2016.06.28
文系データサイエンティストが実践している機械学習の勉強法
次世代システム研究室アーキテクト兼データサイエンティストのT.Nです。
私は文系卒ながらもデータサイエンティストという役割を頂いている、いわゆる「文系データサイエンティスト」です
「文系でもデータサイエンティストにはなれる」と言われていますし、私もそうだと思っています
ただ「機械学習や統計の理論を知らなくてもいい」というわけではありません
程度の差はあれ理論学習なくてして、分析を実施することはやはり難しいかなと
しかし数学知識や理論、統計学の裏付けが無いためどうやったらいいか途方に暮れることもあるかと思います
そんな環境に直面した私が機械学習関連の理論を勉強した際の方法を記載しようかと思います
同じ悩みを抱えている方の参考にでもなれば幸いです
目的
私と同じように文系卒でデータサイエンティスト職に就いている方、もしくはこれから機械学習関連の勉強をしていこうとしている方に対して
- 私の勉強法を共有して、何らかの助けになればよい
- 同じような境遇の方も勉強法を共有してもらえば嬉しい
という思いで書いています
勉強方法
初めは統計の基礎として数学や統計検定2級、その他理論系の本を勉強してましたが、
- 「全体を考えるとどのくらい勉強が進んだの?」
- 「これ勉強して何の役に立つの分からない」
と思ってしまい、かなりストレスフルな思いをするようになりました
そのためある時点で勉強方法を以下のように変えてみました
新たな指針
「何の役に?」「どれくらい?」という思いを解消するために下記の指針を設けました
- 「どれくらい?」 => 書籍・資料を元に役立ちそうな理論を選定し、まずそれを全体として考える
- 「何の役に?」 => 理論学習の前にPythonを使って実装し、どういった結果が得られるのか勘所を得る
まず全体量を定義して、自分の進捗が定量的に測れること
そしてプログラムを組むことによって問題となっている事象を解決しようと考えたのです
以下にどうやって勉強したか具体的な内容を記載します
テーマ設定
まずテーマとして「書籍・資料を元に役立ちそうな理論を選定」し、これを一つずつ勉強するようにしました
これは何らかの裏付けと納得感があれば、どれでもいいのかなと考えています
例えば古いものですがTop 10 Algorithmsあたりでも良い指針になるかなと
以下にTop 10 Algorithmsで取り上げられているものを記載します
クラスタリングが若干多めですが、基礎理論の勉強としては違和感はないのかなあと思っています
(できれば初歩として単回帰分析と、モダンな理論としてCNN/RNNあたり追加してもいいかなとは思いますが)
[table id=14 /]
ここで定義した理論の中から一つずつ抜き出し、これを勉強していきます
学習の流れ
次に「理論学習の前にPythonを使って実装」してどう役立つかをしっかり把握した上で、理論学習を進めていきました
ここでは最も単純な単回帰分析を選んだものとして話をすすめていきます
1. まずはコード実装
単純なものでいいので、まずはPython(scikit-learn)で実装してみます
この際、scikit-learnのドキュメントを読み、使われる引数はしっかり把握します
from sklearn import linear_model
from sklearn import ensemble
import pandas as pd
import numpy as np
# 性別、身長、体重をInputにする
x = pd.read_csv("data.csv", sep=",")
# 身長、体重を入力し、性別を判定するよう学習させる
# DataFrameで扱えないのでndarray型に変更
train = x[["Height","Weight"]].as_matrix()
result = x["Gender"].as_matrix()
clf = linear_model.LinearRegression()
print clf
clf.fit(train, result)
prediction=clf.predict([1,175])
print prediction
2. 理論学習
1. で何が出来るか、どういったInputデータ・パラメータがあるか、何が出来るかを把握した上で理論学習を深めます
その際なるべく平易な本・サイトを選ぶのですが、ここではCourseraのMachine LearningコースのLinear Regression w/ One Variablesを受講したとしましょう
ここでは一般的な線形回帰のやり方である
![]()
とモデルを構築し、
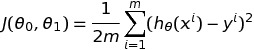
とCost Functionを定義した上で、勾配降下法を使って学習することが学べます
Input, Outputのイメージがついている分、学習もスムーズにいけました
3. ソースと理論をつなげる
ここまで実装方法と理論を学べたので、後はそれを繋げて考えてみます
ここでスムーズにつながればいいのですが、今回については以下の”ずれ”があることに気づきます
- 講義ではlearning rateが必須だと言っていた
- しかしソースコードやAPIを見てもlearning rateというパラメータは存在しない
こういった”ずれ”には必ず原因があります
これを調査すると以下の理由によりずれが発生していることが判明します
- LinearRegressionはOLS(最小2乗回帰)・正規方程式で解いているようであり、講義の内容とは違いそう
- 勾配降下法(SGD)を使って回帰するクラスはSGDRegressorである
- 正規方程式はfeature数が少ない場合には、パラメータ調整もいらず速度も早い
- ただしfeature数が多い場合はメモリを大量に使用するため、SGDRegressorを使ったほうがよさそう
- 現実の線形回帰ではそこまでfeature数が多い場合はなく、LinearRegressionで充分ではないか
等などここで検証をすることによって、理解が深まり、且つソースと理論の紐付けが進みます
最後に
機械学習には、例えば過学習が…とか次元の呪いが…のように大事な基礎理論があったりもします
ただやはり「何に使えるのか?」「どう使うのか?」が分からないと精神的にはつらいものがあったりします
そのため上記のようなソースコード駆動型勉強法も良いのでは?と感じています(もちろん基礎理論は後で勉強しなければいけないですが)
こうやって勉強を続けてきた結果、数式ばかりの解説書や論文にも取り組めるようになりましたし、初めの一歩としては効果のあるやり方ではないのかなと感じています
是非同じ悩みを抱えている方は参考にしていただければと思います
次世代システム研究室では、アプリケーション開発や設計を行うアーキテクトを募集しています。アプリケーション開発者の方、次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。
皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD