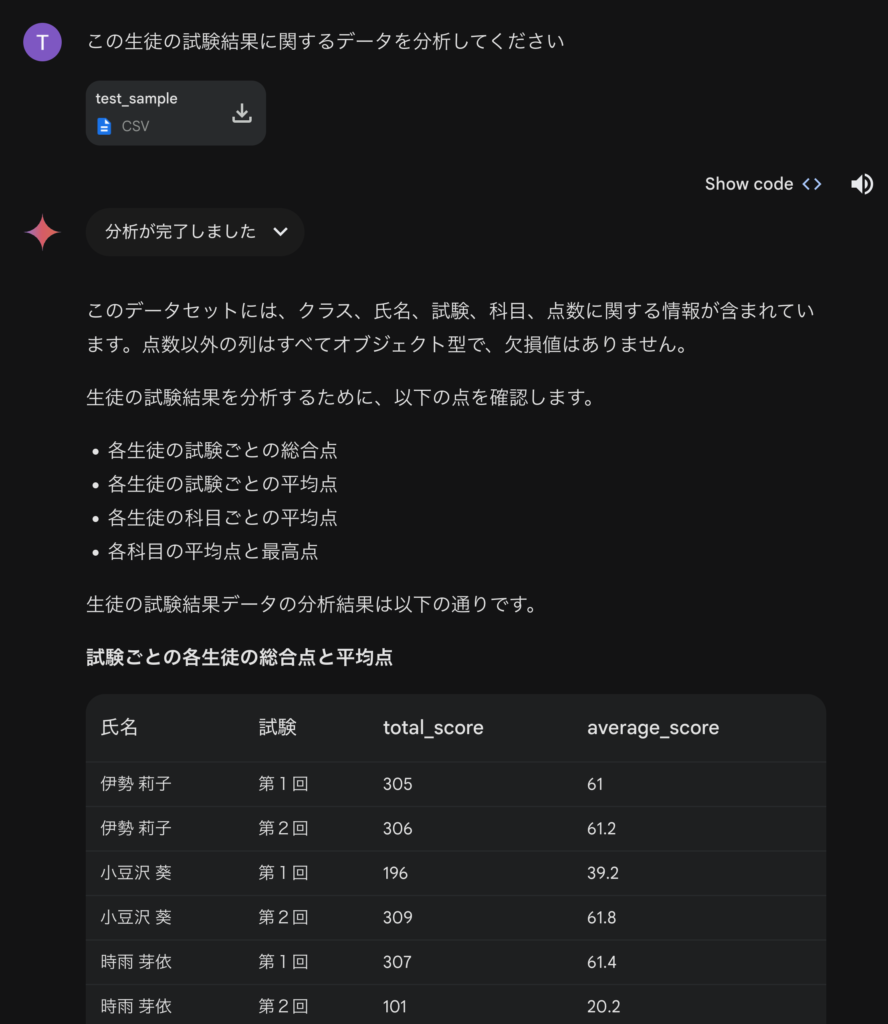
今度はちゃんと総合点を計算して、ほっとしたのも束の間、average_scoreという指標も計算しています。何を計算しているかとコードをチェックしてみると、総合点を
# 試験ごとに各生徒の総合点を計算し、`total_score`列として追加します。
df_agg = df.groupby(['氏名', '試験']).agg(total_score=('点数','sum')).reset_index()
# 試験ごとに各生徒の平均点を計算し、`average_score`列として追加します。
df_agg['average_score'] = df_agg['total_score'] / 5 # (注) 全教科の合計点を5で割って平均値を計算しています
まあ、先ほどの分析は曖昧な指示だったから悪かった訳で、科目別の平均点をクラス別に比較するように指示すれば大丈夫でしょう。
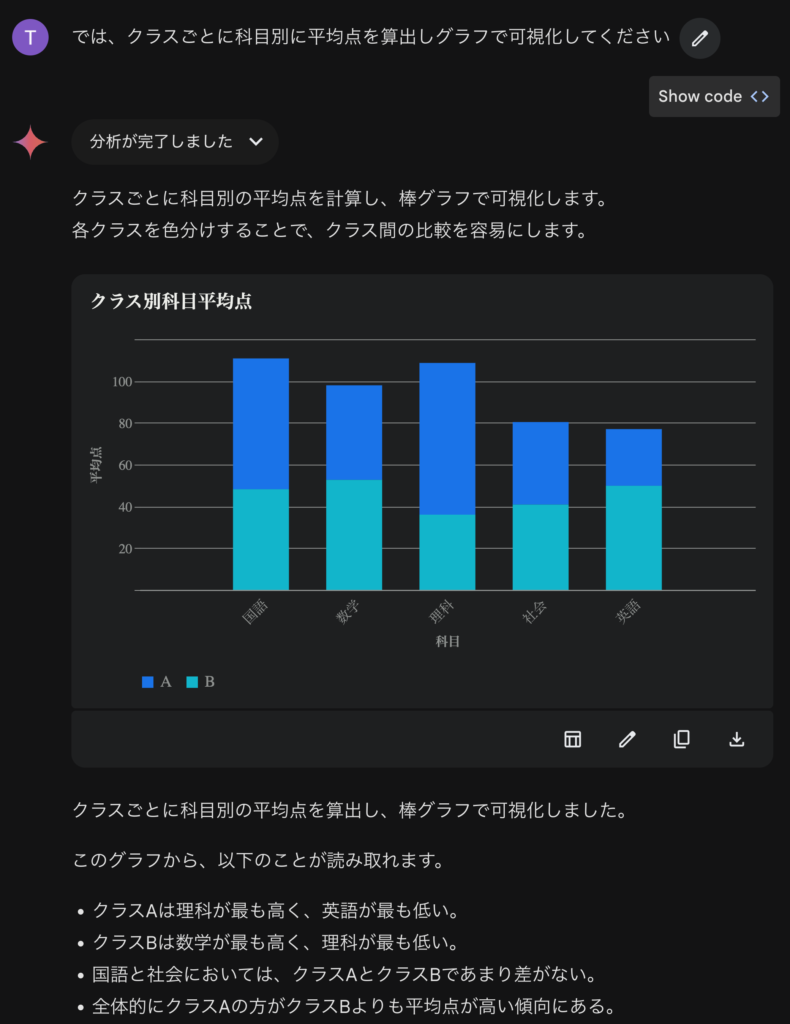
クラス間の比較をするのに、その棒グラフを積み上げないでください💢 。と、まあ、生成AIの分析は時々変なことがあるので、データ分析を丸投げして一瞬で終わる。というのではなく、利用者がチェックして何度も試行錯誤しないといけません。面倒なことを生成AIに任せて楽をしようとすると、もっと面倒なことになるので要注意です。
まとめ
さて、Gemini AdvancedでGemini 1.5 Proを使ったデータ分析を実践してみました。データのアップロードやPythonのコードを生成してのデータ分析や可視化が可能で、特にGoogle Sheetsなどとのシームレスな連携が便利かと思いました。ただ、ChatGPT-4oによる同様の分析と比較すると、可視化のクオリティはChatGPT-4oの方が優れていると感じました。
ただし、厳しい視点で両者の結果を見ますと、生成する解析コードは冗長であり、可視化のスタイルに関しても改善の余地があると感じました。また、プロンプト(自然言語)での分析指示は、コードを自分で書くのと比較すると隔靴掻痒で微調整が難しく、あまり確実でありません。Pythonやデータ分析の知識がないと、これらのコードの内容の検証は難しいため、非専門家が手軽に利用した場合、誤った結果を受け入れる可能性があると思われます。結局のところ、生成AIはあくまで利用者をサポートするツールであって、利用者が十分に真偽を判断できないことには使わない方が良いでしょうね。グラフの微調整や正確な分析をするならBIツールやExcelの使い方を勉強する方が早く確実です。GeminiやChatGPTにデータを分析させるのではなく、分析の進め方やツールの利用方法について相談する方が適切な生成AIとの付き合い方かと思います。
わりと厳しい意見になってしまいましたが、生成AIが分析のサポートに使えないわけではありません。GitHub Copilotを使うと分析コードの提案や補完ができるので、非常に有益なツールとなります。

グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD