ML Pipeline事始め – kedro(+notebook)とMLflow Trackingで始めるpipeline入門 –
こんにちは。次世代システム研究室のT.S.です
AI/機械学習が不可欠となった昨今、数多くの方がKaggleなどの分析コンペ参加から機械学習モデルの実験、そして本番環境への適用まで色々実施してらっしゃると思います。
私もその一員で、日々モデルの実験から本番機械学習基盤の構築まで色々な分野の機械学習関連業務に従事しております。
そうした中で(皆様も同じ悩みを抱えているかと思いますが)実験->本番適用->運用に渡って、色々な悩みを抱えています。
一例ですが、こん悩みがあります
- 実験を複数回繰り返した結果、実行結果とハイパパラメータの組み合わせがゴチャゴチャになる
- 実験時の処理がモジュール化していないため、処理順序の入れ替えや追加が困難
- 実験時コードが複雑化しており、整理して本番用コードに実装しなおすのに工数がかかる 等々
このような悩みを解消する概念として注目されているワードとして「MLOps」があります。
ただこのMLOpsという単語は非常に広大であり、いきなりすべての要素を組み入れようとしても、なかなかな骨が折れる結果となってしまいます
そこで当記事では、「まず一人でできる改善を!」を目指し、kedroとMLflow Trackingを組み合わせて、簡素なML Pipeline構築と実験管理のやり方をご紹介したいと思います
kedroを使ったNotebook + ML Pipeline
kedroはマッキンゼー・アンド・カンパニー傘下のデータ解析企業QuantumBlackが開発したML Pipeline OSSです。
コンパクトかつ痒いところに手が届く機能がになっており、今回のように「まず一人で」を実現するには最適なソフトウェアの一つです。
今回はkedroで自動生成されるexampleを元に、notebookでの実験からモジュール化までを解説したいと思います。
環境準備
kedroはpythonライブラリであるため、pip installを実行します
pip install kedro
install後はkedroコマンドが利用できますので、以下のコマンドを使い新規kedroプロジェクトを作成しましょう
kedro new
実行すると以下のメッセージが出力されます。
今回はirisデータセットを使ったプロジェクトであるため、Projcet Nameを[iris]としています。
この際[Repository Name][Python Package Name]は特にこだわりがなければ、そのままEnter押下してください。
また[Generate Example Pipeline]でYを押下すると、今回利用するExampleの雛形が生成されるので、こちらも必要に応じて選択してください
Project Name:
=============
Please enter a human readable name for your new project.
Spaces and punctuation are allowed.
[New Kedro Project]: iris
Repository Name:
================
Please enter a directory name for your new project repository.
Alphanumeric characters, hyphens and underscores are allowed.
Lowercase is recommended.
[iris]:
Python Package Name:
====================
Please enter a valid Python package name for your project package.
Alphanumeric characters and underscores are allowed.
Lowercase is recommended. Package name must start with a letter or underscore.
[iris]:
Generate Example Pipeline:
==========================
Do you want to generate an example pipeline in your project?
Good for first-time users. (default=N)
[y/N]: Y
これでCurrent Dictory配下にkedroプロジェクトが作成されているかと思います。
Input/Outputデータ定義
さてプロジェクトの雛形ができたので、次はInputデータを定義しましょう。
kedroではデータ定義をData Catlog(conf/base/catalog.yml)と呼ばれるyamlファイルに定義しています。
今回はirisのCSVファイルをインプットとして利用しますが、この場合は以下の通りとなります。
example_iris_data:
type: pandas.CSVDataSet
filepath: data/01_raw/iris.csv
[example_iris_data]がDataset Nameとなり、プログラム内ではこの名称で利用することになります。
[type]にはCSVを表すpandas.CSVDataSetを、またファイルパスには該当CSVが格納されているファイルパスを記載します。
今回はCSVをInputとするだけであるため、以上のようなシンプルな形式でしたが、Data Catalogは他にも多様なInput/Output形式が利用できます。
例えば
例1. Parquetファイルでhive用にデータ出力
trucks:
type: pandas.ParquetDataSet
filepath: data/02_intermediate/trucks.parquet
save_args:
compression: GZIP
file_scheme: hive
has_nulls: False
partition_on: [name]
例2. Pytorchの学習済みモデルをGoogle Cloud Storageに格納(+Versioning)
model: type: pickle.PickleDataSet filepath: gcs://train_model/model.pkl backend: pickle versioned: true
例3. APIからデータ取得
us_corn_yield_data:
type: api.APIDataSet
url: https://quickstats.nass.usda.gov
params:
key: SOME_TOKEN
format: JSON
commodity_desc: CORN
statisticcat_des: YIELD
agg_level_desc: STATE
year: 2000
この他にも色々な機能がありますが、詳しくはぜひ公式ドキュメントを御覧ください。
notebookを使った実験
Inputデータの準備も終わりましたので、通常通りJupyter notebookで実験を開始しましょう。
次のコマンドを実行し、kedroに最適化されたjupyter notebookを起動します
kedro jupyter notebook
見慣れたJupyter notebookの画面が表示されたかと思いますので、[Project root]/notebooks配下にnotebookファイルを作成してください。
なおこの際、以下のような基準でフォルダを分けることが多くみられますが、今回は事始めですし、簡単のため一つのnotebookで実施します。
慣れた際にはぜひ機能ごとの分割を検討してください
- notebooks/data_engineering -> 欠損補完、特徴量生成などの前処理及びデータ分割(train/test/val)
- notebooks/data_science -> モデル構築、学習実行、評価
さてこれでnotebookを利用した実験が可能になったのですが、kedroを利用するのあたって数点気をつけなければいけません。
まず最初はkedroの中核となるcontextのloadを実施することです。
これは決り文句として以下のコードを実行すれば問題有りません。
from pathlib import Path from kedro.framework.context import load_context current_dir = Path.cwd() proj_path = current_dir.parent context = load_context(proj_path)
次にInputデータの取得です。
これは先程作成したDataCatalog経由で取得することになります。
catalog#load関数の引数に、DataCatalogで定義したDataset Nameを指定することになります。
※これだけだと特にメリットを感じませんが、API呼び出しやSQL経由でのデータ取得などもすべてこの関数から取得できるため非常に便利です
df = catalog.load("example_iris_data")
さてここまで来れば、あとは各処理を実装するだけなのですが、ここでも一点注意を。
各処理は必ず関数化するよう実装してください。
Pipelineというのはモジュール化した処理の流れを組み合わせるもののため、関数化していないとそれが実現できないためです。
この点は通常の実験と比較すると若干手間がかかりますが、今後のためにぜひひと手間ください。
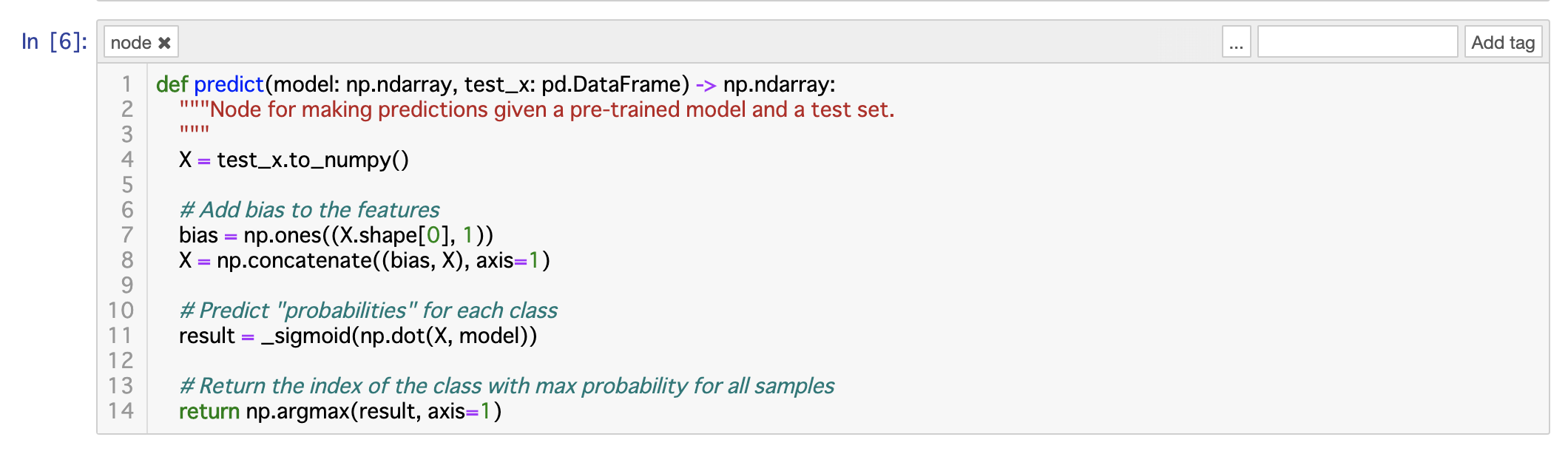
今回はkedro Exampleのコードをそのままnotebookにコピーしています
例:predict関数
またこの際各関数にはタグを付ける必要があります。
このタグがついていることにより、後続で出てくるnotebook convertの際に該当関数が出力対象となります。
notebookのメニューバーから[View]->[Cell Toolbar]->[Tag]を選択して
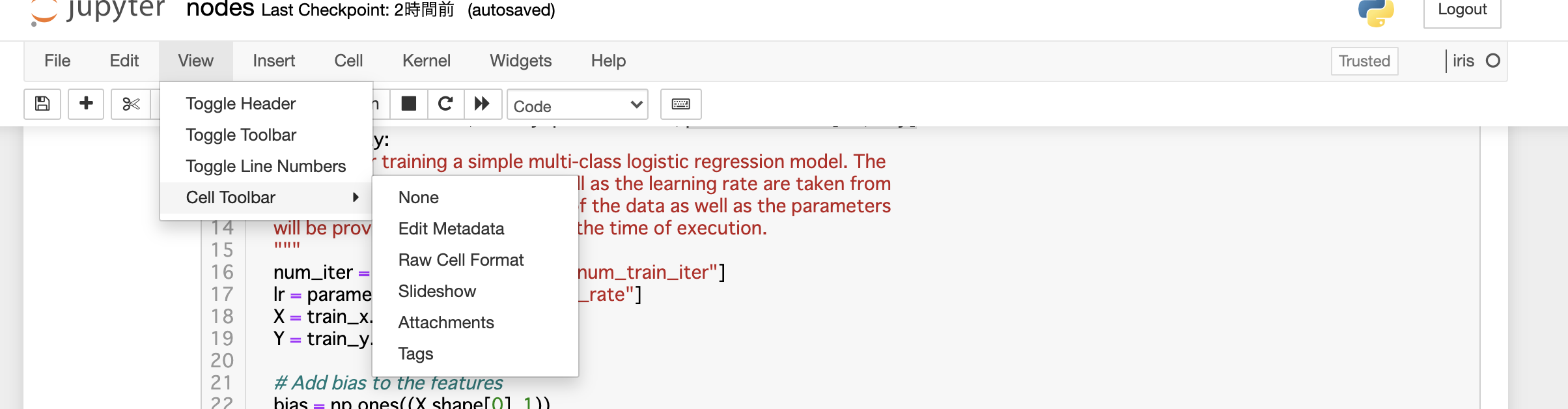
各セルでnodeというタグを追加すれば完了です

後は下記のように各関数を呼び出していけば完了です。
df = catalog.load("example_iris_data")
df = drop_missing_value(df)
df_dict = split_data(df, context.params['example_test_data_ratio'])
model = train_model(df_dict['train_x'], df_dict['train_y'], context.params)
predict = predict(model, df_dict['test_x'])
report_accuracy(predict, df_dict['test_y'], context.params)
MLflow Trackingによる実験結果管理
さて上記で機械学習アルゴリズムは動作するようになりましたが、このままだと各実験ごとの結果やパラメータは記録されません。
そのため今回はMLflow Trackingを利用して、これを管理していきたいと思います。
MLflowは機械学習ライフサイクルを管理するためのOSSです。
4つのコンポーネント(Tracking/Models/Projects/Regsitry)に分かれており、今回はそのうち実験管理ができるTrackingのみを利用します。
まずlibraryをinstallするためにsrc/requirements.txtを編集します
black==v19.10b0 flake8>=3.7.9, <4.0 ipython>=7.0.0, <8.0 isort>=4.3.21, <5.0 jupyter>=1.0.0, <2.0 jupyter_client>=5.1.0, <6.0 jupyterlab==0.31.1 kedro[pandas.CSVDataSet]==0.16.1 nbstripout==0.3.3 pytest-cov>=2.5, <3.0 pytest-mock>=1.7.1,<2.0 pytest>=3.4, <4.0 wheel==0.32.2 mlflow==1.4.0 #追加
requirementsを反映するためにinstallを実行します
kedro install
これで準備は完了です。
あとは記録したい内容をmlflow内の関数で記録していきます。
Mlflowの記録内容はDBMSなどで保存することも多いですが、今回は事始めということもあり、外部媒体は指定していません。
この場合はローカルのnotebooks/mlruns配下に記録結果が記録されていきます。
個人で利用する程度であればこれでも充分ですね。
def report_accuracy(predictions: np.ndarray, test_y: pd.DataFrame, parameters: Dict[str, Any]) -> None:
"""Node for reporting the accuracy of the predictions performed by the
previous node. Notice that this function has no outputs, except logging.
"""
# Get true class index
target = np.argmax(test_y.to_numpy(), axis=1)
# Calculate accuracy of predictions
accuracy = np.sum(predictions == target) / target.shape[0]
# Log the accuracy of the model
log = logging.getLogger(__name__)
#########################################
### MLflow Tracking追加部分
mlflow.log_metric("accuracy", accuracy)
mlflow.log_param("time of prediction", str(datetime.now()))
mlflow.log_param("example_test_data_ratio", parameters['example_test_data_ratio'])
mlflow.log_param("example_num_train_iter", parameters['example_num_train_iter'])
mlflow.log_param("example_learning_rate", parameters['example_learning_rate'])
#########################################
log.info("Model accuracy on test set: %0.2f%%", accuracy * 100)
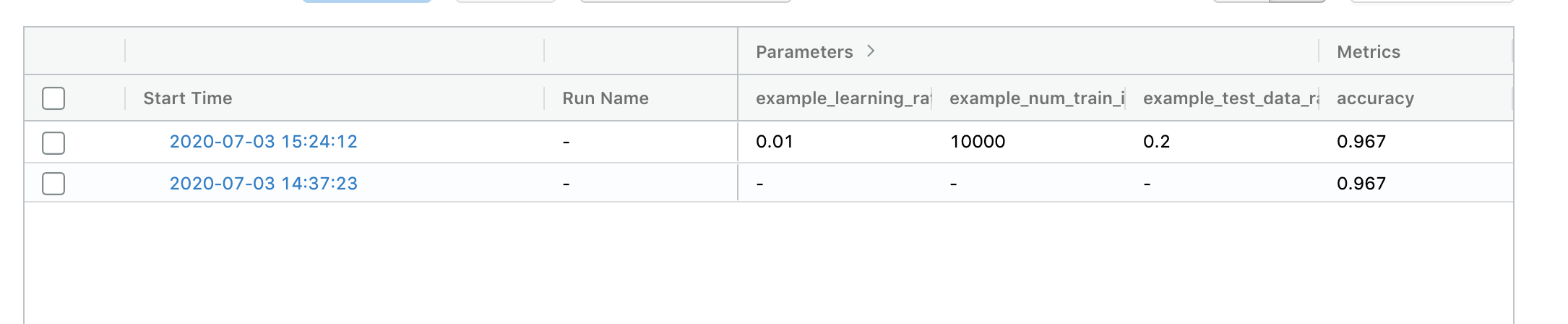
記録した内容は以下のコマンドを実行すればweb画面で参照可能です。
cd ../notebooks mlflow ui
内容はこのようになり、Input Parameterと、これに紐づく結果がわかりやすく表示されています。
mlflow.log_artifact関数を利用すると、pickleファイルなども合わせて記録できるため、最も良いモデルとパラメータの抽出が実験管理が非常に楽になります。
・
notebookからpythonモジュール化
さてこれまでの手順を踏まえれば、kedro+notebook+Mlflow Trackingを使った実験ができるようになったかと思います。
さあ実験が終わったの慣ればこれをモジュール化し、実行できる形にしましょう。
通常であればnotebookの内容を元にpythonモジュール化すると思いますが、notebook自体が関数化されているためこれをそのまま利用してしまいましょう!
kedroにはnotebookをpythonモジュールに変換する仕組みが用意されています。
以下のコマンドを実行すると、src/[project name]/nodes/nodes.pyに関数が出力されいることがわかるかと思います。
kedro jupyter convert --all
ただ一つ注意しなければいけないのが、ここで出力されるのは関数だけであり、pipeline定義は別途実施しなければいけません。
ここがちょっと面倒ではあるのですが、src/[project name]/pipeline.pyに実行ワークフローを定義しましょう
pipeline例:
def create_pipelines(**kwargs) -> Dict[str, Pipeline]:
pe = Pipeline(
[
node(
split_data,
["example_iris_data", "params:example_test_data_ratio"],
dict(
train_x="example_train_x",
train_y="example_train_y",
test_x="example_test_x",
test_y="example_test_y",
),
),
node(
train_model,
["example_train_x", "example_train_y", "parameters"],
"example_model",
),
node(
predict,
dict(model="example_model", test_x="example_test_x"),
"example_predictions",
),
node(report_accuracy, ["example_predictions", "example_test_y"], None),
]
)
return {
"__default__": pe
}
以上でkedro+notebook+MLflow Trackingを使った実験が完了となります。
やや面倒な点もあったものの、実験と本番コードの乖離や実験結果の不明瞭さが解決することなります。
実際にこれをで実装してみるとソースが簡素化されて、非常に見通しの良い実験となります。
おまけ:nvidia Dockerを利用したkedro実行方法
機会学習アルゴリズムである以上、kedroで構築したML Pipelineをなんらかの機械学習基盤で動作したいこともあるかと思います。
その場合の一つの解決策としてnvidia dockerで実行する場合のdockerfile例を以下に記載したいと思います。
GCP AI Platformなどnvidia dockerで動作するクラウドサービスを利用する場合にはぜひ参考ください
FROM nvidia/cuda:9.0-cudnn7-runtime
RUN apt-get update && apt-get install -y tzdata
RUN apt-get update && apt-get install -y \
wget \
curl \
make \
git \
build-essential \
libssl-dev \
zlib1g-dev \
libbz2-dev \
libreadline-dev \
libsqlite3-dev \
llvm \
libncurses5-dev \
libncursesw5-dev \
xz-utils \
tk-dev \
libffi-dev \
liblzma-dev \
file \
sudo \
mecab \
libmecab-dev \
mecab-ipadic-utf8
WORKDIR /root/
RUN wget https://www.python.org/ftp/python/3.7.0/Python-3.7.0.tar.xz \
&& tar xvf Python-3.7.0.tar.xz \
&& cd Python-3.7.0 \
&& ./configure --enable-optimizations \
&& make altinstall
RUN rm Python-3.7.0.tar.xz
WORKDIR /root/Python-3.7.0
RUN ln -fs /root/Python-3.7.0/python /usr/bin/python
RUN curl -kL https://bootstrap.pypa.io/get-pip.py | python
ENV PATH /env/bin:$PATH
# 例題に上げたAI platformを利用する場合には必要
# RUN wget -nv \
# https://dl.google.com/dl/cloudsdk/release/google-cloud-sdk.tar.gz && \
# mkdir /root/tools && \
# tar xvzf google-cloud-sdk.tar.gz -C /root/tools && \
# rm google-cloud-sdk.tar.gz && \
# /root/tools/google-cloud-sdk/install.sh --usage-reporting=false \
# --path-update=false --bash-completion=false \
# --disable-installation-options && \
# rm -rf /root/.config/* && \
# ln -s /root/.config /config && \
#
# rm -rf /root/tools/google-cloud-sdk/.install/.backup
#
# ENV PATH $PATH:/root/tools/google-cloud-sdk/bin
#
# RUN echo '[GoogleCompute]\nservice_account = default' > /etc/boto.cfg
RUN mkdir /root/kedro
COPY ./[project name] /root/kedro/[project name]
WORKDIR /root/kedro/[project name]
RUN pip install kedro
RUN kedro install
ENTRYPOINT ["kedro","run"]
次世システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧からご応募をお願いします。
一緒に勉強しながら楽しく働きたい方のご応募をお待ちしております。