2016.07.07
Safely Reconfiguring RethinkDB
For intermediate level users
We recently started working with the impressive RethinkDB KVS no-sql database. This article describes safely reconfiguring RethinkDB. The target reader has a basic knowledge of RethinkDB JSON DB: https://www.rethinkdb.com/
Environment
The environment used for this article was 3 Centos 7.2 servers running as Vagrant guests on an OS X El Capitan MacBook Pro with 8GB RAM. The IPs of each Centos server as configured in Vagrantfile is 192.168.15.10, 192.168.15.11, 192.168.15.12.
RethinkDB version 2.3.4 was installed from source on the 3 Centos servers as detailed here: http://rethinkdb.com/docs/install/centos/.
All three RethinkDB server instances were instructed to join the first instance in /etc/rethinkdb/instances.d/default.conf
join=192.168.15.10:29015
RethinkDB 2.3.4 was installed on the MacBook as described here: http://rethinkdb.com/docs/install/osx/ in Using the installer
All testing was done through a RethinkDB proxy running on the MacBook, started by the following command:
rethinkdb proxy --join 192.168.15.10:29015 --join 192.168.15.11:29015 --join 192.168.15.12:29015 --bind all --http-port 7777
This starts a proxy on our Mac which joins our RethinkDB servers and which provides a RethinkDB web interface on http://localhost:7777
All DB testing was done with node.js connecting to this proxy. Node version v5.1.0 is installed on the Mac host computer.
Maintain write-ability during reconfigure operations
As shown below RethinkDB allows for easy configuring of table shards and table replica settings.
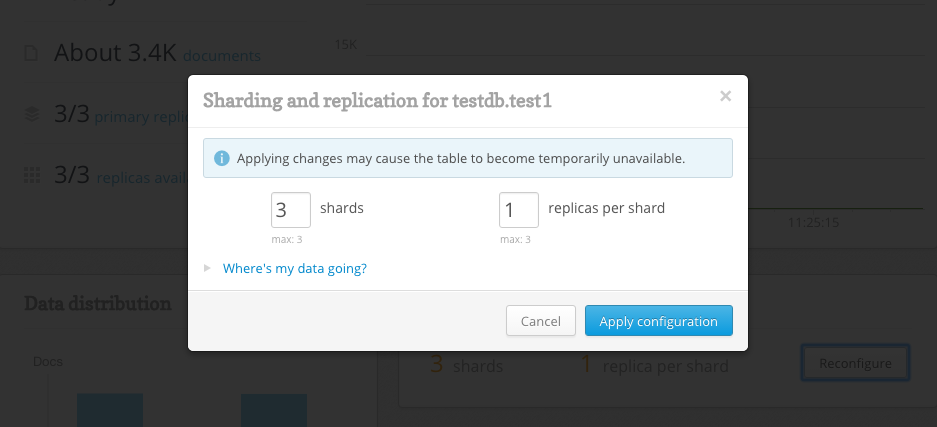
However, naively reconfiguring during write operations will probably result in errors and subsequent data loss.
If you have code that inserts into the database, you should be aware of the possible errors caused by reconfiguring while inserts are taking place. An example error is provided below:
Unhandled rejection ReqlOpFailedError: Cannot perform write: primary replica for shard ["Nc0b5\x1A\x1E\x9B", +inf) not available in:
r.table("test1").insert({"id": 9065, "log": []})
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
at ReqlOpFailedError.ReqlError [as constructor] (/Users/nick/projects/rethinkdb_testing/node_modules/rethinkdb/errors.js:23:13)
at ReqlOpFailedError.ReqlRuntimeError [as constructor] (/Users/nick/projects/rethinkdb_testing/node_modules/rethinkdb/errors.js:90:51)
...
The solution is to use the RethinkDB wait command. The rest of this article describes the use of wait and it’s effect.
Below is an example with the wait command before the insert command:
yield r.table('test1').wait({timeout: waitTime}).run(connection);
var insertP = yield r.table('test1').insert(test1Data).run(connection);
We wait waitTime before executing the insert. RethinkDB’s run method returns a Promise which we then call yield on. We use the co module to allow us to write code that executes in order from top to bottom. The yield command can be used inside the co invocation and has the effect of delaying subsequent execution of this code until the run has finished. In this way we have created procedural style code where we wait until the database is ready and then perform the write. It should be noted that using yield with the co module is not part of the solution, but is simply a way of controlling the execution flow of the test. So we get a wait then an insert per iteration of the outer loop. If we don’t use the co-yield pattern we get all the waits then all the inserts and so on.
Promises and yields are explained more fully here: http://tobyho.com/2015/12/27/promise-based-coroutines-nodejs/, while the co module is described here: https://github.com/tj/co. The wait function defaults to wait for ‘all_replicas_ready’, so the code below would be equivalent.
yield r.table('test1').wait({timeout: waitTime, waitFor: 'all_replicas_ready'}).run(connection);
var insertP = yield r.table('test1').insert(test1Data).run(connection);
If the table is unable to get to ‘all_replicas_ready’ before out waitFor time, the promise returned by the run function is rejected. If we were handling this as a Promise rather than with yield we could handle success and errors with the Promise.then() and Promise.catch() functions as below:
r.table('test1').wait({timeout: waitTime, waitFor: 'all_replicas_ready'}).run(connection)
.then(function(res) {
// Having successfully waited do the insert
r.table('test1').insert(test1Data).run(connection);
})
.catch(function(res) {
// We have an error, probably a timeout, handle the error
})
But with yield, we just catch any errors in the calling code as shown below:
try {
yield insert(connection, i);
} catch (err) {
console.error(err.message);
}
When we get a timeout, this results in the following output:
Timed out while waiting for tables in:
r.table("test1").wait({"timeout": 10})
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
In this case the timeout value was 10 seconds.
The complete code is shown below:
var co = require('co'),
r = require('rethinkdb');
var waitTime = 10;
var test1Inserted = 0;
var insert = co.wrap(function* (connection, seqNum) {
var test1Data = {seqNum:seqNum, log:[]};
yield r.table('test1').wait({timeout: waitTime}).run(connection);
var insertP = yield r.table('test1').insert(test1Data).run(connection);
test1Inserted = test1Inserted + insertP.inserted;
process.stdout.write('test1 inserted:' + test1Inserted + '\r');
var test2Data = {seqNum: seqNum, confirmedPoint: {timestamp: r.now()}};
yield r.table('test2').wait({timeout: waitTime}).run(connection);
yield r.table('test2').insert(test2Data).run(connection);
});
var connection = null;
r.connect( {host: 'localhost', port: 28015, db: 'testdb'}, function(err, conn) {
if (err) throw err;
connection = conn;
co(function* () {
for (var i = 0; i<100000; i++) {
try {
yield insert(connection, i);
} catch (err) {
console.error(err.message);
}
}
});
});
As can be seen it requires the co and rethinkdb libraries. These should be included into the same directory as the test program by doing
npm install rethinkdb co
The program iterates 100,000 times doing 2 inserts into 2 separate tables on each iteration. You may want to loop less to test this. While iterating manually reconfigure the test1 or test2 tables and observe the results.
My Observed Behaviour
Starting off with a few 10,000 documents, time for a reconfigure as between 2 and 3 seconds.
As the documents stored increased timeouts began to occur. Which for a timeout value of 10 seconds indicated that the target table was unavailable for writes for more than 10 seconds.
The time taken for a reconfigure from 2 shards, 2 replicas to 3 shards, 3 replicas at about 270K documents was more than 30 seconds. The image below shows the table overview for this time:
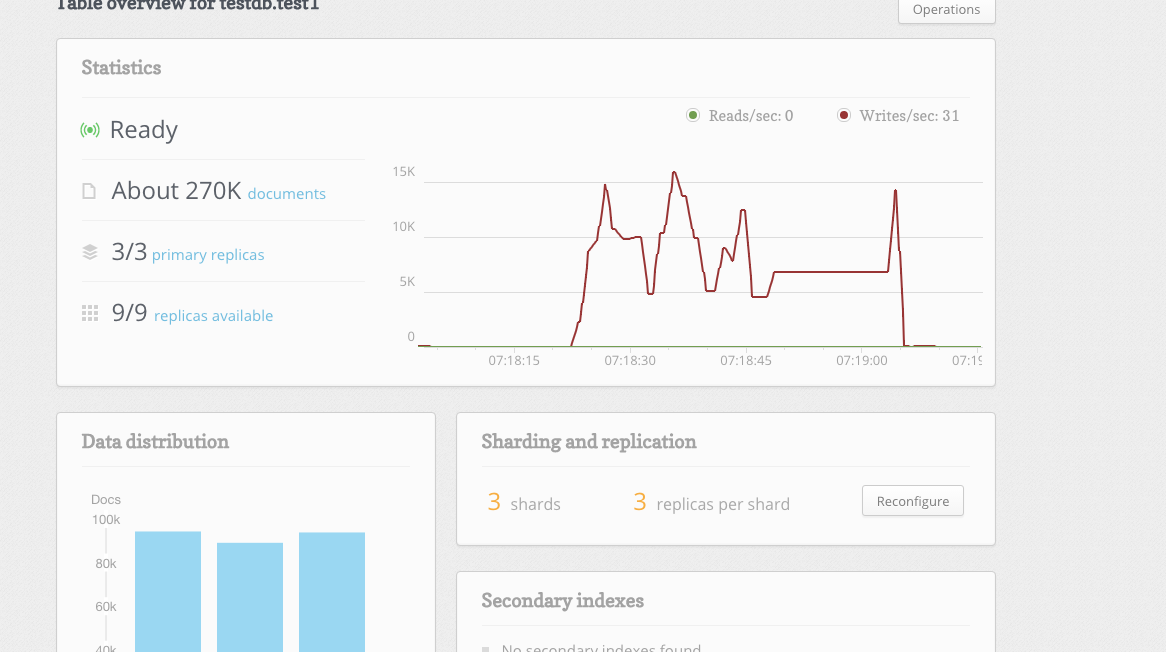
And below we see the output from our program indicating 3 timeouts:
test1 inserted:85352
Timed out while waiting for tables in:
r.table(“test1”).wait({“timeout”: 10})
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
Timed out while waiting for tables in:
r.table(“test1”).wait({“timeout”: 10})
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
Timed out while waiting for tables in:
r.table(“test1”).wait({“timeout”: 10})
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
test1 inserted:99997
Summary
This testing was all done on 3 VMs running on my MacBook, so all we can say is that: as data increases so too does the time required for reconfigure operations. The strength of this correlation may differ on depending on the computing environment. This should be taken into account when estimating the wait timeout value. You may want to run the test in an environment closer to production conditions to estimate the correct timeout value.
Links:
- RethinkDB: https://www.rethinkdb.com/
- Node.js: https://nodejs.org/en/
- install RethinkDB on Centos: http://rethinkdb.com/docs/install/centos/
- install RethinkDB on Mac OSX: http://rethinkdb.com/docs/install/osx/
- RethinkDB wait function: https://rethinkdb.com/api/javascript/wait/
- Promise-Based Coroutines in Node.js: http://tobyho.com/2015/12/27/promise-based-coroutines-nodejs/
- generator based flow-control goodness for Node.js: https://github.com/tj/co
次世代システム研究室では、アプリケーション開発や設計を行うアーキテクトを募集しています。アプリケーション開発者の方、次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧からご応募をお願いします。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD




