2025.01.13
Cloud DMSを使ってCloud SQLにDB移行してみる
こんにちは。次世代システム研究室のM.Mです。
Google Cloudには簡単にCloud SQLへDB移設ができるサービスがあります。
Database Migration Service(DMS)と呼ばれ、以下のような特徴があります。
- オンプレミス、Google Cloud、または他のクラウドからクラウドのオープンソース データベースに移行する
- データを継続的にレプリケートして最小限のダウンタイムで移行を実現
- AI を活用した支援により、スキーマとコードをシームレスに変換
- サーバーレスでセットアップが簡単
DMSを使ってどれぐらい簡単にDB移設ができるか確認したいと思います。
今回は、Compute Engine上で稼働しているPostgreSQL 13をCloud SQL PostgreSQL 16に移行してみます。
1. 移設元DBについて
移設元DBはCompute Engine上で稼働しており、以下のような状態になっています。
- レプリケーションは行っていない
- Cloud Runで動いているWEBアプリから利用(参照・更新)されている
- mmtestdbというデータベースにCloud Runで動いているWEBアプリから接続するapp_userが存在しているだけ
- mmtestdbにはhogeusersというテーブルが存在しているだけ
mmtestdb=> \dt
List of relations
Schema | Name | Type | Owner
--------+-----------+-------+----------
public | hogeusers | table | app_user
(1 row)
mmtestdb=> \d hogeusers
Table "public.hogeusers"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+---------------------------------------
id | integer | | not null | nextval('hogeusers_id_seq'::regclass)
name | text | | |
Indexes:
"hogeusers_pkey" PRIMARY KEY, btree (id)
2. 前提条件を確認する

pglogicalのインストールが必要になるようです。

WEBアプリで使っているapp_userを利用する訳にもいかないので、移行元インスタンスに接続するレプリケーション用ユーザーを作って権限設定をする必要がありそうです。
今回のレプリケーションをしていないような移行元DBの場合、準備段階で再起動が必要になりますね…
3. 移行元DBの設定を行う
■ レプリケーション用ユーザーの作成
createuser --replication -P repl_user
■ pglogicalのインストール
sudo dnf install -y pglogical_13
■ pglogical有効化
・postgresql.confの以下の2か所を修正します
#shared_preload_libraries = '' ↓ pglogicalにする shared_preload_libraries = 'pglogical'
#wal_level = replica ↓ logicalにする wal_level = logical
shared_preload_librariesを変更する場合、DBの再起動が必要になるので、DBの再起動を行います。
これでpglogicalが利用できる状態になりました。
続いて権限設定を行っていきます。
■ 権限設定
postgres DBと移設対象DB(mmtestdb)に対して権限設定を行います。
postgres DBに対して
postgres=# \dn List of schemas Name | Owner --------+---------- public | postgres (1 row) postgres=# select current_database(); current_database ------------------ postgres (1 row) postgres=# CREATE EXTENSION IF NOT EXISTS pglogical; postgres=# \dn List of schemas Name | Owner -----------+---------- pglogical | postgres public | postgres (2 rows) postgres=# GRANT USAGE on SCHEMA public to repl_user; postgres=# GRANT USAGE on SCHEMA pglogical to repl_user; postgres=# GRANT SELECT on ALL TABLES in SCHEMA pglogical to repl_user; postgres=# GRANT SELECT on ALL TABLES in SCHEMA public to repl_user; postgres=# GRANT SELECT on ALL SEQUENCES in SCHEMA pglogical to repl_user; postgres=# GRANT SELECT on ALL SEQUENCES in SCHEMA public to repl_user;
移設対象DB(mmtestdb)に対して
mmtestdb=# \dn List of schemas Name | Owner --------+---------- public | postgres (1 row) mmtestdb=# select current_database(); current_database ------------------ mmtestdb (1 row) mmtestdb=# CREATE EXTENSION IF NOT EXISTS pglogical; mmtestdb=# \dn List of schemas Name | Owner -----------+---------- pglogical | postgres public | postgres (2 rows) mmtestdb=# GRANT USAGE on SCHEMA public to repl_user; mmtestdb=# GRANT USAGE on SCHEMA pglogical to repl_user; mmtestdb=# GRANT SELECT on ALL TABLES in SCHEMA pglogical to repl_user; mmtestdb=# GRANT SELECT on ALL TABLES in SCHEMA public to repl_user; mmtestdb=# GRANT SELECT on ALL SEQUENCES in SCHEMA pglogical to repl_user; mmtestdb=# GRANT SELECT on ALL SEQUENCES in SCHEMA public to repl_user;
DBを再起動すると、以下のようなログが出力されpglogical対象DBに対して有効になっていることが確認できます
2024-12-27 04:30:51.208 UTC [8258] LOG: starting pglogical supervisor 2024-12-27 04:30:51.223 UTC [8260] LOG: starting pglogical database manager for database postgres 2024-12-27 04:30:51.236 UTC [8261] LOG: starting pglogical database manager for database mmtestdb
移行元DBの設定はこれで完了ですが、移行先Cloud SQLから接続できるようにしなければなりません。
続いてCloud SQLから移行元DBへの接続許可設定を行います。
4. 移行先Cloud SQLからの接続許可設定
移行先Cloud SQLとレプリケーションを行うことになるので、移行先Cloud SQLからCompute Engine上のPostgreSQLに接続できるようにしなければなりません。
今回は同じGoogle Cloudのプロジェクト、同じVPCネットワークを利用したプライベートサービスアクセスでの接続にするので、以下のようにプライベートサービスアクセスの設定を確認し、Cloud SQLに割り当てられる内部IPアドレスの範囲を確認します。
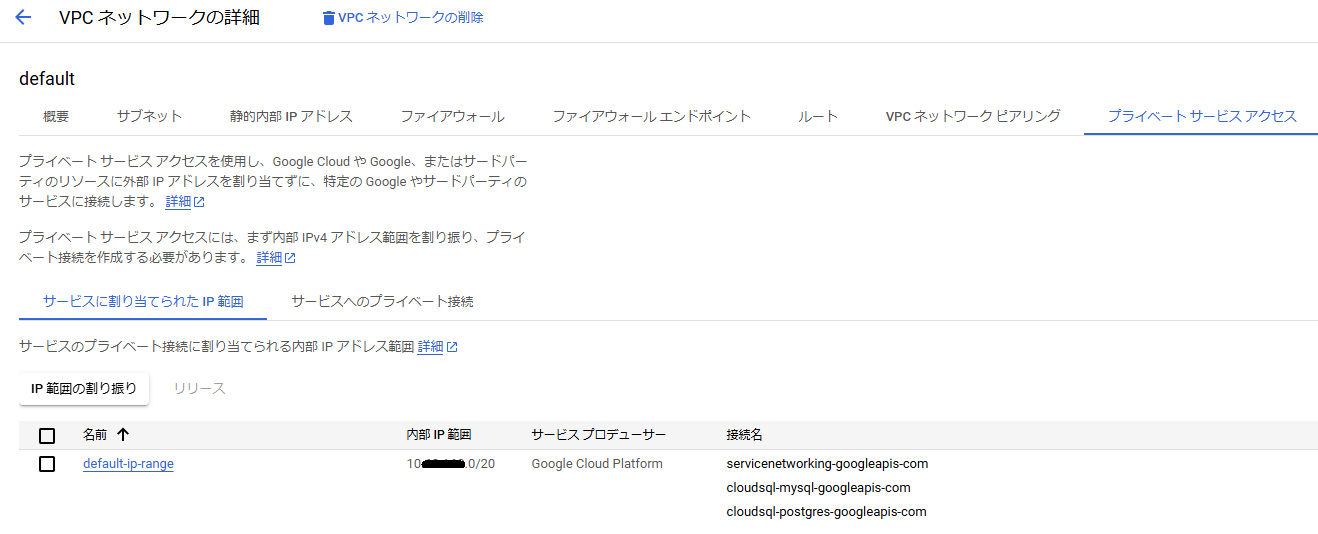
続いてファイアウォールの設定にて上記内部IPアドレスから5432ポートでのアクセスを許可するファイアウォールルールを追加します。
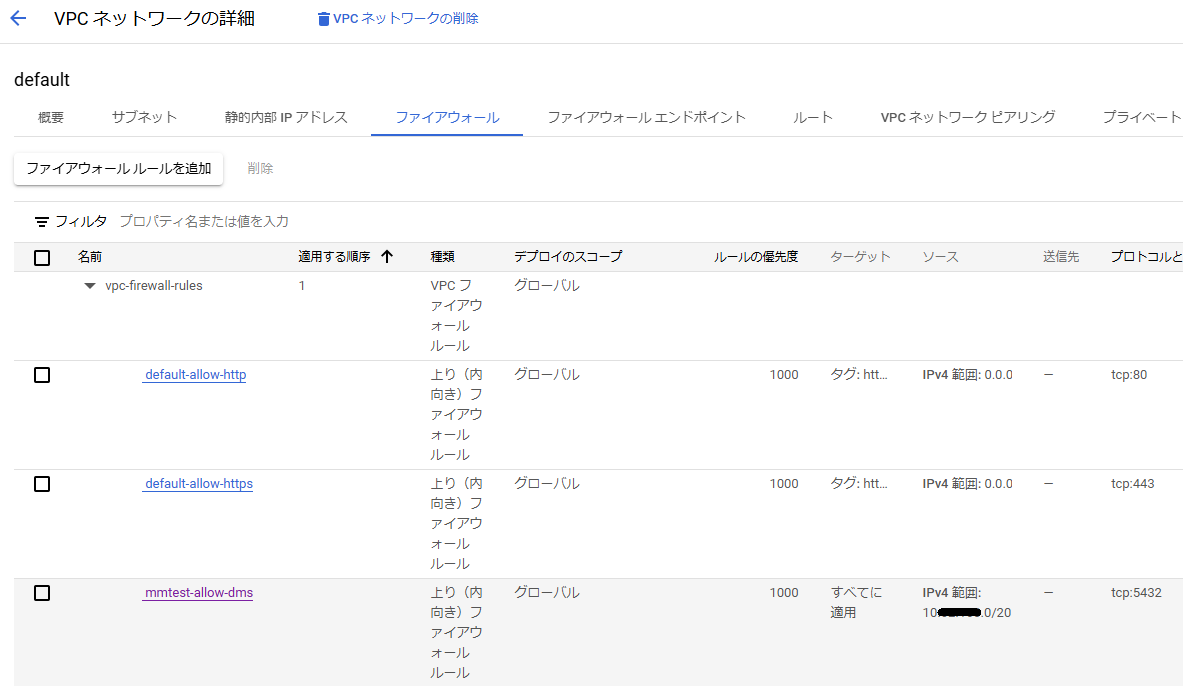
さらに移行元PostgreSQLの接続設定も上記内部IPアドレスからのアクセスを許可する必要があります。
以下の図のようにpg_hba.confに接続設定を追加します。
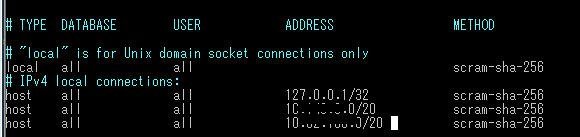
Cloud RunのWEBアプリから利用されている前提なので設定済みですが、postgresql.confのlisten_addressesも許可する必要があります。
これで移行元の接続設定が完了しました。
これでようやくDMS側の作業に入れます。
5. DMS – 接続プロファイルの作成
移行元DBのプロファイルを以下のように作成します。
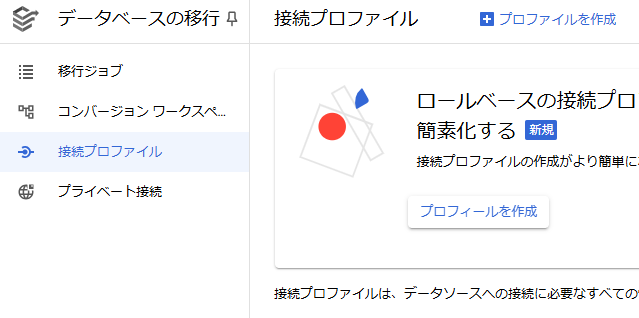
左メニューにある接続プロファイルを選択し、「プロファイルを作成」から作成することができます。
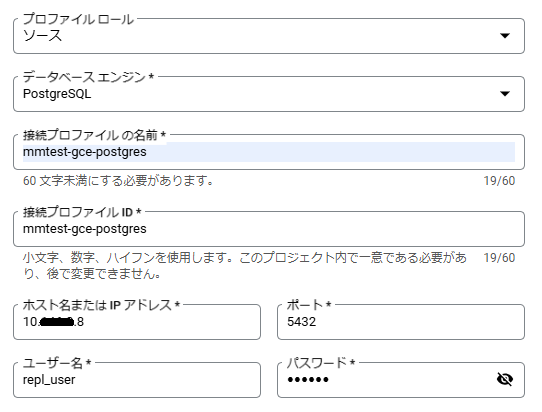
Compute EngineのプライベートIPを指定、ユーザー名には上記にて作ったレプリケーション用ユーザーを指定します。
移行元DBのプロファイルを作成しても、このタイミングで接続確認は行われません。
この後の移行ジョブの作成の際に、このプロファイルを利用して接続確認が行われることになります。
6. DMS – 移行ジョブの作成
移行ジョブを以下のように作成します。

左メニューにある移行ジョブを選択し、「移行ジョブを作成」から作成することができます。
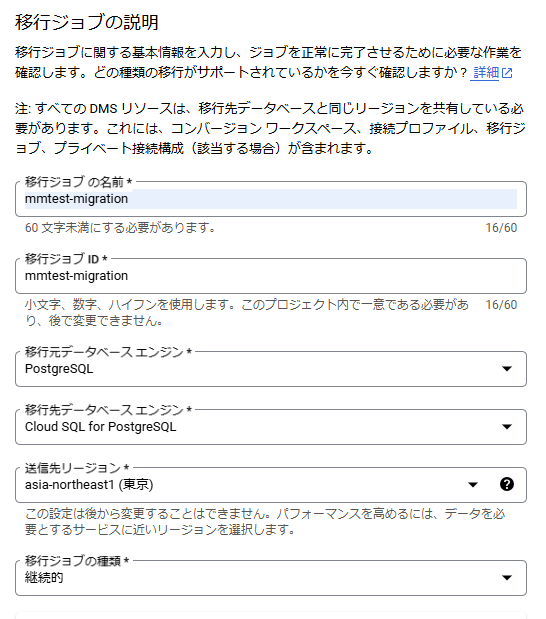
移行元データベースエンジンにPostgreSQL、移行先データベースエンジンにCloud SQL for PostgreSQLを選びます。
続いて、移行元の定義を行います。
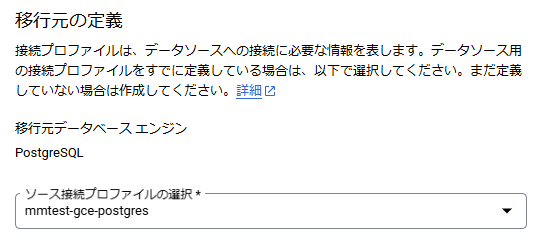
移行元の定義では、上記にて作成した接続プロファイルを選択します。
続いて、移設先の定義を行います。
既存のCloud SQLインスタンスを指定することもできますが、今回はこのタイミングで新しいCloud SQLのインスタンスを作成することにします。
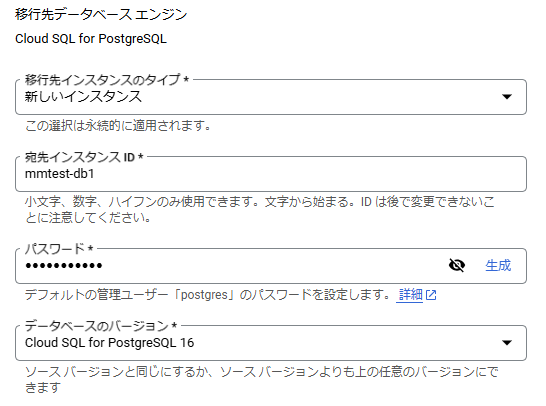
新しいCloud SQLのインスタンスを作成する場合、ここでCloud SQLのスペックなどを決めていくことになります。
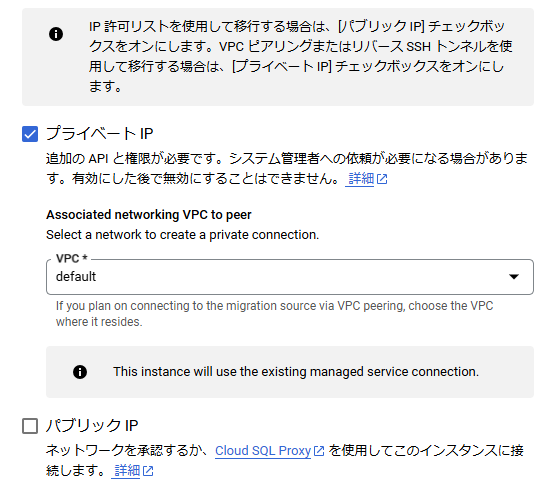
また、VPCピアリングを利用して移行するため、以下のようにプライベートIPを有効にして、不要なパブリックIPは無効にしておきます。
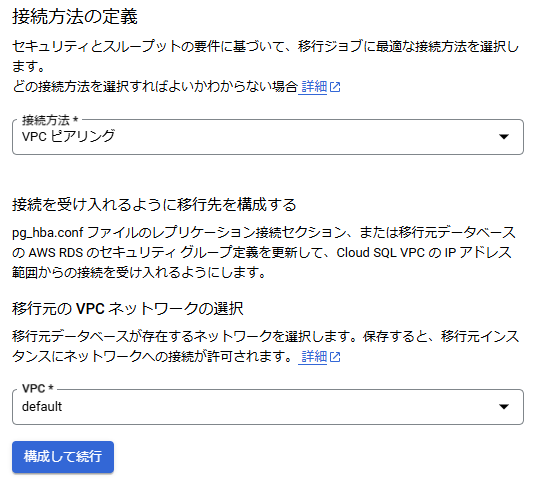
そして最後まで進むと、以下のように移行ジョブをテストすることができるので、ジョブをテストして接続に問題ないか確認します。

問題なければ、「ジョブを作成」にて移行ジョブを作成します。
(検証の準備をしてから開始したいので、「ジョブを作成して開始」にはしません。)
すると、以下のように開始前の状態で作成されます。

移行先Cloud SQLも起動していない状態になっています。
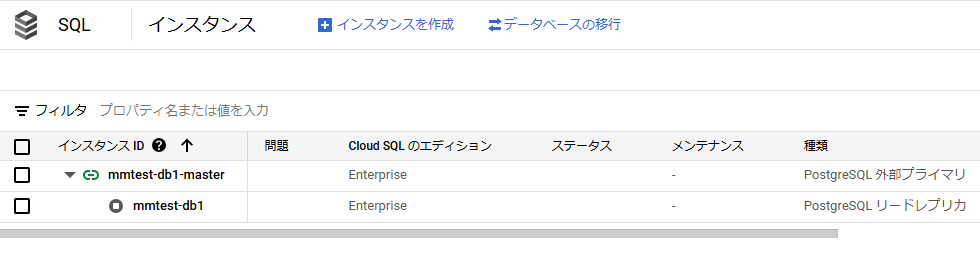
mmtest-db01-masterが移設元DB、mmtest-db1が移設先のCloud SQLでリードレプリカとなりレプリケーション前の状態になっています。
7. DMS – 移行ジョブの開始
検証としてテストデータを5000万件登録しておきます。
INSERT INTO hogeusers(name)
SELECT
format('hogehoge_%s', i)
FROM
generate_series(1,50000000) as i
;
mmtestdb=> select count(1) from hogeusers;
count
----------
50003304
(1 row)
Cloud Runで動いているWEBアプリからの登録を試していたので、3304件多くなっていますが、5000万件登録しました。
また、ジョブを開始する前に、Cloud RunのWEBアプリから、参照15rps、登録15rpsでアクセスしている状態で移行ジョブを開始し、移行中にWEBアプリに影響が及ぶかも確認します。
では移行ジョブを開始します。
すると以下の図にようにステータスが「開始しています」に変わります。
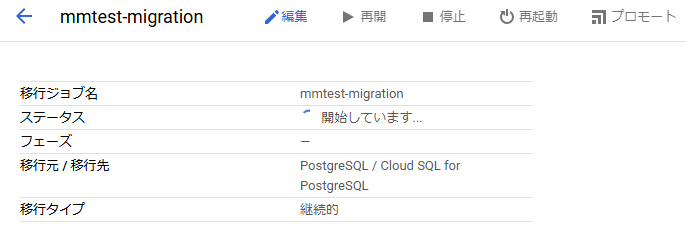
その後、ステータスは「完全なダンプ」、「CDC」に変わります。
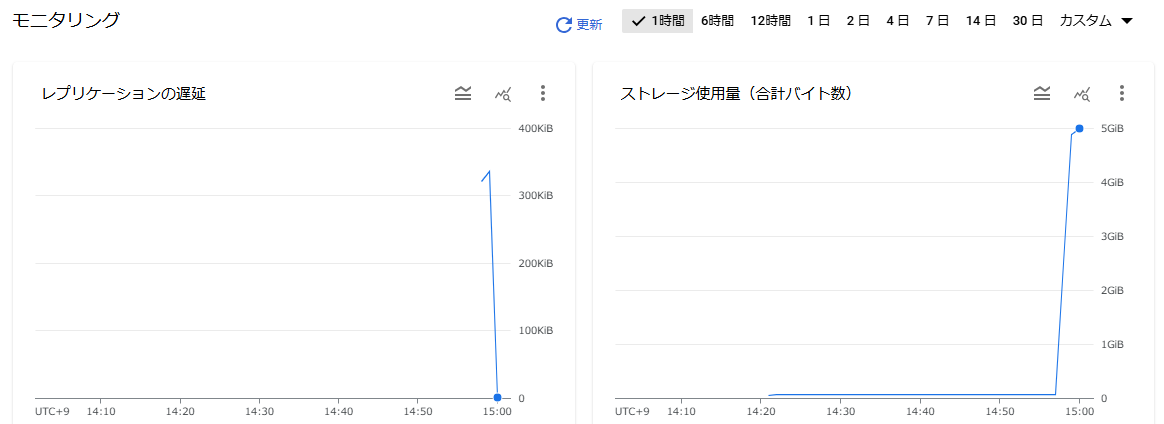
5000万件登録したので、一気に5GBまでストレージ使用量があがり、レプリ遅延も収まっていきます。
では、Cloud RunのWEBアプリからの参照や登録処理に影響があったのでしょうか?
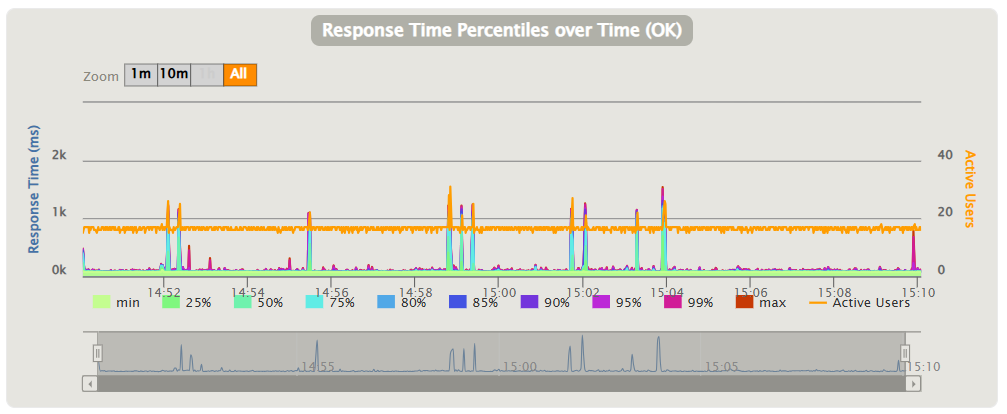
特にエラーは発生しておらず、完全なダンプが行われた時間14:58~15:00の間で少し遅延がでたかなというレベル。
ただ、完全なダンプが終わってからも、15:02や15:04で遅延がでているので、ダンプが原因とも言いにくい…
完全なダンプではどのような処理が行われていたのか、SQLのログを確認してみます。
2024-12-27 05:56:51.014 UTC [10451] LOG: duration: 0.180 ms statement: BEGIN TRANSACTION ISOLATION LEVEL REPEATABLE READ, READ ONLY;
SET DATESTYLE = ISO;
SET INTERVALSTYLE = POSTGRES;
SET extra_float_digits TO 3;
SET statement_timeout = 0;
SET lock_timeout = 0;
SET TRANSACTION SNAPSHOT '0000000A-00000005-1';
...
2024-12-27 05:57:29.196 UTC [10451] LOG: duration: 38160.385 ms statement: COPY "public"."hogeusers" ("id","name") TO stdout
テーブルロックをかけたりはしていない模様。
ただ、Compute Engineの負荷は以下のように完全なダンプのタイミングでかなり高くなっていました。
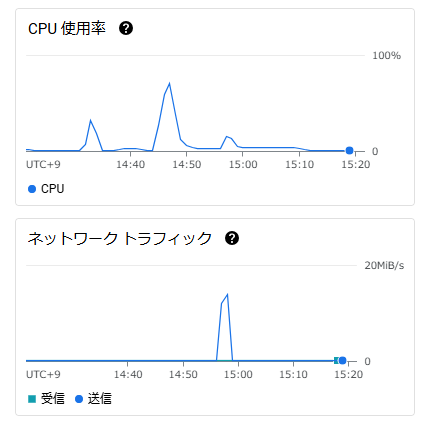
実際の本番環境ではテーブルやデータサイズ・件数はもっと多いので、テーブルロックがかからないにしろ、移行元DB自体が高負荷となりパフォーマンスが悪くなる可能性は十分ありそうです。
8. DMS – プロモート
リードレプリカとなっている移行先Cloud SQLをマスターに昇格させます。
以下の図にある「プロモート」から実施することができます。
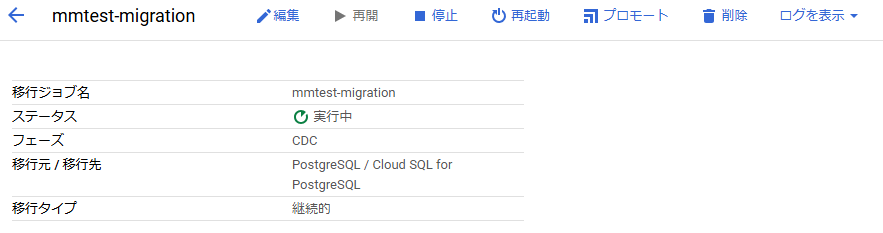
実行すると以下のようにステータスがPromotionに変わります。
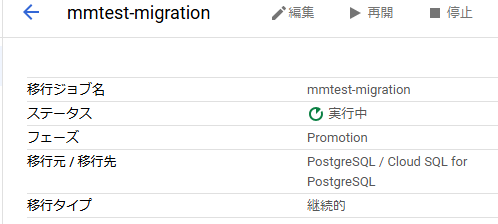
完了すると、Cloud SQLもレプリケーションの構成ではなくなり、以下のようにリードレプリカだったmmtest-db1がマスターに昇格している状態になります。
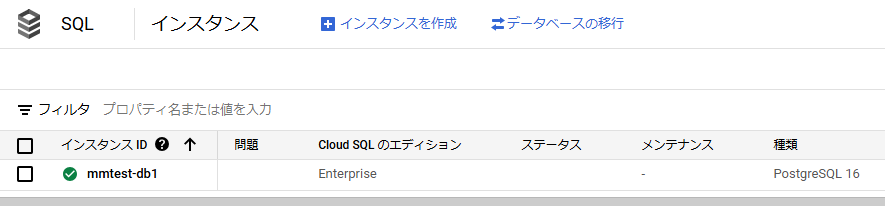
データ件数も同じで問題なく移行されておりました。
9. まとめ
今回はデータ件数も少なく、WEBアプリからの参照・更新も多くない状態での検証だったので、データ移行中にどれぐらい影響がでるか判断ができなかったのは残念ではありますが、DMSを使うことで、レプリケーションやデータ移行の知識がなくてもDB移設できることが分かりました。
大規模なデータベースの場合、ダンプ時の負荷の考慮は必要になりそうですが、非常に便利なデータベース移行サービスだと思います。
ただ、クラウドサービスを利用する上で、プライベートサービスアクセスやファイアウォールなど接続設定の知識は求められてしまいますね。
最後に、次世代システム研究室では、グループ全体のインテグレーションを支援してくれるアーキテクトを募集しています。アプリケーション開発の方、次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。
皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD