Hortonworks DataFlow (HDF) に含まれている NiFi を使って vmstat の結果を Hive Streaming で Hive テーブルに入れる話
こんにちは。次世代システム研究室で Hadoop 周辺をよく触っている T.O. です。
Hadoop 周辺をよく触っているので、最近 Hadoop 周辺を触ってきて得た話などを書いていきます。
今回のタイトルは「Hortonworks DataFlow (HDF) に含まれている NiFi を使って vmstat の結果を Hive Streaming で Hive テーブルに入れる話」です。まずはこのタイトルに含まれる語について見ていきましょう。
Hortonworks DataFlow (HDF) とは
まずは Hortonworks DataFlow (HDF) です。これは、Hortonworks DataFlow (HDF) を見ると、HDF makes streaming analytics faster and easier, by enabling accelerated data collection, curation, analysis and delivery in real-time, on-premises or in the cloud through an integrated solution with Apache NiFi, Kafka and Storm.
と書かれています。平たく言えば「 NiFi と Kafka と Storm をパッケージしたもの」と言えるものです。が、 NiFi と Kafka と Storm を必ず組み合わせて使わなければならない、というわけではなく、それぞれ単独で使うこともできます。データを集める、という点ではこれら 3 コンポーネントは代表的になってきているので、まとめて HDF というパッケージにしているのだろうと捉えています。
先ほど書いたとおり、 3 コンポーネントすべて使うような構成にしなくて良いわけで、今回は NiFi だけを使って、「 vmstat の結果を Hive Streaming で Hive テーブルに入れる」を実現していきます。
なお、今回は現時点で最新のバージョン 2.0.1 を使っています。
NiFi とは
では、その NiFi とはどのようなツールなのでしょうか。 Apache NiFi には、Apache NiFi supports powerful and scalable directed graphs of data routing, transformation, and system mediation logic.
とあります。「データフローオーケストレーションソフトウェア」とも呼ばれていますが、データの流れをコントロールするツールです。また、サブプロジェクトの MiNiFi と組み合わせることでいわゆる IoT 分野でのデータ収集で使われることも多いようです。 NiFi では、そのデータの流れをコントロールするための設定を WebUI で提供されるグラフィカルなツールで操作することができる、というところが優れており、これがとても便利です。どのぐらい便利なのか、は Apache NiFi Screencasts にある動画をご覧いただくとわかると思います。下に埋め込んだのはこのページに書かれている “NiFi User Interface Overview” です。4分程度の動画ですが、 NiFi による操作とその便利さがおおよそ理解できると思います。
それでは次に NiFi の構成要素を見ていきましょう。 NiFi の構成要素については、 そのデータフロー NiFiで楽にしてあげましょうの 19 ページ目で端的にまとめられていますが、ここでも少し書いておきます。まず、 FlowFile(Flow File, flow file と表記されることもある)というものがあります。 FlowFile は、 NiFi によるデータフローにおいて流れていくデータの塊のことです。これが Processor に入力されたり、出力されたりします。Processor とは、このとおり、 FlowFile を生成したり、何か処理をしたり、出力したりするものです。また Processor はつなげていくことができます。 Processor と Processor をつなげているエッジを Relationship と呼びます。 Relationship のソースとなる Processor はその処理の成否などによって出力先の口を複数持っていることがあり、処理結果次第で異なる Processor に渡す、ということもできます。 NiFi では、これらの要素を適切に組み合わせて、データの生成、加工、格納などを行っていきます。
Hive Streaming とは
今回やろうとしていることでは、 vmstat の結果を最終的に Hive テーブルに入れるわけですが、その際に使う NiFi の Processor が PutHiveStreaming Processor というものであり、それが Hive Streaming と呼ばれる方法を使っています。 Hive Streaming については、 Hive – Streaming Data Ingest に解説があります。従来 Hive は、連続的にデータを入れていくには適していませんでしたが、これにより、ストリーミング的にデータを入れていくことが可能になりました。Hive Streaming を使うには、 Hive 側もそれに対応させた設定を施さなければなりません。具体的には Streaming Requirements に記されているとおりです。今回ももちろん、これに則り、 Hive 側の設定とテーブルの作成をすることになります。
それでは引き続き、 NiFi を使うまでの環境構築の話を見ていきましょう。やることは、基本的には以下の 3 つです。
- Ambari のセットアップ
- Ambari を使って HDF のセットアップ
- NiFi のセットアップ
Ambari の、そして Ambari を使って HDF のセットアップ
Hortonworks のプロダクトなので、管理には Ambari を使います。 Ambari のセットアップと、 Ambari を使った HDF のセットアップは、 Hortonworks が提供するドキュメントのとおりに進めれば特に問題なく完了させることができます。取り立てて難しいところはありません。ちなみに今回も、「GMOすごいエンジニア支援制度」の「サバろうぜ!」によって自由に使えているGMOアプリクラウドを利用しています。これはとても素晴らしい制度ですね。
NiFi のセットアップ
HDF のセットアップができたら、 NiFi のセットアップです・・・が、今回ぐらいの使い方では、特にデフォルトから大きくいじることもありません。素直に起動してしまえば OK です。なお今回は「とりあえず動かそう」ぐらいのノリであり、通信の暗号化はやらないため、 NiFi Certificate Authority は動かしません。 NiFi Certificate Authority を使って暗号化する手順は、 HDF のドキュメントの “Enabling SSL with a NiFi Certificate Authority” に記載されています。さらにやっておかなければならないこと
本来ならばここまでの準備だけで問題ないはずなのですが、どうやらこのままだと目的を完遂できないらしいことが、 Hortonworks Community Connection (HCC) に投稿された下記の質問とその回答からわかります。PutHiveStreaming Nifi processor; various errors
この質問では、 PutHiveStreaming を試しているがうまくいかないぞ、ということを投げていますが、それのベストアンサーには、
The issue for Hive Streaming between HDF 2.0 and HDP 2.5 is captured as NIFI-2828 (albeit under a different title, it is the same cause and fix). In the meantime as a possible workaround I have built a Hive NAR that you can try if you wish, just save off your other one (from the lib/ folder with a version like 1.0.0.2.0.0-159 or something) and replace it with this one.
とあり、つまり、ライブラリを手動で置き換えないとダメ、ということがわかります。ということで、この作業もあわせて行っておく必要があります。
ここまでで環境は整いました。それでは、本題の「NiFi を使って vmstat の結果を Hive Streaming で Hive テーブルに入れる」に取り掛かりましょう。
「NiFi を使って vmstat の結果を Hive Streaming で Hive テーブルに入れる」の実現方法
ということで、本題の「NiFi を使って vmstat の結果を Hive Streaming で Hive テーブルに入れる」の実現方法をご紹介します。NiFi によるデータフローは下のスクリーンショットのとおりで、 ExecuteProcess → ExecuteStreamCommand → InferAvroSchema → ConvertCSVToAvro → PutHiveStreaming という流れになっており 5 種類の Processor を 1 回ずつ使っています。それぞれの工程について少し掘り下げてみていきましょう。
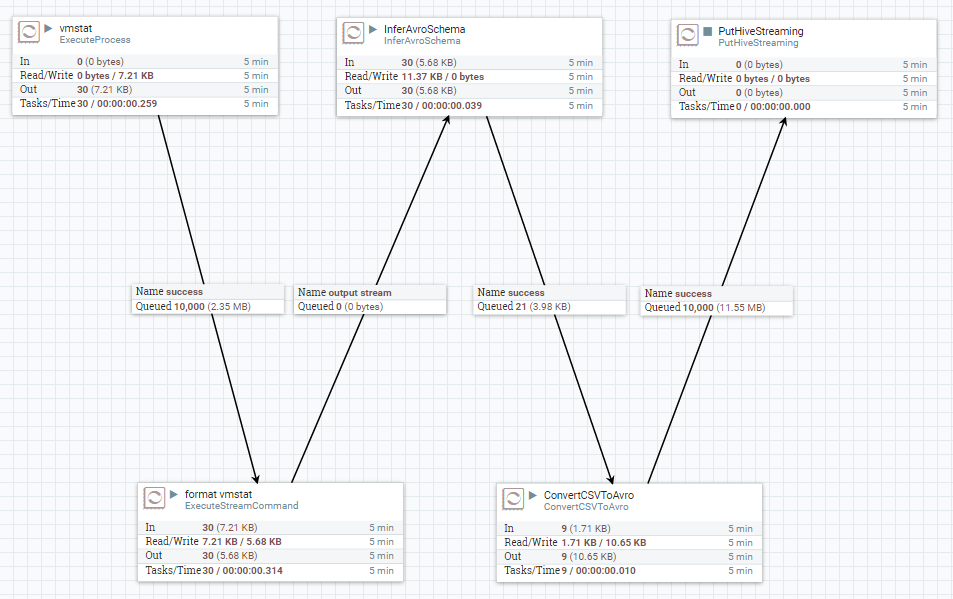
ExecuteProcess
ExecuteProcess は、Runs an operating system command specified by the user and writes the output of that command to a FlowFile.
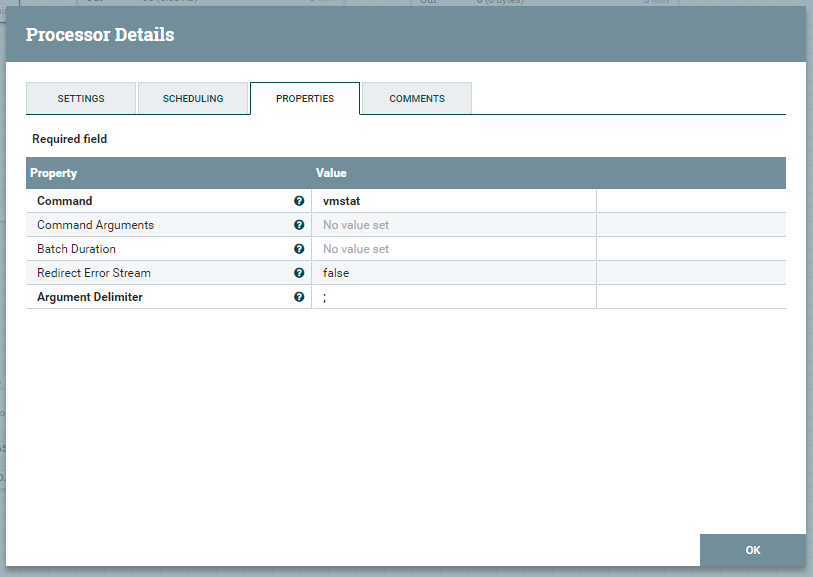
とあるとおり、任意のコマンドを実行してその出力を FlowFile として次に渡す Processor です。まずはこれを使って vmstat を実行します。あくまでこの NiFi が動いているホストで、 vmstat も実行されることになります。設定は下のスクリーンショットのようにしています。
ExecuteStreamCommand
ExecuteStreamCommand は、Executes an external command on the contents of a flow file, and creates a new flow file with the results of the command.
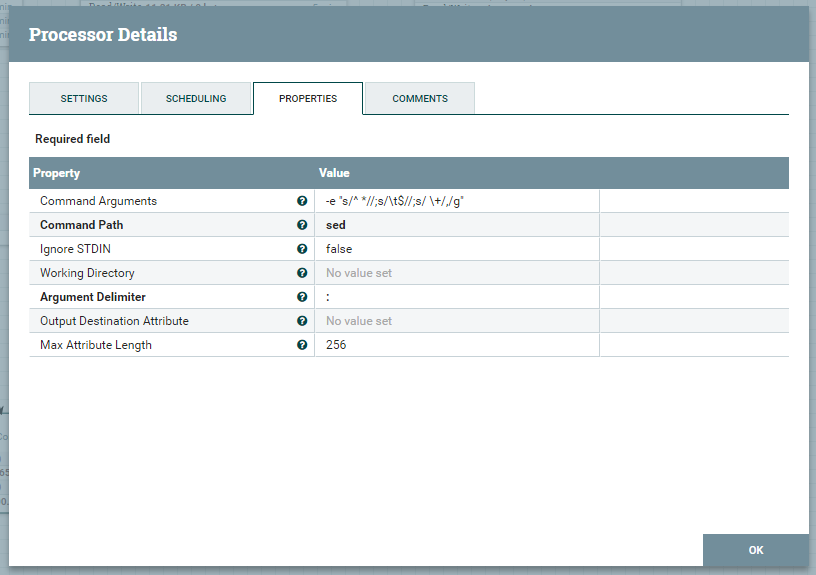
とあり、平たく言えば、 Unix 系 OS におけるパイプを挟んでコマンドを実行、というようなものです。今回のケースでは、前工程の vmstat の結果を sed で加工し、後工程の準備をしています。具体的には、 Command Arguments に -e "s/^ *//;s/\t$//;s/ \+/,/g" を指定し、出力のトリミングし、項目のデリミタをスペースからカンマに置き換えています。なお、 Argument Delimiter プロパティを : (コロン)にしていますが、これは、 Command Arguments プロパティで ; (セミコロン)を使っているため、 ; 以外を指定する必要があったためです。設定のスクリーンショットも貼っておきます。
InferAvroSchema
InferAvroSchema は、Examines the contents of the incoming FlowFile to infer an Avro schema.
というものです。入力の FlowFile から、 Avro スキーマを推測し生成してくれます。これを適切に実行するために、前工程での加工が必要だったわけです。設定は…
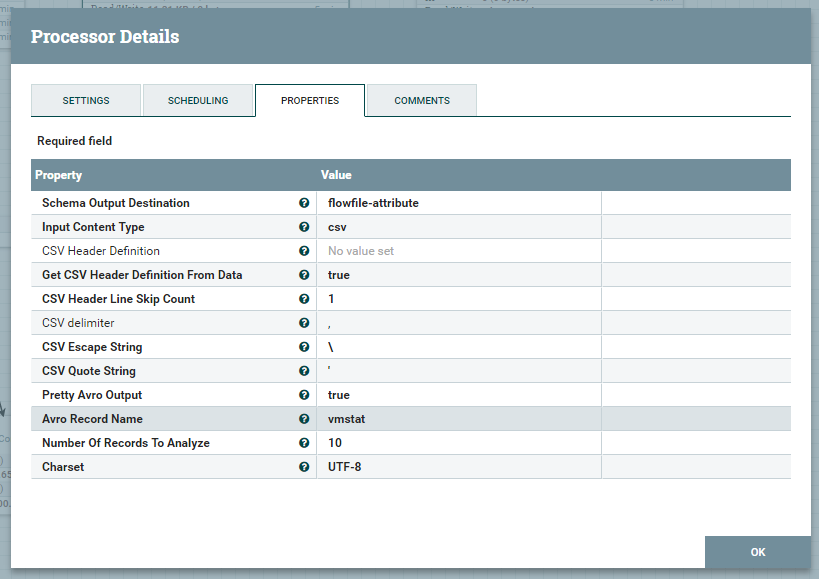
このようにしていますが、この Processor は今回のケースではキモになるモノですので、少し文字数を割いて説明していきます。
Schema Output Destination プロパティ
生成したスキーマ情報をどこに出力するか、という設定です。今回のケースでは flowfile-attribute を指定しています。これにより、 FlowFile の中身そのものではなく、属性としてスキーマ情報を次の Processor に渡すことができます。これを次に控える ConvertCSVToAvro が使うことになります。 flowfile-content という選択肢もありますが、これを選ぶと出力する FlowFile の本体がスキーマ情報になってしまい、前工程から受け取った vmstat の出力を加工したデータが消えてしまいます。Input Content Type プロパティ
今回は CSV なのでcsv を選びます。他に json, use mime.type value を選ぶこともできます。CSV Header Definition プロパティ
入力の FlowFile が CSV の場合で、かつ、そこから列の定義を読み取るのではなく、手動で与えたい場合は、ここで定義します。今回は自動的に決めるので、空にしてあります。Get CSV Header Definition From Data プロパティ
入力の FlowFile から CSV のヘッダ定義、つまり各列の名前を取り出すか、というプロパティです。今回は true にしています。CSV Header Line Skip Count プロパティ
入力の FlowFile の先頭何行をスキップするか、というプロパティです。今回のケースの入力は vmstat の出力ですが、 vmstat はヘッダ的な行が 2 行あり、列名として使いたいのはその 2 行目だけなので、 1 行目をスキップすべく 1 に設定しています。Avro Record Name プロパティ
今回のケースでは、後続の Processor で使うこともないため、任意の文字列で OK 。ConvertCSVToAvro
ConvertCSVToAvro は、Converts CSV files to Avro according to an Avro Schema
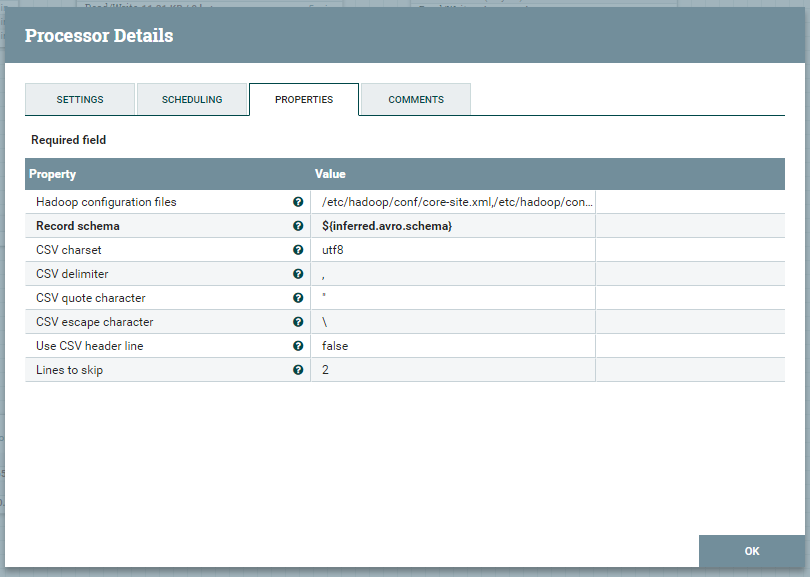
という働きをします。その名の通りです。 InferAvroSchema を使って取り出した Avro スキーマ情報を使って CSV にした vmstat の結果を Avro に変換します。Record schema プロパティで ${inferred.avro.schema} を指定していますが、これにより、前段にいる InferAvroSchema により取り出せたスキーマ情報を使うことができます。
PutHiveStreaming
PutHiveStreaming は、This processor uses Hive Streaming to send flow file data to an Apache Hive table.
というものです。 Avro に変換したデータを Hive テーブルに Hive Streaming で入れていくために使います。今回のケースではこのような設定にしています。
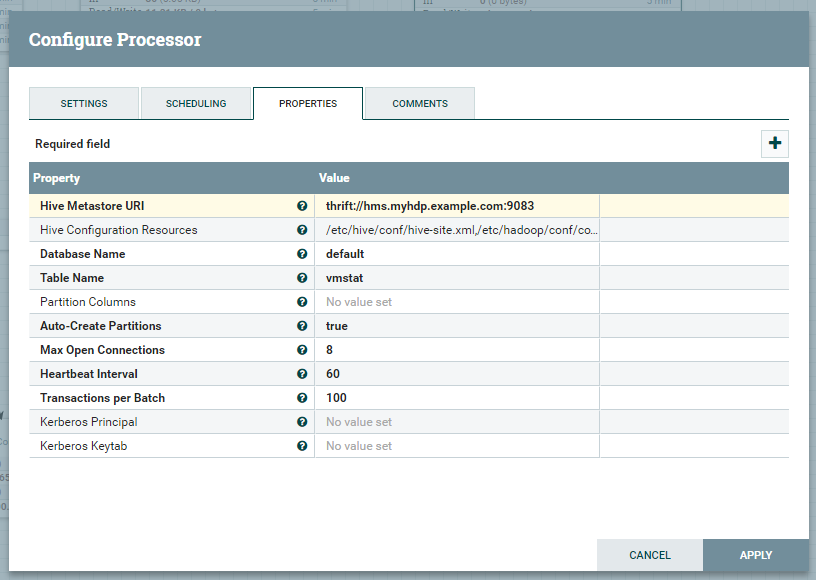
Database Name, Table Name で、 Avro として流れてきた FlowFile の中身を入れる先のテーブルが決まるわけですが、このテーブルはさすがに自動ではつくってくれないので、あらかじめつくっておく必要があります。 Hive Streaming に対応できるテーブルの設定については、前述の Streaming Requirements に記述されており、それに従えば OK で、今回は vmstat の出力の内容を考え、以下のクエリでテーブルをつくっています。 clustered by で他のカラムを差し置いて r を選んでいること自体には特に理由はなく、ただ BucketedTables にするためにそうしています。
create table vmstat (
r int,
b int,
swpd int,
free int,
buff int,
cache int,
si int,
so int,
bi int,
bo int,
`in` int, -- in だけは予約語なので、バッククォートで囲む必要があった。
cs int,
us int,
sy int,
id int,
wa int,
st int
)
clustered by (r) into 5 buckets
stored as orc
tblproperties('transactional'='true');
なお、 Processor の設定に誤りがあった場合などは、下のスクリーンショットのように、 Processor の右上に赤いアイコンが現れ、そこにマウスカーソルを合わせると、エラーメッセージを確認することができます。
こうして設定を終え、エラーも出ずに実行できれば無事に、 NiFi が動いているホストで実行した vmstat の結果が、 Hive テーブルに入ります!
まとめ
Hortonworks DataFlow (HDF) に含まれる NiFi を使って、 vmstat の結果を Hive テーブルに格納してみました。ライブラリの入れ替えをしないとダメ、という落とし穴はありましたが、概ね大きくつまづくこともなく実現できました。グラフィカルなインターフェイスでデータの流れを定義できる、というのはとても便利でしたね。また、元々、このブログのネタ探しの段階では、今回結果的に使っている Hive Streaming そのものについて調べていこうかとも思っていましたが、 NiFi を使えば Hive Streaming によるデータ書き出しも簡単に出来てしまうこともわかりました。こういう本来ならめんどくさい部分を NiFi の組み込みの Processor が担ってくれているのはとても便利ですね。そして、 NiFi には、今回使った 5 つの Processor 以外にも組み込みの Processor は大量にあり、 Apache NiFi Documentation で確認できます。これらをうまく組み合わせれば、プログラミングすることなく、様々な目的に即したデータフローをつくりあげることができそうです。また、組み込みの Processor ではどうにもならないときには、自分で実装すればよく、 NiFi Developer’s Guide を読めばなんとかなりそうです。
最後に
次世代システム研究室では、 GMO インターネットグループ各社の先鋭的なシステム構築をリードできる技術を持ったエンジニアを募集しています。ご興味のある方は、ぜひ 募集職種一覧 からご応募をお願いします!