2024.04.05
BigQueryへWEBアプリケーションのログを登録してみる
こんにちは。次世代システム研究室のM.Mです。
WEBアプリケーションで独自のログを出力して調査や集計をしたいといった場合、どのようにすればよいでしょうか?
独自のログとはWEBサーバーのアクセスログといったものではなく、アクセスしたユーザーのIDであったり、そのユーザーに対してどのような処理が行われ、どのような結果で終わったかなど、運用・分析メンバーが、必要となるログ情報を定義し、開発メンバーが実装するような、より詳細なWEBアプリケーションのログを想定しています。
データベースに登録された情報で運用・分析ができるかもしれませんが、データベースには成功結果しかなく、どのような条件で失敗したのかなどが分からないケースもあると思っています。
ログを出力する方法はいろいろあると思いますが、GCPにて構築されたWEBアプリケーションであれば、BigQueryを利用するのが一番楽なのではないかと思います。
またその方法として、WEBアプリケーションとBigQueryを直接連携するのではなく、Pub/Subを利用して非同期で処理させるのが一般的となっているようです。
そのため、Pub/SubにはBigQueryサブスクリプションが用意されてあったり、DataFlowにも(Pub/Sub Subscription to BigQuery)というテンプレートが存在しています。
- Pub/Sub BigQueryサブスクリプション
- Pub/Sub + DataFlow(Pub/Sub Subscription to BigQuery)
ドキュメントには以下のような記載がありました。
このワークフローのメリットは、UDF を使用して Google 提供のストリーミング テンプレートを拡張できることです。Pub/Sub からデータを pull して BigQuery に出力する必要があるが、テンプレートを拡張する必要がない場合は、より簡単なワークフローで Pub/Sub から BigQuery へのサブスクリプション機能を使用できます。
DataFlowを利用するメリットとして、UDFを利用してデータ変換を行った後に、BigQueryに登録することができるようです。
今回はWEBアプリケーション開発者が実装する独自のログ出力が対象となるので、データ変換は必要にならないので、Pub/Sub BigQueryサブスクリプションを使ってログを登録させていきたいと思います。
その際に、ちょっとつまずいた点も共有できればと思います。
また最後に、ログ出力処理を追加することで、どれぐらいパフォーマンスに影響がでるのかも確認しようと思います。
1. BigQuery、Pub/Subの準備と簡易テスト
■BigQuery データセット&テーブルの作成
以下の構成で作成します。
- データセット: mmtest_dataset
- テーブル: mmtest_app_log
- フィールド
- user_id: INTEGER
- message: STRING
- logged_at: TIMESTAMP
- created_at: TIMESTAMP: CURRENT_TIMESTAMP()
- フィールド
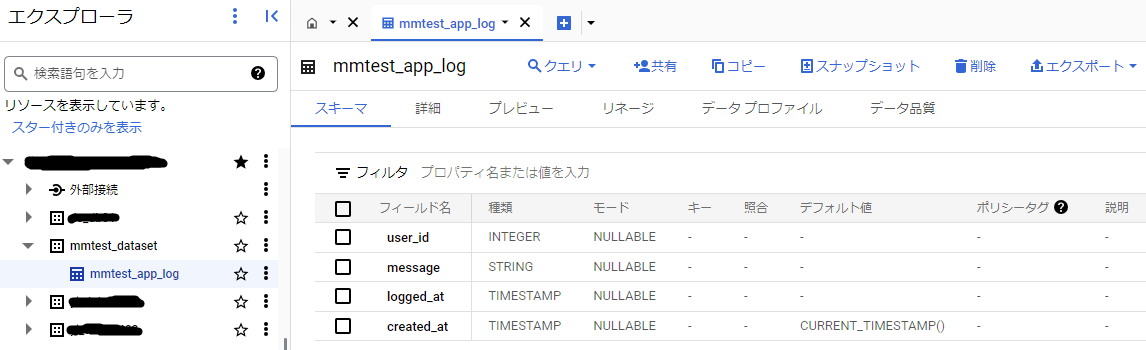
WEBアプリケーションからBigQueryに登録されるまでの時間を確認したいので、created_atにはデフォルト値としてCURRENT_TIMESTAMP()を設定しています。
■Pub/Subの作成
以下の構成で作成します。
- トピック: mmtest-topic
- サブスクリプション: mmtest-topic-sub
- 配信タイプ: BigQueryへの書き込み
- Schema Option: テーブルスキーマを使用する
サブスクリプションの設定のイメージは以下のようになります。
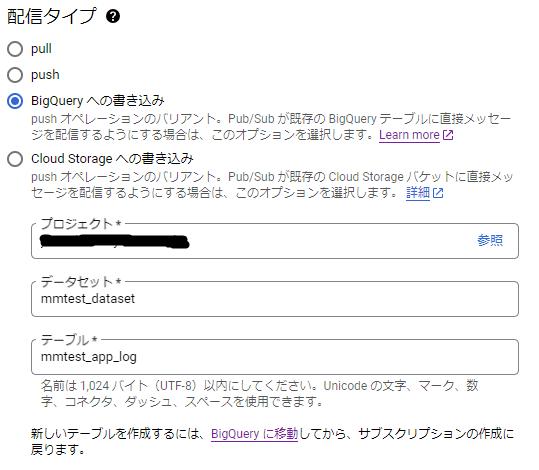
ここで、上記にて登録したBigQueryのデータセット: mmtest_dataset、テーブル: mmtest_app_logを選択しています。
Schema Optionについては、以下の図のように「テーブルスキーマを使用する」を選択します。

■準備が整ったので簡易テストをします
トピック: mmtest-topicにあるメッセージタブを確認すると、以下の図のように「メッセージをパブリッシュ」ボタンがあります。
「メッセージをパブリッシュ」ボタンをクリックすると以下の図のようにメッセージ(ログ)を送ることができるようになっています。
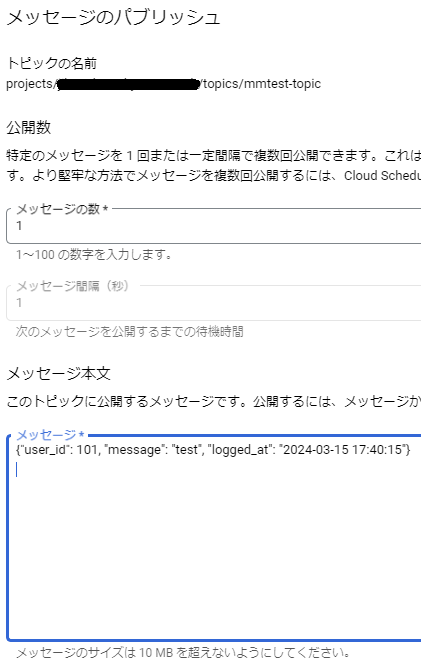
では、メッセージとして以下の内容を記入し公開します。
{"user_id": 101, "message": "test", "logged_at": "2024-03-15 17:40:15"}
■BigQueryに登録されるか確認
いつまでたっても登録されず・・・
サブスクリプションの状態を確認すると、残念ながら以下の図のように未確認メッセージが減ることがなく、成功せずに再試行が繰り返されているように思われる。

デッドレタリングで失敗の原因を確認してみます。
2. デッドレタリングで簡易テストの失敗原因確認
■デッドレタリング用テーブルの作成
デッドレタリングで登録されるデータは、テーブルにdataというフィールドを用意しておけばよいのですが、メタデータの書き込みもついでに試したいと思います。
(メタデータの書き込み内容についてはこちらを参照)
以下の構成で作成します。
- データセット: mmtest_dataset
- テーブル: mmtest_app_log_dead
- フィールド
- subscription_name: STRING
- message_id: STRING
- publish_time: TIMESTAMP
- data: STRING
- attributes: STRING
- フィールド
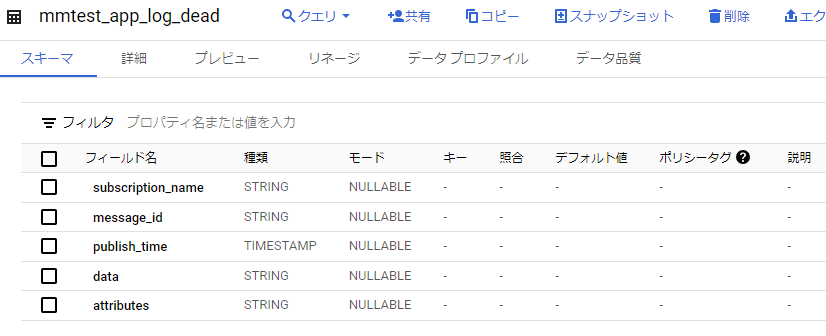
続いて、デッドレタリング用のPub/Subを作成します。
■デッドレタリング用Pub/Subの作成
以下の構成で作成します。
- トピック: mmtest-topic-dead
- サブスクリプション: mmtest-topic-dead-sub
- 配信タイプ: BigQueryへの書き込み
- Schema Option: なし、メタデータを書き込みにチェック
サブスクリプションの設定のイメージは以下のようになります。
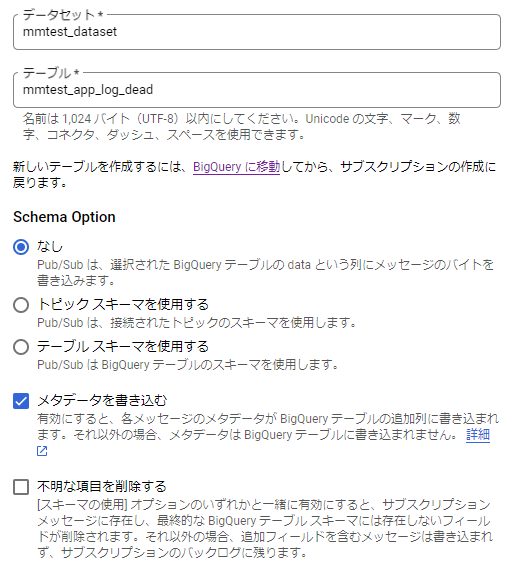
テーブルにデッドレタリング用に用意したmmtest_app_log_deadを指定して、Schema Optionは「なし」を選択し、メタデータを書き込みにチェックを入れます。
これで、デッドレタリングの準備ができたので、簡易テストに失敗したサブスクリプションを編集して、デッドレタリングの設定を行います。
■デッドレタリングの設定
以下の図のように、「デッドレタリングを有効にする」にチェックを入れ、上記にて作成したデッドレタリング用トピックを設定すればOKです。
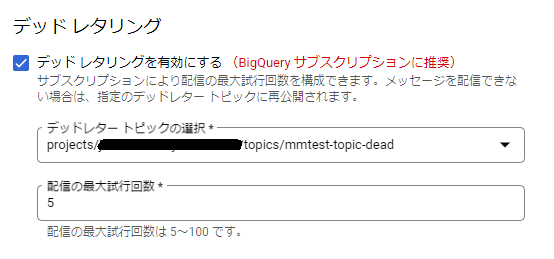
デッドレタリングの設定をすると、いくつかPub/Subのロールが足りないとワーニングがでるのでロールを付与します。
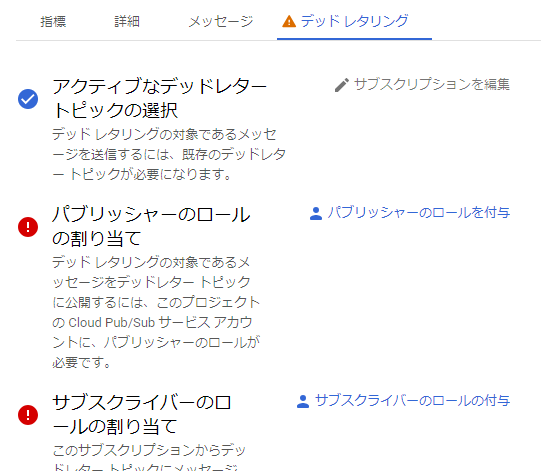
デッドレタリングの設定はこれで完了です。
では、デッドレタリング用に作成したBigQueryテーブルに登録されているか確認します。
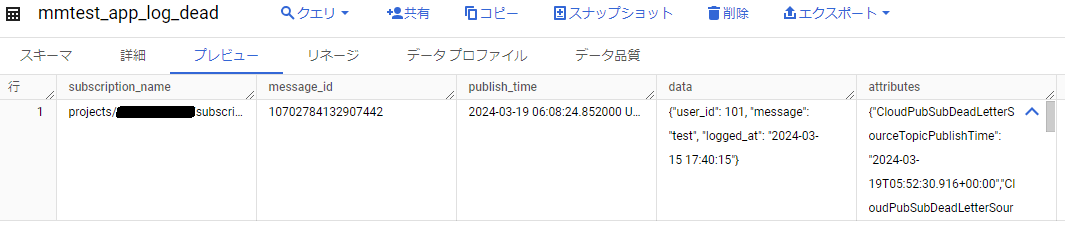
問題なく登録されました。
{"CloudPubSubDeadLetterSourceTopicPublishTime": "2024-03-19T05:52:30.916+00:00","CloudPubSubDeadLetterSourceDeliveryErrorMessage": "(logged_at): invalid value \u00222024-03-15 17:40:15\u0022 for type TYPE_INT64","CloudPubSubDeadLetterSourceSubscription": "mmtest-topic-sub","CloudPubSubDeadLetterSourceDeliveryCount": "255","CloudPubSubDeadLetterSourceSubscriptionProject": "xxxxxxxxxxxxxxxx"}
logged_atの値がおかしい。logged_atはTIMESTAMP型にしているので、”2024-03-15 17:40:15″といった日時の文字列ではダメですね。。。恥ずかしいミスをしていました。
失敗している原因が分かったので、簡易テストを再開します。
簡易テスト再開
{"user_id": 101, "message": "test", "logged_at": "2024-03-15 17:40:15"}
↓
{"user_id": 101, "message": "test", "logged_at": 1710492015}
logged_atの値を2024-03-15 17:40:15から1710492015に変えて、再度公開します。

登録された!
と思ったら、logged_atが1970-01-01 00:28:30.492015になっている。
まだ何かがおかしい。
ドキュメントを確認すると、
TIMESTAMP Unix エポックである1970 年 1 月 1 日 00:00:00 UTC からのマイクロ秒数
マイクロ秒数だった。またしても恥ずかしいミスを。
{"user_id": 101, "message": "test", "logged_at": 1710492015000000}
にして再度実行します。
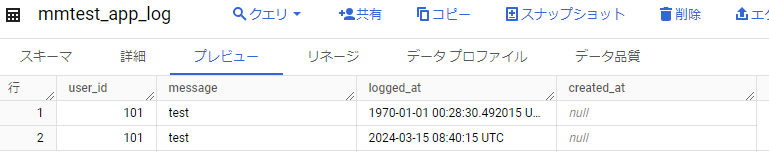
ようやく意図したlogged_atの値になりました。
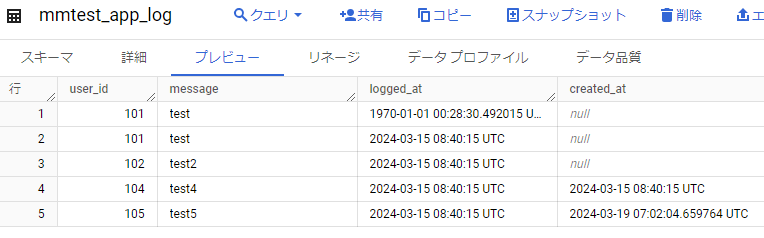
ただ、デフォルト値CURRENT_TIMESTAMP()を設定したはずのcreated_atに値が設定されていない。
明示的にcreated_atにnullを指定しないとダメなのか?
いくつかテストして確認してみます。
nullを指定する
{"user_id": 102, "message": "test2", "logged_at": 1710492015000000, "created_at": null}
⇒ nullで登録されるだけ。
“”を指定する
{"user_id": 103, "message": "test3", "logged_at": 1710492015000000, "created_at": ""}
⇒ created_atの値がおかしいと、デッドレタリング用テーブルに入る。
1710492015000000を指定する
{"user_id": 104, "message": "test4", "logged_at": 1710492015000000, "created_at": 1710492015000000}
⇒ created_atに指定した値が設定される。created_atの項目名自体が間違っているというわけではなさそう。
結果以下のように登録されました。
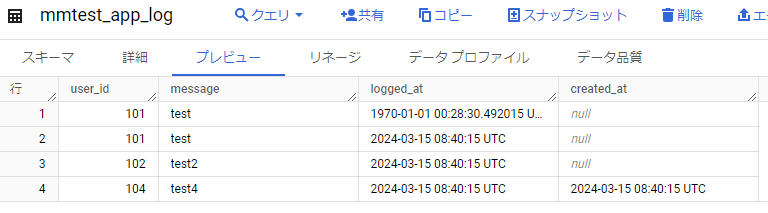
ドキュメントをしっかり読んでから試していないので、このようなミスをすることになるのですが、まず試してみたいものです。
デフォルト値が適用されるのは条件があるようです。
ドキュメントには以下のように記載がありました。
デフォルト値が適用されるのは、読み込まれたデータの列数が宛先テーブルよりも少ない場合です。
読み込まれたデータの NULL 値はデフォルト値に変換されません。
Storage Write API は、書き込みストリームに宛先テーブル スキーマにあるフィールドがない場合にのみ、デフォルト値を挿入します。
この場合、欠落フィールドには、書き込みのたびに列のデフォルト値が入力されます。
フィールドが書き込みストリーム スキーマには存在するものの、データ自体にない場合、欠落しているフィールドには NULL が入力されます。
なんと・・・
BigQueryのテーブルスキーマを利用した場合、必ずcreated_atの定義を利用した形になるので、デフォルト値を利用することはできないのでは?
よい解決方法が見つけられず、仕方なくBigQueryのテーブルスキーマを利用しないで、トピックスキーマを利用することにしました。
4. トピックスキーマの利用
■スキーマ定義の作成
以下の図のようにmmtest-schemaというスキーマを作成します。
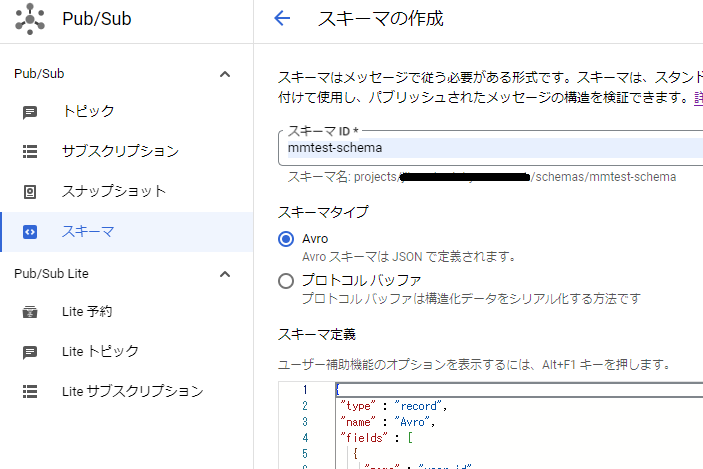
スキーマタイプにAvroを指定し、スキーマ定義には以下の内容を設定します。
{
"type" : "record",
"name" : "Avro",
"fields" : [
{
"name" : "user_id",
"type" : "int"
},
{
"name" : "message",
"type" : "string"
},
{
"name" : "logged_at",
"type" : {"logicalType": "timestamp-micros", "type": "long"}
}
]
}
■作成したスキーマを利用するようにトピック(mmtest-topic)を編集
以下の図のようにトピックを修正します。
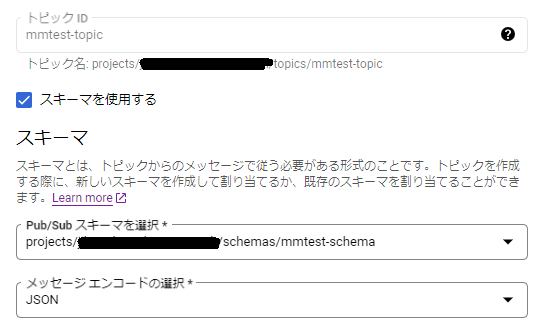
■トピックスキーマを利用するようにサブスクリプション(mmtest-topic-sub)を編集
以下の図のようにサブスクリプションを修正します。

これで、トピックスキーマを利用するようになったので、再度テストしてみます。
{"user_id": 101, "message": "test", "logged_at": 1710492015000000}
ようやくデフォルト値を使った形で登録された!
5. WEBアプリケーション(Cloud Run)からログ登録
Cloud Runについての説明はしませんが、ソースコードは以下になります。
import datetime
import random
import json
from flask import Flask
from google.cloud import pubsub_v1
app = Flask(__name__)
@app.route('/', methods=['GET'])
def publish():
publisher = pubsub_v1.PublisherClient()
topic_name = 'projects/{project_id}/topics/{topic}'.format(
project_id='xxxxxxxxxxxxxxxxxxxxx',
topic='mmtest-topic',
)
log_data = _get_log_data()
publisher.publish(topic_name, json.dumps(log_data).encode('utf-8'))
return 'OK'
def _get_log_data():
user_id = random.randint(1, 1000000)
message = f"test_{user_id}"
logged_at = int(datetime.datetime.now().timestamp() * 1_000_000)
return {
"user_id": user_id,
"message": message,
"logged_at": logged_at
}
if __name__ == "__main__":
app.run(debug=True, host="0.0.0.0", port=8080)
20行目の_get_log_dataでBigQueryに登録するアプリのログを作成、17行目のpublisher.publishにて指定したトピックにpublishしているだけのシンプルなものになっています。
23行目で*1_000_000してマイクロ秒にしています。
では、BigQueryのデータを消してから、何回かCloud Runサービスにアクセスします。
すると以下の図のように登録されることが確認できました。
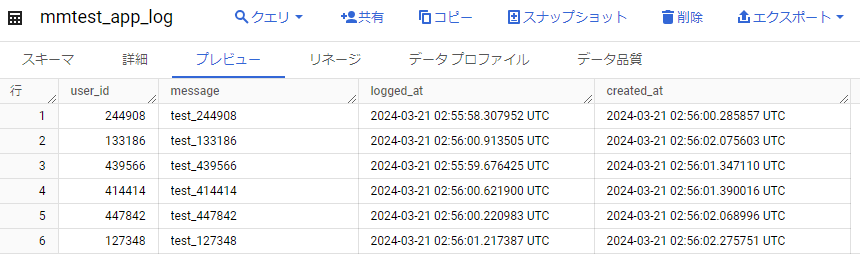
意図した形で登録されています。
logged_at, created_atを比べても、数秒レベルでBigQueryに反映されているのが分かります。
6. パフォーマンス確認
ではアクセス数が多い場合はどうなるのか、publishする処理にどれぐらい時間がかかっているのかも気になります。
以下の条件でテストをしてみようと思います。
100qpsで5分間
- 100qpsを耐えられるぐらいのCloud Runの構成にはしておく
- Cloud Runは初期3インスタンスで、何回かアクセスした状態にしておく(アプリの初期読み込みなど終わらしておく)
- CPUやworkerの数などの調整
- publish処理にどれぐらい時間がかかっているか調べるため、トレース処理を追加しておく
トレース処理を追加したソースコードは以下になります。
import datetime
import random
import json
from flask import Flask
from google.cloud import pubsub_v1
from opentelemetry import trace
from opentelemetry.exporter.cloud_trace import (
CloudTraceSpanExporter,
)
from opentelemetry.instrumentation.flask import (
FlaskInstrumentor,
)
from opentelemetry.propagate import set_global_textmap
from opentelemetry.propagators.cloud_trace_propagator import (
CloudTraceFormatPropagator,
)
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import BatchSpanProcessor
set_global_textmap(CloudTraceFormatPropagator())
tracer_provider = TracerProvider()
cloud_trace_exporter = CloudTraceSpanExporter()
tracer_provider.add_span_processor(
BatchSpanProcessor(cloud_trace_exporter)
)
trace.set_tracer_provider(tracer_provider)
tracer = trace.get_tracer(__name__)
app = Flask(__name__)
FlaskInstrumentor().instrument_app(app)
@app.route('/', methods=['GET'])
def publish():
log_data = _get_log_data()
with tracer.start_as_current_span("publish"):
publisher = pubsub_v1.PublisherClient()
topic_name = 'projects/{project_id}/topics/{topic}'.format(
project_id='xxxxxxxxxxxxxxxxxxxxx',
topic='mmtest-topic',
)
publisher.publish(topic_name, json.dumps(log_data).encode('utf-8'))
return 'OK'
def _get_log_data():
user_id = random.randint(1, 1000000)
message = f"test_{user_id}"
logged_at = int(datetime.datetime.now().timestamp() * 1_000_000)
return {
"user_id": user_id,
"message": message,
"logged_at": logged_at
}
if __name__ == "__main__":
app.run(debug=True, host="0.0.0.0", port=8080)
40行目のwith tracer.start_as_current_span(“publish”):にてpubulish処理にどれぐらい時間がかかっているかトレースするようにしています。
だいぶ前ですが、Google Traceについてブログを書いたので、必要であれば参考にしていただければと思います。
実行結果
以下はgattlingを使って100qpsを5分間実行した結果です。ここのパフォーマンスはWEBアプリケーションの内容次第なので参考までに。
================================================================================ ---- Global Information -------------------------------------------------------- > request count 30000 (OK=30000 KO=0 ) > min response time 53 (OK=53 KO=- ) > max response time 421 (OK=421 KO=- ) > mean response time 68 (OK=68 KO=- ) > std deviation 11 (OK=11 KO=- ) > response time 50th percentile 67 (OK=67 KO=- ) > response time 75th percentile 71 (OK=71 KO=- ) > response time 95th percentile 80 (OK=80 KO=- ) > response time 99th percentile 94 (OK=94 KO=- ) > mean requests/sec 99.668 (OK=99.668 KO=- ) ---- Response Time Distribution ------------------------------------------------ > t < 800 ms 30000 (100%) > 800 ms < t < 1200 ms 0 ( 0%) > t > 1200 ms 0 ( 0%) > failed 0 ( 0%) ================================================================================
問題なくBigQueryにも30000件登録されていました。
では、WEBアプリケーションが設定した日時(logged_at)とBigQueryに登録された日時(created_at)にどれぐらい差があるか確認します。
WITH latency AS ( SELECT TIMESTAMP_DIFF(created_at, logged_at, MILLISECOND) AS diff_millisecond FROM `mmtest_dataset.mmtest_app_log` ) select avg(diff_millisecond) from latency
他にも最大時間や1秒以上の件数などを調べた結果以下のようになりました。
- 平均85ミリ秒
- 最大約3秒
- 1秒以上121件
もっとリクエスト数が多い場合や、ログのサイズにもよるとは思いますが、100qps程度のWEBアプリケーションであれば、数秒程度で反映されると考えてよさそうです。
続いて設定したトレースの結果からpublish処理について確認します。
以下の図がトレースの結果になります。
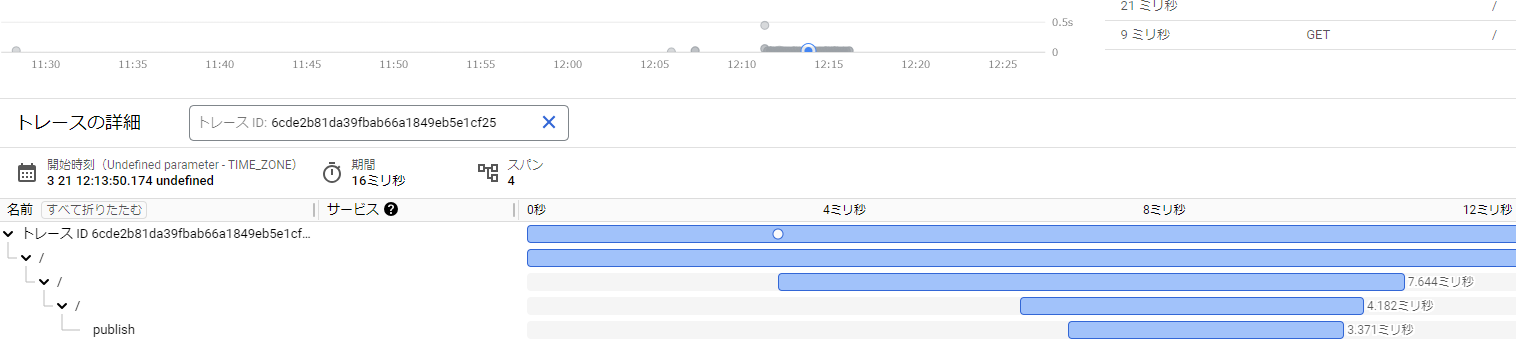
適当に選んだリクエストのトレースになりますが、3.371ミリ秒という結果になっています。
他のリクエストのトレースも確認しましたが、3~4ミリ秒程度が多く、遅いものでも10ミリ秒といったレベルでした。
- おおよそ3~4ミリ秒
- 遅いもので10ミリ秒程度
WEBアプリケーションに追加される処理時間だけでなく、WEBアプリケーションが稼働するサーバーに与える負荷などの考慮も必要だとは思いますが、ログデータをPub/SubトピックにpublishすることによるWEBアプリケーションに対する影響は少ないものと思われます。
7. まとめ
Pub/Sub BigQueryサブスクリプションを利用すれば、非同期で簡単にBigQueryにログデータを登録できることが分かりました。
ただ、実際に運用するとなると、非同期で処理している都合上、BigQueryに登録されないケースや多重で登録されるケースもでてくるかもしれません。
また、BigQueryへのStreaming Insertになるため、コスト面に対する考慮も必要になってきます。
導入は非常に簡単でしたが、ログデータの重要性やBigQueryへの登録に即時性が求められているのかなど検討した上で利用すべきだとは思います。
BigQueryへの登録に即時性が求められない場合、配信タイプをCloud Storageへの書き込みにするのが楽なのか、DataFlow(Pub/Sub Subscription to BigQuery)を使った方がいいのか、次回もう少し踏み込んで試してみたいと思います。
最後に、次世代システム研究室では、グループ全体のインテグレーションを支援してくれるアーキテクトを募集しています。アプリケーション開発の方、次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。
皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD





