Revisiting iALS
~最新の機械学習モデルにも匹敵する定番の推薦アルゴリズムの真の性能~
はじめに
こんにちは、グループ研究開発本部・AI研究室の T.I. です。今回の Blog では、先日の RecSys ’22 に Google の研究チームから発表された推薦システムに関する論文 Revisiting the Performance of iALS on item Recommendation Benchmarks について簡単に紹介をしたいと思います。概要
- iALS(implicit feedback alternative least square)は、推薦システムで昔から利用されている定番の機械学習モデルであり、最新の深層学習モデルとの性能比較のベンチマークとして比較されることが多い。
- しかし、この論文の著者らは iALS であってもパラメータを適切にチューニングすれば、最新の深層学習モデルと十分に匹敵する性能を発揮することを示した。
モデルの紹介
iALS
implicit feedback Alternative Least Square (iALS) については、以前の Blog でも紹介したので、簡単に復習します。(なお、今回、紹介する論文の著者でもある Steffen Rendle 氏のレビューが端的にまとまっており参考になります。)推奨モデルでは、 ユーザー \( u \in U \), アイテム \( i \in I\) のペアに対して何らかのフィードバック(評価) \( S \subseteq U \times I\)がえられた状況で、未知の観測されていない組み合わせ \( (u, i) \in (U\times I) \setminus S\) のフィードバックを予測する問題として定式化されます。
$$\hat{y}: U \times I \rightarrow R$$
iALS では、上記の予測を \(d\)-dimensional embedding vector \( w_u \in \mathrm{R}^d \), \( h_i \in \mathrm{R}^d \) の内積として予測します。
$$\hat{y}(u, i) := \langle w_u, h_i \rangle$$
ここで、ユーザー行列とアイテム行列は、それぞれの要素数 x 埋め込み次元(\(d\))の行列です。
$$W \in \mathrm{R}^{U\times d}, H \in R^{I \times d}$$
iALS の損失関数は、これらの行列と各種正則化パラメータを使って以下にまとめることができます。
$$L(W, H) = L_S(W, H) + L_I(W, H) + R(W, H)$$
$$L_S(W, S) = \sum_{(u,i) \in S}(\hat{y}(u,i)-1)^2$$
$$L_I(W,H) = \alpha_0 \sum_{u \in U} \sum_{i \in I} \hat{y}(u,i)^2$$
$$R(W,H) = \lambda \left(\sum_{u \in U}\#_u^\nu ||w_u||^2 + \sum_{i \in I}\#_i^\nu ||h_i||^2 \right)$$
ここで \(\nu\) はパラメータで、それが掛かる係数の定義は以下の通りです \(\#_u = |\{i : (u, i) \in S \}| + \alpha_0|I|\), \(\#_i = |\{u : (u, i) \in S \}| + \alpha_0|U|\).
iALSの性能は、これらの項のバランスできまります。iALSでは、この第3項がオリジナルから変更されており、出現頻度の多いものほど強く正則化がされるように工夫されております(詳細については、日本語での記事としては、以下の Blog で詳しく解説されています。iALSによる行列分解の知られざる真の実力)。Alternative Least Square の名前の由来は、この \( W \) と \( H \) を交互に更新することで効率的に損失関数を最小化できることに因んでいます。計算の詳細については、以前の Blog にもまとめてありますので、割愛します。iALSの利点として計算コストが少なく容易にスケールアウトできることが知られています。改良された方法を利用すれば\( \mathcal{O}(d|S| + d^2(|U|+|I|))\) と高々、User(Item)数の1次、埋め込み層の次元の2次でスケールします。
Mult-VAE
この論文では、最新の深層機械学習のモデルとの例として、Mult-VAE を簡単に紹介します。Autoencoder は入力 \(x\) を Encoder で圧縮 \(z\)、それをDecoder で解凍し入力を再現させる機械学習のモデルです。Variational Autoencoder では、単純に圧縮するのではなく、 K次元の潜在表現 \(z \in R^K\) に圧縮、その確率分布から入力 \( x\) を復元するというモデルです。Mult-VAE では、潜在表現 \( z_u \) を Gaussian prior で sampling し、non-linear function \(f_\theta(\cdot) \in R^I\) で、item のクリックされた履歴を表現します。$$z_u \in \mathcal{N}(0, I_K), \quad \pi(z_u) \propto \exp\{f_\theta(z_u)\}, \quad x_u \sim \mathrm{Mult}(N_u, \pi(z_u))$$
ここで、total click 数 \(N_u = \sum_{i} x_{ui}\) で、multinomial distribution で \(x_u\) が sampling されることがこのモデルの名前の由来となっています。学習では、KL divergence の項の強さを調整するパラメータ\(\beta\)を追加して、以下の目的関数を利用します。
$$\mathcal{L}_\beta(x_u;\theta,\phi) \equiv \mathbf{E}_{q_\phi(z_u|x_u)}\left[ \log p_\theta(x_u|z_u) – \beta \cdot \mathrm{KL}(q_\phi(z_u|x_u)||p(z_u))\right]$$
Autoencoder, (入力に Noise を加えることで改良した) Denoising Autoencoder、そして、Variational Autoencoder の概念図は以下となります。Variational Autoencoder では、入力を元に潜在変数 \( z \) の分布を特徴づけるパラメータを推定、それを元に入力を生成します。最近、話題となっている Diffusion model などでもこの種の VAE 構造は重要な要素となっています。
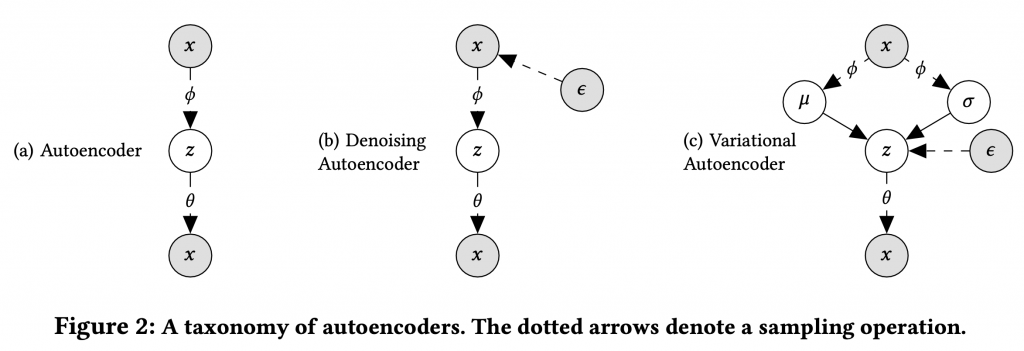
なお、Mult-VAE を改良した RecVAE という新しいモデルもありますが、RecVAE もこの論文では iALS との比較しています。
EASE
推薦システムの機械学習アルゴリズムとして、深いニューラル・ネット・ワークではなく、逆に浅い構造であっても実は高い性能を発揮するモデルが知られています。EASEは、Embarrassingly Shallow Autoencoders for Sparse Dataという論文で提唱されたモデルで、タイトルの通り、非常に浅い Autoencoder を利用したモデルです。
どのくらい浅いのかというと、この Autoencoder の構造は以下の通り、1層のみという潔すぎるぐらいシンプルです。
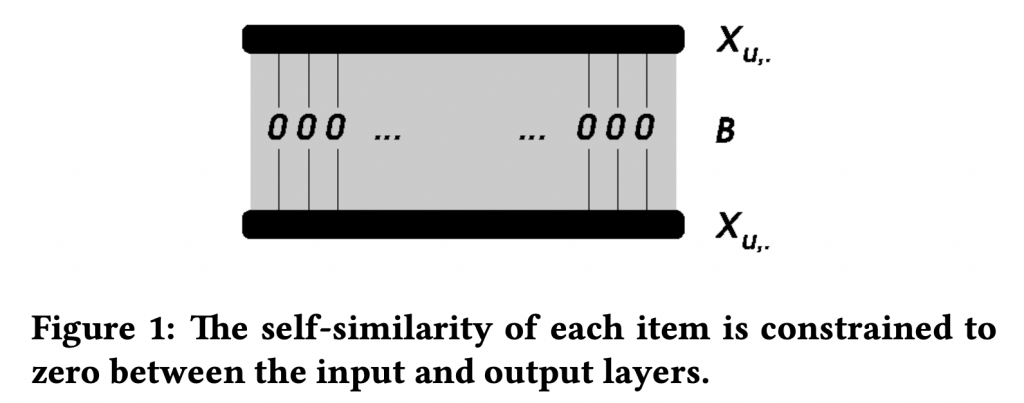
もともと、SLIM (Sparse Linear Methods with Side Information for Top-N Recommendations) という類似のモデルがあり、それの改良版(損失関数と学習方法を変更)がこの EASE になっています。(この名前は、Embarrassingly Shallow AutoEncoders の大文字を逆にして EASE \(^\mathrm{R} \) だそうです。)
ユーザーとアイテムの組み合わせ \( X \in \mathbf{R}^{|U| \times |I|}\). EASE が学習するのはアイテム x アイテムの重みに関する行列 \( B \in \mathbf{R}^{|I| \times |I|}\) です。
そして、この行列は元のフィードバックを近似的に再現するように学習します。
$$XB \rightarrow X$$
予測は以下の様に、単純な行列の積のみととても単純です。
$$S_{uj} = X_{u,\cdot} \cdot B_{\cdot,j}$$
といっても、最初の式から分かるように、そりゃ単位行列を入れればいいでしょ、となってしまうので、実際の損失関数は正則項(第2項)と条件付きで学習します。
$$\min_{B} ||X – XB||_F^2 + \lambda \cdot ||B||_F^2$$
s.t.
$$\mathrm{diag}(B) = 0$$
ここで、\( ||\cdots ||_\mathrm{F}^2\) は、 Frobenius norm です。こんな単純なモデルで良いのかと疑問に思うかと思いますが、MovieLens 20M, Netflix, Million Song Data についての、各種評価指標で、上で紹介した Mult-VAE を凌駕するパフォーマンスを発揮することが報告されています。
結果
今回の論文で利用するコードや実行方法は Reproducing iALS benchmark results で、公開されております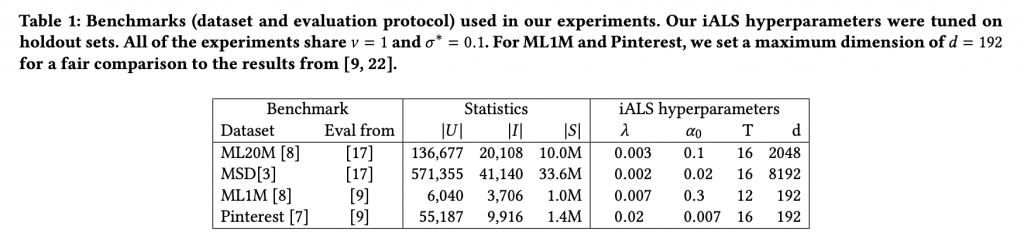
まずは、各種のデータセット(MovieLens 20M(ML20M), Million Song Data(MSD), MovieLens 1M(ML1M), Pinterest)に対しての iALS のハイパーパラメータです。特徴としては、今回の実験では、埋め込み次元 \( d \) を2048や8192と非常に深いものまで探索して利用しております。なお、\(T\)は学習の epoch 数です。
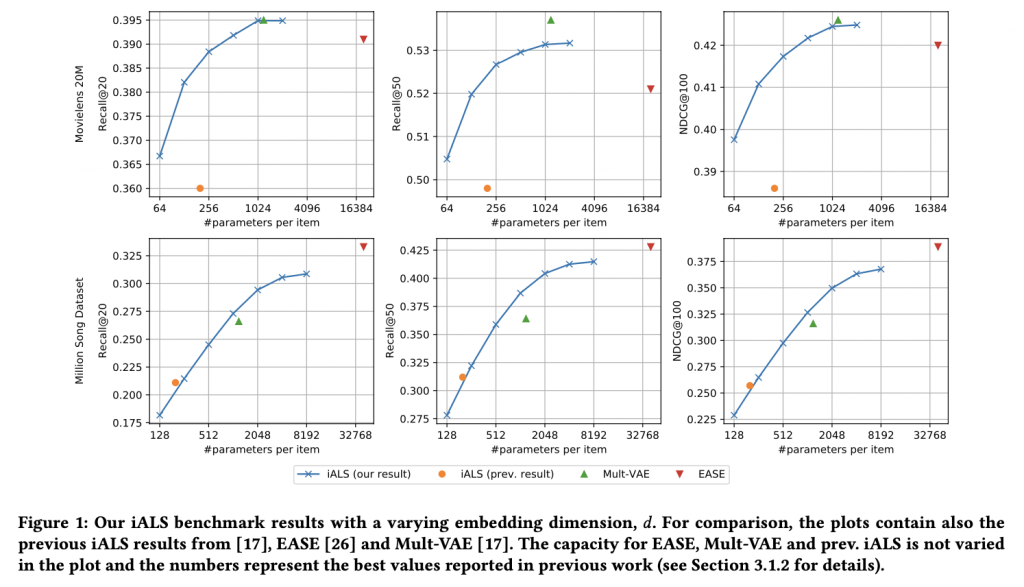
さて、具体的な性能比較に写ります。上図は比較対象のモデル(Mult-VAE, EASE)と過去のベンチマークの iALS と、今回検証した \( d \) を徐々に大きくした場合の iALS(青線)の評価指標(Reacall@20, Recall@50, NDCG@100) を比べた結果です。埋め込み層の次元 \( d \)を増やすほど、iALS の各種評価指標がどんどん改善されていきます。従来の benchmark で利用されていた iALS の次元はあまり大きくなく、性能が十分ではありませんでしたが、十分に次元を増やしていくと新しいモデル(Mult-VAE, EASE)と同等、あるいはそれ以上の性能を発揮していることがわかります。
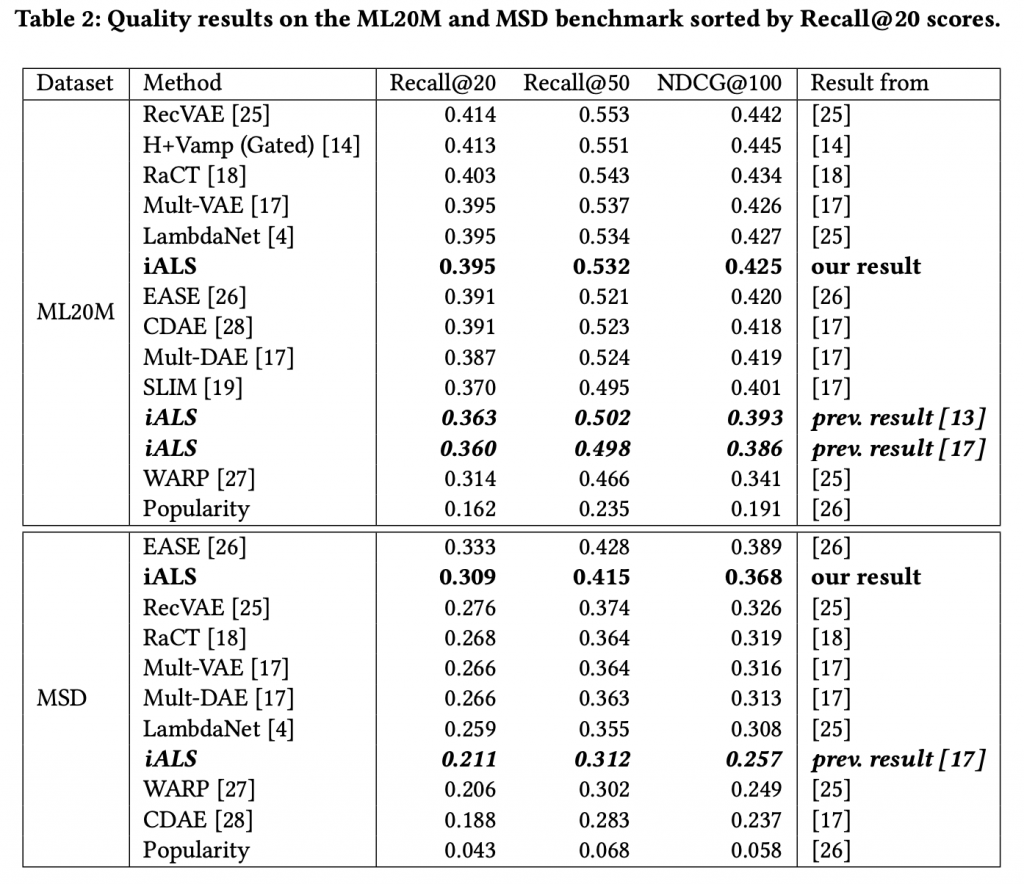
他の各種モデルと比較をまとめたものがこの表です。ご覧になって分かるようにiALSを適切に調整すると、最新のモデルと比較しても同等以上の性能を発揮しています。
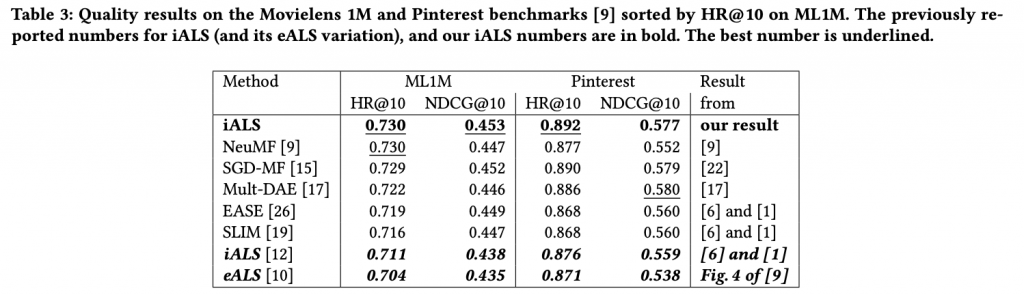
別のベンチマークの比較結果でも、今回の論文で適切にパラメータを調整した iALS は他のモデル以上の性能を発揮しております。
まとめ
さて、今回は推薦モデルで昔から利用されている iALS について、十分なチューニングがあれば、最新の複雑なモデルに匹敵する性能を持つことを示した論文を紹介しました。iALS は収束が早く、計算効率が良いため大規模データであっても十分にスケールできるなどの他のモデルにはない様々な利点を持っております。新しいモデルは確かに興味深いですが、温故知新と言いましょうか、このように昔から使われている手法も正しく判断して利用することも大事なのかと思います。実際、ビジネスの現場では、様々な制約から高速で安定な成熟した技術が求められることもあり、徒らに最新の技術に執着するには要注意かと思います。グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。皆さんのご応募をお待ちしています。
参考資料
- Revisiting the Performance of iALS on item Recommendation Benchmarks
- Collaborative Filtering for Implicit Feedback Datasets
- Variational Autoencoders for Collaborative Filtering
- RecVAE: A New Variational Autoencoder for Top-N Recommendations with Implicit Feedback
- Embarrassingly Shallow Autoencoders for Sparse Dat
- SLIM
- Item Recommendation from Implicit Feedback
- Reproducing iALS benchmark results
- 推薦システムにおいて線形モデルがまだまだ有用な話
- iALSによる行列分解の知られざる真の実力




