2023.06.28
Cloud Spanner ~やさしいはじめ方~
次世代システム研究室の Y.I です。NewSQL の本命 Cloud Spanner の入門ガイドをまとめます。Cloud Spanner は料金が高いとかGlobal規模のDBは不要などと敬遠することが多く触る機会が少ない DB の一つだと思います。そのため、初めて操作する方向けに操作方法や複数のクライアントツールをご紹介します。本記事をご覧いただければ、Spanner DB の構築から各種ツールでの操作の仕方を理解して頂けます。少なくとも難しいものではないのだと感じて頂けると思います。
Cloud Spanner の主な特徴
Cloud Spanner は Google Cloud が提供するマネージドデータベースで、以下のような特徴を持っています。
・「水平スケーラビリティ」: Cloud Spannerはデータとトランザクションを自動的に分散させ、数百万のリクエスト/秒を処理できます。
・「強力なトランザクション一貫性」: Cloud Spannerは、分散されたデータでもSQLとACIDトランザクションを利用できます。
・「グローバルな分散」: データを自動的に複製し、低レイテンシでのグローバルアクセスを可能にします。
中でも水平スケーラビリティは強力でサービス無停止でノード数のスケールアウトやスケールインが可能です。
クライアントツール
今回ご紹介する Cloud Spanner 向けのクライアントツールはこちらになります。
今回は、 gcloud コマンドと spanner-cli コマンドを中心に、DDL(CREATE/DROPなど)やDML(INSERT/SELECTなど)の実行方法をまとめていきます。他ツールに関しては簡潔に説明します。
GCP WebConsole
GCP 公式の GUI WebConsole で Spanner の操作が可能です。DB や TABLEの作成から SELECT などのクエリーの実行も可能です。クエリーに関しては、都度シンタックスチェックをおこなってくれ、クエリー入力補完が便利です。
GCP WebConsole の Spanner 画面イメージです。こちらの画面で Spanner へ SQL を実行できます。
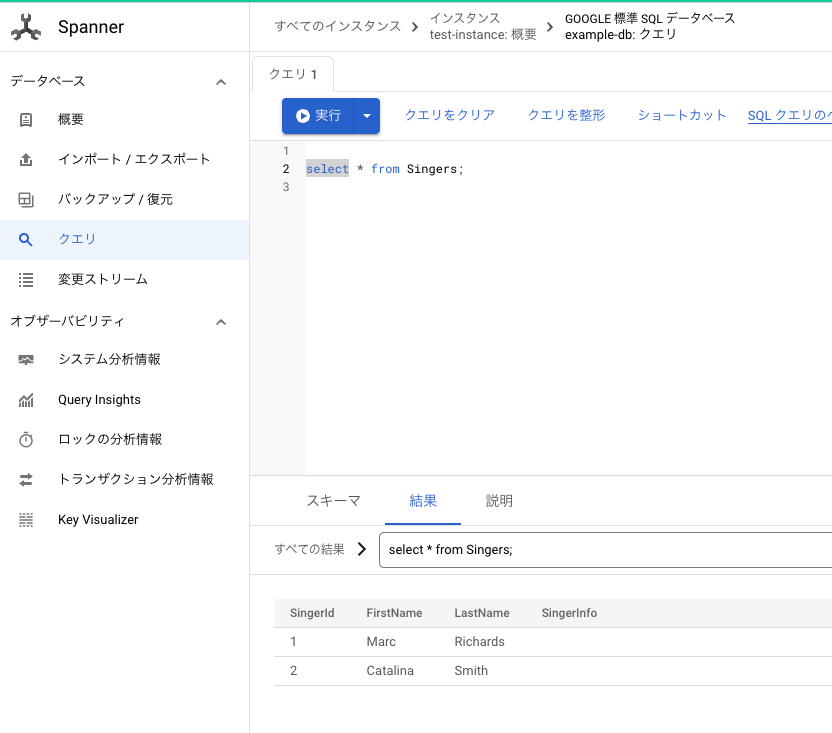
Cloud Spanner WebConsole
gcloud コマンド
GCP SDK のインストールで利用可能となる CUI コマンドです。一通りの Spanner 操作が可能で、バッチ処理をコマンドラインから実行するには、本ツールを使うのが便利です。ですが MySQL、 PostgreSQL や Oracle の cli コマンドのように接続した状態で SQL を続けて実行出来なかったり、独自な指定の仕方のため対話的に使う用途には向いていません。
spanner-cli コマンド
コミュニティで開発を進めている CUI コマンドです。spanner-cli は mysql コマンドライクに spanner を操作できます。再現性は高く、テーブル一覧表示や DB の切り替えなど mysql と同じように操作できます。 DB や TABLE の作成から SELECT などの SQL の実行が可能です。
インストール方法と接続方法です。インストールはインストール後に PATH を通すのみで完了します。接続はプロジェクトID、インスタンス名、DB名を指定して接続します。接続後のプロンプトも指定することができます。
# インストール go install github.com/cloudspannerecosystem/spanner-cli@latest # PATHを通す export PATH="$HOME/go/bin:$PATH" # Spanner への接続 spanner-cli -p my-project -i test-instance -d example-db \ --prompt='[\p:\i:\d]\t> ' ※prompt: projectid, instance, database が常に表示される (mysqlと同様)
DBeaver デスクトップクライアント
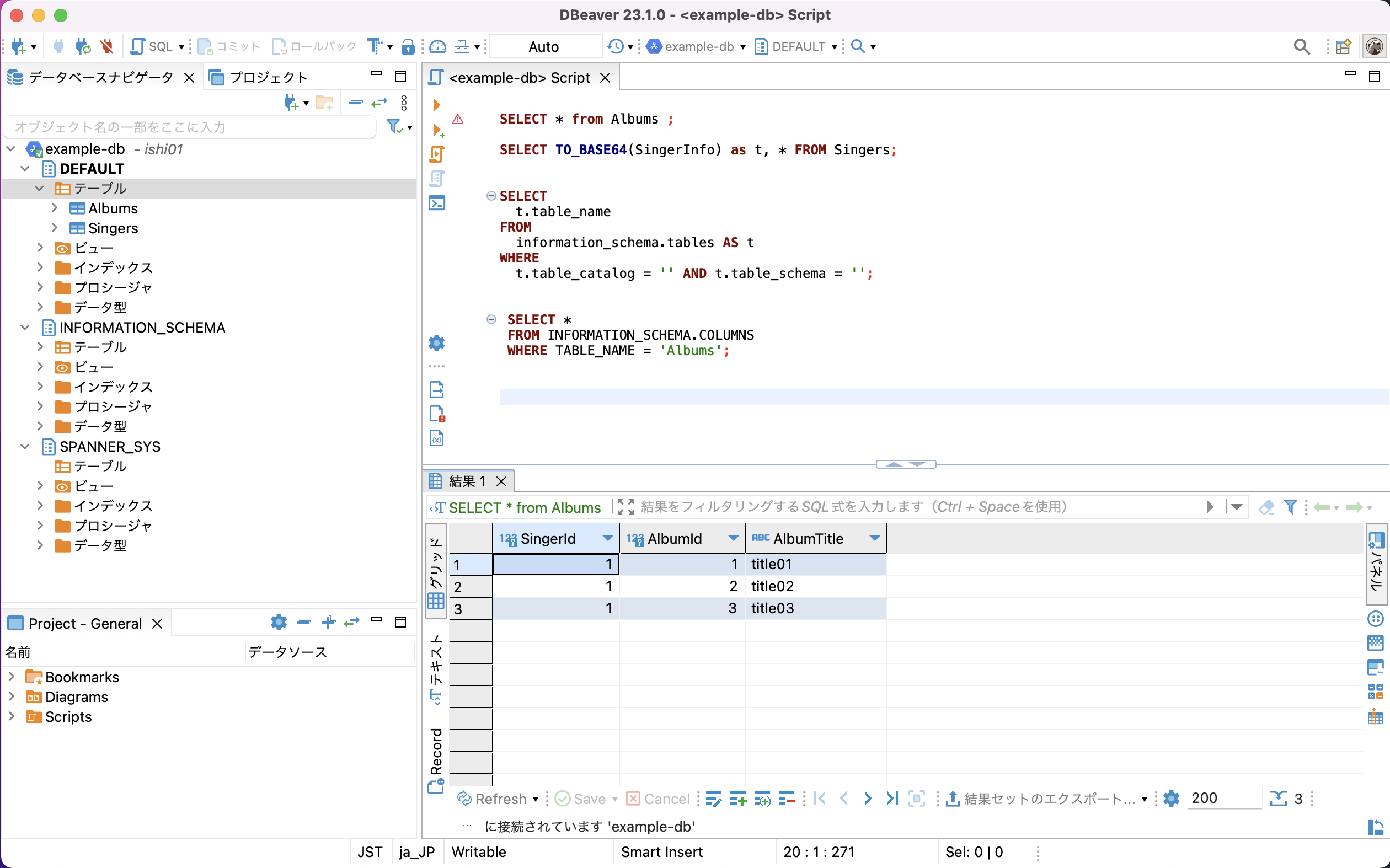
Windows, Mac, Linux で利用可能なフリーの GUI マルチプラットフォームデータベースツールです。JDBC driver で接続可能な多数の DB に接続可能です。DB や TABLE の表示や SQL クエリの実行、表形式での結果を表示や ER 図の作成など多数の機能を持っているツールです。有償版だと接続可能な DB が増え MongoDB や Cassandra など多数の DB にも接続可能です。ちなみに Spanner は、無料版で接続可能です。
DBeaver から Spanner へ接続した画面イメージです。SELECT を実行しています。このように他の DB デスクトップツールと同じような画面構成で同じような操作で Spanner 操作が可能です。
・Cloud Spanner, DBeaverからの接続
Spanner client libraries (Python code)
GCP 公式のクライアントライブラリでプログラムコードから Spanner の操作が可能となります。今回は、セットアップの仕方、Spanner に接続して SELECT を実行するサンプルコードをご紹介します。
インスタンス構築
WebConsole と gcloud コマンドで Spanner インスタンスを作成可能です。
GCP WebConsole
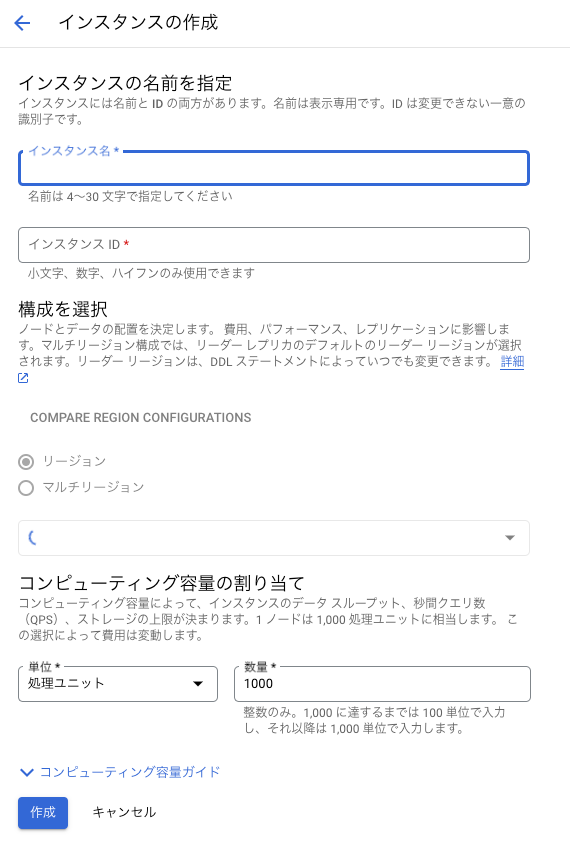
GCP WebConsole での Spanner インスタンスの作成は、 Spanner 画面を表示して 「インスタンスを作成」から必要情報を記入して「作成」ボタンをクリックするだけで構築できます。
必要情報は、インスタンス名、インスタンスID、リージョン構成(シングル or マルチ)、リージョン、ノード数です。
・Spanner インスタンス作成画面イメージ
gcloud コマンド
gcloud コマンドでの Spanner インスタンスの作成は、こちらになります。
gcloud spanner instances create test-instance \
--config=regional-us-central1 \
--description='My Instance' \
--nodes=1
実行結果 (1秒かからずに完了します)
spanner $ time gcloud spanner instances create test-instance --config=regional-us-central1 \
--description='My Instance' --nodes=1
Creating instance...done.
gcloud spanner instances create test-instance --config=regional-us-central1 0.46s user 0.22s system 12% cpu 5.446 total
SQL操作
以降の操作は、 gcloud コマンドと spanner-cli での操作方法をご紹介します。
DB 作成
gcloud コマンド
gcloud コマンドでの DB 作方法はこちらです。default instance を設定すれば instance は省略可能ですが操作ミスが怖いので都度指定することをお勧めします。
gcloud spanner databases create example-db --instance=test-instance
実行結果
spanner $ gcloud spanner databases create example-db --instance=test-instance Creating database...done.
spanner-cli コマンド
spanner-cli は IF NOT EXISTS 使えません。またアンダースコア( _ )をDB名に指定することはできません。gcloud コマンドは指定可能です。今後改善されるかもしれませんね。
CREATE DATABASE example_db; # 接続先DBを切り替え use example_db;
実行結果
spanner> CREATE DATABASE example_db; Query OK, 0 rows affected (5.46 sec)
TABLE 作成
gcloud コマンド;
- 親テーブル gcloud spanner databases ddl update example-db --instance=test-instance \ --ddl='CREATE TABLE Singers ( SingerId INT64 NOT NULL, FirstName STRING(1024), LastName STRING(1024), SingerInfo BYTES(MAX) ) PRIMARY KEY (SingerId)' - 子テーブル gcloud spanner databases ddl update example-db --instance=test-instance \ --ddl='CREATE TABLE Albums ( SingerId INT64 NOT NULL, AlbumId INT64 NOT NULL, AlbumTitle STRING(MAX)) PRIMARY KEY (SingerId, AlbumId), INTERLEAVE IN PARENT Singers ON DELETE CASCADE'
実行結果
spanner $ gcloud spanner databases ddl update example-db --instance=test-instance \ --ddl='CREATE TABLE Singers ( SingerId INT64 NOT NULL, FirstName STRING(1024), LastName STRING(1024), SingerInfo BYTES(MAX) ) PRIMARY KEY (SingerId)' Schema updating...done. spanner $ gcloud spanner databases ddl update example-db --instance=test-instance \ --ddl='CREATE TABLE Albums ( SingerId INT64 NOT NULL, AlbumId INT64 NOT NULL, AlbumTitle STRING(MAX)) PRIMARY KEY (SingerId, AlbumId), INTERLEAVE IN PARENT Singers ON DELETE CASCADE' Schema updating...done.
spanner-cli コマンド
- 親テーブル CREATE TABLE IF NOT EXISTS Singers ( SingerId INT64 NOT NULL, FirstName STRING(1024), LastName STRING(1024), SingerInfo BYTES(MAX), ) PRIMARY KEY (SingerId); - 子テーブル CREATE TABLE IF NOT EXISTS Albums ( SingerId INT64 NOT NULL, AlbumId INT64 NOT NULL, AlbumTitle STRING(MAX), ) PRIMARY KEY (SingerId, AlbumId), INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
テーブル作成には IF NOT EXISTS を利用可能です。
実行結果
- 親テーブル
spanner> CREATE TABLE IF NOT EXISTS Singers (
-> SingerId INT64 NOT NULL,
-> FirstName STRING(1024),
-> LastName STRING(1024),
-> SingerInfo BYTES(MAX),
-> ) PRIMARY KEY (SingerId);
Query OK, 0 rows affected (6.63 sec)
- 子テーブル
spanner> CREATE TABLE IF NOT EXISTS Albums (
-> SingerId INT64 NOT NULL,
-> AlbumId INT64 NOT NULL,
-> AlbumTitle STRING(MAX),
-> ) PRIMARY KEY (SingerId, AlbumId),
-> INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
Query OK, 0 rows affected (3.82 sec)
INSERT
gcloud コマンド
SQL の INSERT 文ではなく、データ箇所をカラム名=値でカンマ(,)区切りで指定します。
gcloud spanner rows insert --database=example-db --instance=test-instance \
--table=Singers \
--data=SingerId=1,FirstName=Marc,LastName=Richards
実行結果
5件のデータを登録しました。
spanner $ time gcloud spanner rows insert --database=example-db --instance=test-instance \
--table=Singers \
--data=SingerId=1,FirstName=Marc,LastName=Richards
commitTimestamp: '2023-06-22T00:29:18.812366Z'
gcloud spanner rows insert --database=example-db --instance=test-instance 0.42s user 0.18s system 5% cpu 11.625 total
spanner $ gcloud spanner rows insert --database=example-db --instance=test-instance \
--table=Singers \
--data=SingerId=2,FirstName=Catalina,LastName=Smith
commitTimestamp: '2023-06-22T00:29:41.901447Z'
spanner $ time gcloud spanner rows insert --database=example-db --instance=test-instance \
--table=Albums \
--data=SingerId=1,AlbumId=1,AlbumTitle="Total Junk"
commitTimestamp: '2023-06-22T00:29:54.783338Z'
gcloud spanner rows insert --database=example-db --instance=test-instance 0.39s user 0.15s system 5% cpu 9.341 total
spanner $ time gcloud spanner rows insert --database=example-db --instance=test-instance \
--table=Albums \
--data=SingerId=2,AlbumId=1,AlbumTitle="Green"
commitTimestamp: '2023-06-22T00:30:07.483402Z'
gcloud spanner rows insert --database=example-db --instance=test-instance 0.40s user 0.15s system 6% cpu 9.002 total
spanner $ time gcloud spanner rows insert --database=example-db --instance=test-instance \
--table=Albums \
--data=SingerId=2:AlbumId=2:AlbumTitle="Go, Go, Go"
commitTimestamp: '2023-06-22T00:30:21.020200Z'
gcloud spanner rows insert --database=example-db --instance=test-instance 0.41s user 0.16s system 6% cpu 8.785 total
gcloud コマンドだと都度 Spanner に接続するので実行時間がかかる印象を受けました。最小の1ノードでの結果ですが、データ登録に0.4secかかっています。
spanner-cli コマンド
- 親テーブル INSERT INTO Singers (SingerId, FirstName, LastName) VALUES (1, 'Marc', 'Richards'), (2, 'Catalina', 'Smith'); - 子テーブル INSERT INTO Albums (SingerId, AlbumId, AlbumTitle) VALUES (1, 1, 'Total Junk'), (2, 1, 'Green'), (2, 2, 'Go, Go, Go');
実行結果
- 親テーブル spanner> INSERT INTO Singers (SingerId, FirstName, LastName) VALUES (1, 'Marc', 'Richards'), (2, 'Catalina', 'Smith'); Query OK, 2 rows affected (2.61 sec) - 子テーブル spanner> INSERT INTO Albums (SingerId, AlbumId, AlbumTitle) VALUES (1, 1, 'Total Junk'), (2, 1, 'Green'), (2, 2, 'Go, Go, Go'); Query OK, 3 rows affected (0.58 sec)
SELECT
gcloud コマンド
gcloud spanner databases execute-sql example-db --instance=test-instance \
--sql='SELECT SingerId, AlbumId, AlbumTitle FROM Albums'
実行結果
spanner $ time gcloud spanner databases execute-sql example-db --instance=test-instance \
--sql='SELECT SingerId, AlbumId, AlbumTitle FROM Albums'
SingerId AlbumId AlbumTitle
1 1 Total Junk
2 1 Green
2 2 Go, Go, Go
gcloud spanner databases execute-sql example-db --instance=test-instance 0.38s user 0.17s system 6% cpu 8.421 total
spanner-cli コマンド
SELECT SingerId, AlbumId, AlbumTitle FROM Albums;
実行結果
spanner> SELECT SingerId, AlbumId, AlbumTitle FROM Albums; +----------+---------+------------+ | SingerId | AlbumId | AlbumTitle | +----------+---------+------------+ | 1 | 1 | Total Junk | | 2 | 1 | Green | | 2 | 2 | Go, Go, Go | +----------+---------+------------+ 3 rows in set (7.46 msecs) - 垂直表示も可能 ( \G ) spanner> SELECT SingerId, AlbumId, AlbumTitle FROM Albums\G *************************** 1. row *************************** SingerId: 1 AlbumId: 1 AlbumTitle: Total Junk *************************** 2. row *************************** SingerId: 2 AlbumId: 1 AlbumTitle: Green *************************** 3. row *************************** SingerId: 2 AlbumId: 2 AlbumTitle: Go, Go, Go 3 rows in set (7.16 msecs)
SELECT 結果の表示形式は mysql コマンドと同じ形式で表示されます。
DELETE
gcloud コマンド
キーはカンマ(,)区切りで複数指定できます。
gcloud spanner rows delete --table=Singers --database=example-db --instance=test-instance --keys=1
実行結果
spanner $ time gcloud spanner rows delete --table=Singers --database=example-db --instance=test-instance --keys=1 gcloud spanner rows delete --table=Singers --database=example-db --keys=1 0.39s user 0.19s system 5% cpu 10.000 total
spanner-cli コマンド
DELETE FROM Singers WHERE SingerId = 1;
実行結果
spanner> DELETE FROM Singers WHERE SingerId = 1; Query OK, 1 rows affected (1.47 sec)
TABLE 削除
gcloud コマンド
gcloud spanner databases ddl update example-db --instance=test-instance \ --ddl='DROP TABLE Albums'
実行結果
spanner $ time gcloud spanner databases ddl update example-db --instance=test-instance \ --ddl='DROP TABLE Albums' Schema updating...done. gcloud spanner databases ddl update example-db --instance=test-instance 0.36s user 0.16s system 10% cpu 4.935 total
spanner-cli コマンド
DROP TABLE IF EXISTS Albums;
実行結果
spanner> DROP TABLE IF EXISTS Albums; Query OK, 0 rows affected (5.67 sec)
DB 削除
gcloud コマンド
gcloud spanner databases delete example-db --instance=test-instance
実行結果
spanner $ time gcloud spanner databases delete example-db --instance=test-instance You are about to delete database: [example-db] Do you want to continue (Y/n)? Y gcloud spanner databases delete example-db --instance=test-instance 0.37s user 0.17s system 12% cpu 4.340 total
spanner-cli コマンド
DROP DATABASE example_db;
カレントDBを削除することはできません。 use DB_NAME; 変更してから削除します。
実行結果
spanner> DROP DATABASE example_db; Database "example_db" will be dropped. Do you want to continue? [yes/no] yes Query OK, 0 rows affected (1.06 sec)
Spanner client libraries (Python code)
Python から Spanner を扱うサンプルコードです。 Spanner に接続して SELECT します。
# Imports the Google Cloud Client Library.
from google.cloud import spanner
# Your Cloud Spanner instance ID.
instance_id = "test-instance"
#
# Your Cloud Spanner database ID.
database_id = "example-db"
# Instantiate a client.
spanner_client = spanner.Client()
# Get a Cloud Spanner instance by ID.
instance = spanner_client.instance(instance_id)
# Get a Cloud Spanner database by ID.
database = instance.database(database_id)
# Execute a simple SQL statement.
with database.snapshot() as snapshot:
results = snapshot.execute_sql("SELECT * FROM Albums LIMIT 10")
for row in results:
print(row)
インスタンス削除
Spanner インスタンスの削除は、 gcloud コマンドと GCP WebConsole で行えます。不必要に課金され続けないように不要になったらインスタンスを削除しましょう。
gcloud コマンド
gcloud spanner instances delete test-instance
実行結果
spanner $ time gcloud spanner instances delete test-instance Delete instance [test-instance]. Are you sure? Do you want to continue (Y/n)? Y gcloud spanner instances delete test-instance 0.34s user 0.17s system 12% cpu 3.955 total
参考
GCP公式-gcloud CLI を使用してデータベースを作成してクエリを実行する
GCP公式 Spanner client libraries
spanner-cli
DBeaver
まとめ
今回は Spanner の入り口としてクライアントツールにまとめましたが、 Spanner を操作するイメージが掴めたでしょうか? クライアントツールの基本は、GCP 公式の WebConsole と gcloud コマンドなのでしょうが、 個人的には spanner-cli が使いやすいと感じました。複数のターミナルで spanner-cli を利用すれば、同時に複数の接続を容易に試すことができます。何より MySQL を使う方は、すぐに Spanner を操作できると思います。
最後に
グループ研究開発本部では、グループ全体のインテグレーションを支援してくれるアーキテクトを募集しています。多数の各グループ案件を支援する機会があるため多数の技術に触れる機会があります。アプリケーション開発の方、次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD